Poly Kernel Inception Network在遥感检测中的应用
摘要https://export.arxiv.org/pdf/2403.06258遥感图像(RSI)中的目标检测经常面临一些日益严重的挑战,包括目标尺度的巨大变化和多样的上下文环境。先前的方法试图通过扩大骨干网络的空间感受野来解决这些挑战,要么通过大核卷积,要么通过空洞卷积。然而,前者通常会引入大量的背景噪声,而后者则可能生成过于稀疏的特征表示。在本文中,我们引入了Poly Kernel Ince
摘要
https://export.arxiv.org/pdf/2403.06258
遥感图像(RSI)中的目标检测经常面临一些日益严重的挑战,包括目标尺度的巨大变化和多样的上下文环境。先前的方法试图通过扩大骨干网络的空间感受野来解决这些挑战,要么通过大核卷积,要么通过空洞卷积。然而,前者通常会引入大量的背景噪声,而后者则可能生成过于稀疏的特征表示。在本文中,我们引入了Poly Kernel Inception Network(PKINet)来处理上述挑战。PKINet采用无空洞的多尺度卷积核来提取不同尺度的目标特征并捕获局部上下文。此外,我们还并行引入了一个Context Anchor Attention(CAA)模块来捕获长距离上下文信息。这两个组件共同作用,提高了PKINet在四个具有挑战性的遥感检测基准上的性能,即DOTA-v1.0、DOTA-v1.5、HRSC2016和DIOR-R。

1、简介
遥感图像(RSI)中的目标检测近年来引起了广泛关注[11, 56, 64]。这项任务致力于在RSI中识别特定目标的存在,并随后确定它们的类别和精确位置。与通常产生水平边界框的通用目标检测不同,遥感目标检测旨在生成与目标方向准确对齐的边界框。因此,先前的许多努力都致力于开发各种有向边界框(OBB)检测器[10, 20, 31, 65, 67, 71],并改进OBB的角度预测精度[68,70,72-74]。然而,在改善用于目标检测的特征提取方面,RSI的独特特性仍相对缺乏深入研究。
RSI,包括航空和卫星图像,通常是从鸟瞰视角获取的,提供了地球表面的高分辨率视图。因此,RSI中描绘的目标展现出广泛的尺度变化,从足球场等大型目标到车辆等相对较小的目标。此外,这些目标的准确识别不仅依赖于它们的外观,还依赖于上下文信息,即它们所处的周围环境。为了应对目标尺度的巨大变化,一些方法采用显式的数据增强技术[2,54,82]来提高特征对尺度变化的鲁棒性。有些方法则采用多尺度特征集成[37, 81]或金字塔特征层次结构[33,61]来提取富含尺度信息的特征。然而,这些方法的一个局限性是,不同尺度目标的感受野保持不变,因此无法为较大目标提供足够的上下文信息。
最近,LSKNet[32]提出通过结合大核卷积[12, 18, 38, 43]和空洞卷积来选择性地扩大较大目标的空间感受野,以捕获更多的场景上下文信息。然而,值得注意的是,使用大核卷积可能会引入大量的背景噪声,这可能对小型目标的准确检测产生不利影响。另一方面,尽管空洞卷积在扩大感受野方面有效,但可能会无意中忽略该区域内的细粒度细节,从而导致特征表示过于稀疏。
为了应对RSI中目标尺度的巨大变化和多样化的上下文环境所带来的挑战,本文提出了一种强大且轻量级的特征提取骨干网络——Poly Kernel Inception Network(PKINet),用于遥感目标检测。与以前依赖大核或空洞卷积来扩展感受野的方法不同,PKINet并行地排列了多个不同大小的无空洞的深度卷积核,并在不同的感受野中提取密集的纹理特征。这些纹理特征沿通道维度自适应地融合,从而收集局部上下文信息。为了进一步包含长距离的上下文信息,我们引入了Context Anchor Attention(CAA)机制,它利用全局平均池化和一维条状卷积来捕获远距离像素之间的关系,并增强中心区域内的特征。这两个组件共同工作,促进具有局部和全局上下文信息的自适应特征的提取,从而提高遥感目标检测的性能。
据我们所知,PKINet是首个在遥感目标检测中探索使用Inception风格的卷积和全局上下文注意力机制的开创性工作,旨在有效应对目标尺度变化和上下文多样性带来的挑战。我们在广泛使用的遥感基准数据集DOTA-v1.0[64]、DOTA-v1.5[64]、HRSC2016[41]和DIOR-R[3]上进行了大量实验,验证了我们的方法的有效性。除了卓越的特征提取能力外,由于战略性地使用了深度卷积和1D卷积,我们的模型相比之前的方法更加轻量。这些优势使得PKINet在遥感目标检测任务中更具实际应用价值。
2、相关工作
遥感目标检测面临的挑战主要源于目标具有任意方向和显著的尺度变化[3,11,40,56,64,75]。以往的大多数方法主要关注定向边界框(Oriented Bounding Box,OBB)检测。然而,一个新兴的趋势是设计针对遥感图像(Remote Sensing Images,RSIs)特性的有效特征提取骨干网络。
遥感目标检测的OBB方法。为了应对遥感图像中目标任意方向带来的挑战,一个研究方向是开发专门的OBB检测器。这包括在检测器颈部引入特征细化技术[69,71],提取旋转的感兴趣区域(Rotated Region of Interest,RoI)[10, 65],以及为OBB设计特定的检测头[21, 26, 48]等。
虽然这些方法相较于通用的水平边界框(HBB)检测器有所改进,但它们常常因为将水平对象表示与额外的角度参数相结合而获得相对不灵活的对象表示,而面临边界不连续等问题。为了缓解上述问题,另一方面的研究致力于开发新的对象表示方法以检测OBB[15, 31, 62, 67, 70, 76]。例如,Xu等人[67]提出通过向经典HBB表示添加四个滑动偏移变量来描述多方向对象。Li等人[31]使用一组点来表征有向对象,以实现更准确的方向估计。还有一些方法[4, 27, 72, 73]利用高斯分布来建模OBB进行目标检测,并设计新的损失函数[51]来指导学习过程。
尽管这些方法在解决与任意方向相关的挑战方面颇具前景,但它们通常依赖于标准的骨干网络进行特征提取,这往往忽略了遥感图像(RSIs)中对于目标检测至关重要的独特特性,例如目标尺度的巨大变化和多样化的上下文信息。相比之下,我们提出了一种特征提取骨干网络,专门用于应对由目标尺度巨大变化所带来的挑战。
遥感目标检测的特征提取。为了更好地处理遥感图像中独特的挑战,如目标尺度的巨大变化,一些方法强调通过诸如数据增强[2, 54, 82]、多尺度特征融合[39, 61, 81, 83]、特征金字塔网络(FPN)增强[16, 25, 35, 80]或多尺度锚框生成[19, 24, 52]等方法来提取多尺度特征。最近,专为遥感目标检测设计的特征提取骨干网络取得了显著进展。一些方法[21, 50]专注于提取适合不同方向对象且具有相同感受野的特征。还有一些方法[32]通过使用大核[12, 38, 43]来扩大较大对象的空间感受野,但这不可避免地会为较小对象引入背景噪声。还有一些方法[8, 17, 79]采用多尺度卷积核来解决不同领域的挑战,但遥感检测领域的研究仍然相对匮乏。
类似于[32],我们提出了一种新的特征提取骨干网络PKINet,以解决遥感图像(RSIs)中目标尺度巨大变化和多样化上下文信息所带来的挑战。这两种方法之间存在两个关键差异。首先,PKINet不依赖于大核或扩张卷积来扩大感受野,而是采用无扩张的Inception风格深度卷积来提取不同感受野下的多尺度纹理特征。其次,我们的方法融入了上下文锚点注意力(CAA)机制,以捕获长距离的上下文信息。这两个组件协同工作,有助于提取具有局部和全局上下文信息的自适应特征,从而提升遥感目标检测的性能。
3、方法论
如图2(a)所示,我们的PKINet是一个类似于VGG[55]和ResNet[22]的特征提取骨干网络,它由四个阶段组成。每个阶段(§3.1)都采用了跨阶段部分(CSP)结构[60],其中阶段的输入被分割并输入到两条路径中。一条路径是简单的前馈网络(FFN)。另一条路径则包含一系列PKI块,每个PKI块都由一个PKI模块(§3.2)和一个CAA模块(§3.3)组成。这两条路径的输出被拼接在一起,形成该阶段的输出。PKINet可以与各种定向目标检测器(如Oriented RCNN[65])结合使用,以产生RSIs的最终目标检测结果。

3.1、PKI阶段
在PKINet中,四个阶段按顺序排列。第
l
l
l阶段的输入和输出分别是
F
l
−
1
∈
R
C
l
−
1
×
H
l
−
1
×
W
l
−
1
\boldsymbol{F}_{l-1} \in \mathbb{R}^{C_{l-1} \times H_{l-1} \times W_{l-1}}
Fl−1∈RCl−1×Hl−1×Wl−1和
F
l
∈
R
C
l
×
H
l
×
W
l
\boldsymbol{F}_{l} \in \mathbb{R}^{C_{l} \times H_{l} \times W_{l}}
Fl∈RCl×Hl×Wl。第
l
l
l阶段的结构如图2(b)所示,它采用了跨阶段部分(CSP)结构[60]。具体来说,经过初始处理后的阶段输入
F
l
−
1
\boldsymbol{F}_{l-1}
Fl−1在通道维度上被分割成两部分,并分别输入到两条路径中。
X
l
−
1
=
Conv
3
×
3
(
D
S
(
F
l
−
1
)
)
∈
R
C
l
×
H
l
×
W
l
,
X
l
−
1
(
1
)
=
X
l
−
1
[
:
1
2
C
l
,
…
]
,
X
l
−
1
(
2
)
=
X
l
−
1
[
1
2
C
l
:
,
…
]
(1)
\begin{array}{c} \boldsymbol{X}_{l-1}=\operatorname{Conv}_{3 \times 3}\left(\mathrm{DS}\left(\boldsymbol{F}_{l-1}\right)\right) \in \mathbb{R}^{C_{l} \times H_{l} \times W_{l}}, \\ \boldsymbol{X}_{l-1}^{(1)}=\boldsymbol{X}_{l-1}\left[: \frac{1}{2} C_{l}, \ldots\right], \boldsymbol{X}_{l-1}^{(2)}=\boldsymbol{X}_{l-1}\left[\frac{1}{2} C_{l}:, \ldots\right] \end{array} \tag{1}
Xl−1=Conv3×3(DS(Fl−1))∈RCl×Hl×Wl,Xl−1(1)=Xl−1[:21Cl,…],Xl−1(2)=Xl−1[21Cl:,…](1)
DS表示下采样操作。一条路径是一个简单的前馈网络(FFN),它接收
X
l
−
1
(
1
)
∈
R
1
2
C
l
×
H
l
×
W
l
\boldsymbol{X}_{l-1}^{(1)} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}}
Xl−1(1)∈R21Cl×Hl×Wl作为输入,并输出
X
l
(
1
)
∈
R
1
2
C
l
×
H
l
×
W
l
\boldsymbol{X}_{l}^{(1)} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}}
Xl(1)∈R21Cl×Hl×Wl。另一条路径包含
N
l
N_{l}
Nl个PKI块,这些块处理
X
l
−
1
(
2
)
∈
R
1
2
C
l
×
H
l
×
W
l
\boldsymbol{X}_{l-1}^{(2)} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}}
Xl−1(2)∈R21Cl×Hl×Wl并输出
X
l
(
2
)
∈
R
1
2
C
l
×
H
l
×
W
l
\boldsymbol{X}_{l}^{(2)} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}}
Xl(2)∈R21Cl×Hl×Wl。如图2©所示,PKI块包含一个PKI模块和一个CAA模块,这两个模块将分别在第3.2节和第3.3节中详细介绍。第
l
l
l阶段的最终输出是:
F
l
=
Conv
1
×
1
(
Concat
(
X
l
(
1
)
,
X
l
(
2
)
)
)
∈
R
C
l
×
H
l
×
W
l
,
(2)
\boldsymbol{F}_{l}=\operatorname{Conv}_{1 \times 1}\left(\operatorname{Concat}\left(\boldsymbol{X}_{l}^{(1)}, \boldsymbol{X}_{l}^{(2)}\right)\right) \in \mathbb{R}^{C_{l} \times H_{l} \times W_{l}}, \tag{2}
Fl=Conv1×1(Concat(Xl(1),Xl(2)))∈RCl×Hl×Wl,(2)
其中Concat指的是连接操作。
3.2、PKI模块
PKINet块由PKI模块和CAA模块组成。在本节中,我们将详细探讨PKI模块的内容。CAA模块将在第3.3节中介绍。
正如第1节所述,与一般的目标检测不同,遥感目标检测旨在在单个图像内定位和识别不同大小的对象。为了应对目标尺度变化大所带来的挑战,我们引入了PKI模块来捕获多尺度纹理特征。如图2(d)所示,PKI模块是一种Inception风格的模块[57, 77],它首先通过一个小核卷积来捕获局部信息,然后利用一系列并行的深度卷积来跨多个尺度捕获上下文信息。正式地,第
l
l
l阶段中第
n
n
n个PKI块内的PKI模块可以数学地表示如下:
L
l
−
1
,
n
=
Conv
k
s
×
k
s
(
X
l
−
1
,
n
(
2
)
)
,
n
=
0
,
…
,
N
l
−
1
,
Z
l
−
1
,
n
(
m
)
=
DWConv
k
(
m
)
×
k
(
m
)
(
L
l
−
1
,
n
)
,
m
=
1
,
…
,
4.
(3)
\begin{array}{l} \boldsymbol{L}_{l-1, n}=\operatorname{Conv}_{k_{s} \times k_{s}}\left(\boldsymbol{X}_{l-1, n}^{(2)}\right), n=0, \ldots, N_{l}-1, \\ \boldsymbol{Z}_{l-1, n}^{(m)}=\operatorname{DWConv}_{k^{(m)} \times k^{(m)}}\left(\boldsymbol{L}_{l-1, n}\right), m=1, \ldots, 4 . \end{array} \tag{3}
Ll−1,n=Convks×ks(Xl−1,n(2)),n=0,…,Nl−1,Zl−1,n(m)=DWConvk(m)×k(m)(Ll−1,n),m=1,…,4.(3)
在这里, L l − 1 , n ∈ R 1 2 C l × H l × W l \boldsymbol{L}_{l-1, n} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}} Ll−1,n∈R21Cl×Hl×Wl是通过 k s × k s k_{s} \times k_{s} ks×ks卷积提取的局部特征,而 Z l − 1 , n ( m ) ∈ R 1 2 C l × H l × W l \boldsymbol{Z}_{l-1, n}^{(m)} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}} Zl−1,n(m)∈R21Cl×Hl×Wl是由第 m m m个 k ( m ) × k ( m ) k^{(m)} \times k^{(m)} k(m)×k(m)深度卷积(DWConv)提取的上下文特征。在我们的实验中,我们设置 k s = 3 k_{s}=3 ks=3和 k ( m ) = ( m + 1 ) × 2 + 1 k^{(m)}=(m+1) \times 2+1 k(m)=(m+1)×2+1。对于 n = 0 n=0 n=0,我们有 X l − 1 , n ( 2 ) = X l − 1 ( 2 ) \boldsymbol{X}_{l-1, n}^{(2)}=\boldsymbol{X}_{l-1}^{(2)} Xl−1,n(2)=Xl−1(2)。请注意,我们的PKI模块不使用扩张卷积,从而避免了提取过于稀疏的特征表示。
然后,通过大小为 1 × 1 1 \times 1 1×1的卷积来融合局部和上下文特征,表征不同通道之间的相互关系:
P l − 1 , n = Conv 1 × 1 ( L l − 1 , n + ∑ m = 1 4 Z l − 1 , n ( m ) ) (4) \boldsymbol{P}_{l-1, n}=\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{L}_{l-1, n}+\sum_{m=1}^{4} \boldsymbol{Z}_{l-1, n}^{(m)}\right) \tag{4} Pl−1,n=Conv1×1(Ll−1,n+m=1∑4Zl−1,n(m))(4)
其中, P l − 1 , n ∈ R 1 2 C l × H l × W l \boldsymbol{P}_{l-1, n} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}} Pl−1,n∈R21Cl×Hl×Wl表示输出特征。 1 × 1 1 \times 1 1×1卷积作为通道融合机制,用于整合具有不同感受野大小的特征。通过这种方式,我们的PKI模块可以在不损害局部纹理特征完整性的情况下捕获广泛的上下文信息。
3.3、上下文锚点注意力(CAA)
如上所述,PKI块中的Inception风格的PKI模块专注于提取多尺度的局部上下文信息。为了捕获长距离的上下文信息,我们受到[32, 58]的启发,进一步在PKI块中集成了上下文锚点注意力(CAA)模块。CAA旨在把握远距离像素之间的上下文相互依赖性,同时增强中心特征。CAA的示意图如图2(e)所示。以第 l l l阶段中第 n n n个PKI块内的CAA模块为例,我们采用平均池化后接一个 1 × 1 1 \times 1 1×1卷积来获取局部区域特征:
F l − 1 , n pool = Conv 1 × 1 ( P a v g ( X l − 1 , n ( 2 ) ) ) , n = 0 , … , N l − 1 (5) \boldsymbol{F}_{l-1, n}^{\text {pool }}=\operatorname{Conv}_{1 \times 1}\left(\mathcal{P}_{avg}\left(\boldsymbol{X}_{l-1, n}^{(2)}\right)\right), \quad n=0, \ldots, N_{l}-1 \tag{5} Fl−1,npool =Conv1×1(Pavg(Xl−1,n(2))),n=0,…,Nl−1(5)
其中, P avg \mathcal{P}_{\text {avg }} Pavg 表示平均池化操作。对于 n = 0 n=0 n=0,我们有 X l − 1 , n ( 2 ) = X l − 1 ( 2 ) \boldsymbol{X}_{l-1, n}^{(2)}=\boldsymbol{X}_{l-1}^{(2)} Xl−1,n(2)=Xl−1(2)。然后,我们使用两个深度可分离卷积作为标准大核深度卷积的近似:
F l − 1 , n w = DWConv 1 × k b ( F l − 1 , n pool ) , F l − 1 , n h = DWConv k b × 1 ( F l − 1 , n w ) . (6) \begin{array}{l} \boldsymbol{F}_{l-1, n}^{\mathrm{w}}=\operatorname{DWConv}_{1 \times k_{b}}\left(\boldsymbol{F}_{l-1, n}^{\text {pool }}\right), \\ \boldsymbol{F}_{l-1, n}^{\mathrm{h}}=\operatorname{DWConv}_{k_{b} \times 1}\left(\boldsymbol{F}_{l-1, n}^{\mathrm{w}}\right) . \end{array}\tag{6} Fl−1,nw=DWConv1×kb(Fl−1,npool ),Fl−1,nh=DWConvkb×1(Fl−1,nw).(6)
这里, DWConv 1 × k b \operatorname{DWConv}_{1 \times k_{b}} DWConv1×kb和 DWConv k b × 1 \operatorname{DWConv}_{k_{b} \times 1} DWConvkb×1分别表示宽度为 1 × k b 1 \times k_{b} 1×kb和高度为 k b × 1 k_{b} \times 1 kb×1的深度可分离卷积,用于捕获长距离的上下文信息。这些卷积操作能够生成包含上下文信息的特征图,然后我们将这些特征图与原始特征进行融合,以捕获不同尺度的上下文信息。通过这种方式,CAA模块能够增强模型对远距离依赖性的建模能力,从而提升遥感目标检测的性能。
我们选择深度可分离卷积主要是基于两个主要考虑因素。首先,深度可分离是轻量级的。与传统的 k b × k b k_{b} \times k_{b} kb×kb二维深度卷积相比,我们可以使用一对一维深度卷积核达到类似的效果,同时参数减少了 k b / 2 k_{b}/2 kb/2。其次,深度可分离有助于识别和提取细长形状物体(如桥梁)的特征。随着PKI块不断加深,为了增加CAA模块的感受野,我们设置 k b = 11 + 2 × l k_{b}=11+2 \times l kb=11+2×l,即根据PKI块的深度 l l l来计算核大小 k b k_{b} kb。这种设计增强了PKINet建立长距离像素之间关系的能力,并且由于剥离卷积的设计,不会显著增加计算成本。
最后,我们的CAA模块生成一个注意力权重 A l − 1 , n ∈ R 1 2 C l × H l × W l \boldsymbol{A}_{l-1, n} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}} Al−1,n∈R21Cl×Hl×Wl,该权重进一步用于增强PKI模块的输出(参见式(4)):
A l − 1 , n = Sigmoid ( Conv 1 × 1 ( F l − 1 , n h ) ) , F l − 1 , n attn = ( A l − 1 , n ⊙ P l − 1 , n ) ⊕ P l − 1 , n . (7) \begin{aligned} \boldsymbol{A}_{l-1, n} & =\operatorname{Sigmoid}\left(\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{l-1, n}^{\mathrm{h}}\right)\right), \\ \boldsymbol{F}_{l-1, n}^{\text {attn }} & =\left(\boldsymbol{A}_{l-1, n} \odot \boldsymbol{P}_{l-1, n}\right) \oplus \boldsymbol{P}_{l-1, n} . \end{aligned}\tag{7} Al−1,nFl−1,nattn =Sigmoid(Conv1×1(Fl−1,nh)),=(Al−1,n⊙Pl−1,n)⊕Pl−1,n.(7)
这里,Sigmoid函数确保注意力图 A l − 1 , n \boldsymbol{A}_{l-1, n} Al−1,n的值在 ( 0 , 1 ) (0,1) (0,1)范围内, ⊙ \odot ⊙表示逐元素乘法, ⊕ \oplus ⊕表示逐元素加法,而 F l − 1 , n attn ∈ R 1 2 C l × H l × W l \boldsymbol{F}_{l-1, n}^{\text {attn }} \in \mathbb{R}^{\frac{1}{2} C_{l} \times H_{l} \times W_{l}} Fl−1,nattn ∈R21Cl×Hl×Wl是增强后的特征。第 l l l阶段中第 n n n个PKI块的输出是通过以下方式获得的:
X l , n ( 2 ) = Conv 1 × 1 ( F l − 1 , n attn ) . (8) \boldsymbol{X}_{l, n}^{(2)}=\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{l-1, n}^{\text {attn }}\right) . \tag{8} Xl,n(2)=Conv1×1(Fl−1,nattn ).(8)
对于 n = N l − 1 n=N_{l}-1 n=Nl−1 的情况,我们有 X l ( 2 ) = X l , n ( 2 ) \boldsymbol{X}_{l}^{(2)}=\boldsymbol{X}_{l, n}^{(2)} Xl(2)=Xl,n(2),即我们将最后一个PKI块的输出表示为 X l ( 2 ) \boldsymbol{X}_{l}^{(2)} Xl(2)。
3.4、实现细节
在本文中,我们提出了两种PKINet骨干网络的变体,即PKINet-T和PKINet-S,其中“T”代表“Tiny”,而“S”代表“Small”。Stem结构包含三个3x3的卷积层,它们的步长分别为(2,1,1)。对于PKINet-T和PKINet-S,我们设置 H l = H / 2 ( l + 1 ) H_{l}=H / 2^{(l+1)} Hl=H/2(l+1), W l = W / 2 ( l + 1 ) W_{l}=W / 2^{(l+1)} Wl=W/2(l+1),其中 l = 0 , … , 4 l=0, \ldots, 4 l=0,…,4,并且 H , W H, W H,W分别表示输入的高度和宽度。
对于PKINet-T,我们设置
C
0
=
32
C_{0}=32
C0=32,以及
C
l
=
2
l
−
1
×
C
0
C_{l}=2^{l-1} \times C_{0}
Cl=2l−1×C0,其中
l
=
1
,
…
,
4
l=1, \ldots, 4
l=1,…,4。四个阶段中的PKI块数量分别为(4,14,22,4)。对于PKINet-S,我们设置
C
0
=
64
C_{0}=64
C0=64,以及
C
l
=
2
l
−
1
×
C
0
C_{l}=2^{l-1} \times C_{0}
Cl=2l−1×C0,其中
l
=
1
,
…
,
4
l=1, \ldots, 4
l=1,…,4。四个阶段中的PKI块数量分别为(4,12,20,4)。需要注意的是,尽管PKINet-T相比PKINet-S包含更多的PKI块,但由于中间特征通道数减半,它包含的参数显著减少。PKINet两种变体的详细配置列于表1中。

4、实验
4.1、实验设置
数据集。我们在四个流行的遥感目标检测数据集上进行了广泛的实验:
- DOTA-v1.0 [64] 是一个用于遥感检测的大规模数据集,包含2806张图像、188,282个实例和15个类别,具有多种方向和尺度。该数据集分为训练集、验证集和测试集,分别包含1,411,458张、937张和(此处原文似乎缺失了测试集的具体数量)图像。
- DOTA-v1.5 [64] 是基于DOTA-v1.0的一个更具挑战性的数据集,发布于2019年DOAI挑战赛。这个版本增加了一个新的类别名为Container Crane (CC),并且显著增加了小于10像素的微小实例的数量,总计包含403,318个实例。
- HRSC2016 [41] 是一个用于船舶检测的遥感数据集,包含1061张航空图像,尺寸范围从300x300到1500x900。图像被分为训练集、验证集和测试集,分别包含436张、181张和444张图像。
- DIOR-R [3] 是在遥感数据集DIOR [30]的基础上提供OBB(Oriented Bounding Box,有向边界框)标注的数据集。它包含23,463张尺寸为800x800的图像和192,518个标注。
训练过程。我们的训练过程包括ImageNet [9] 预训练和遥感目标检测器训练。对于ImageNet预训练,我们在ImageNet-1K数据集上使用MMPretrain [6] 工具箱对PKINet进行训练。在主实验中,为了获得更高的性能,我们像之前的工作 [32, 50, 65, 71] 一样,训练了300个周期。在预训练过程中,我们使用AdamW [29] 优化器,动量设置为0.9,权重衰减为0.05。采用余弦退火策略 [45] 和预热策略来调整学习率。我们使用8块GPU,批处理大小为1024来进行预训练。
对于遥感目标检测器训练,我们在MMRotate [84] 框架上进行实验。为了与其他方法进行比较,我们使用这些基准的trainval集进行训练,并使用它们的测试集进行测试。遵循之前方法 [21, 65, 71, 78] 的设置,我们将DOTA-v1.0和DOTA-v1.5数据集的原始图像裁剪成大小为1024x1024的块,重叠部分为200像素。对于HRSC2016和DIOR-R数据集,输入大小设置为800x800。对于DOTA-v1.0、DOTA-v1.5、HRSC2016和DIOR-R,模型分别训练30个周期、30个周期、60个周期和36个周期。我们使用AdamW [29] 优化器,权重衰减为0.05,初始学习率设置为0.0002。所有报告的浮点运算次数(FLOPs)都是在输入图像大小为1024x1024时计算的。为了防止过拟合,我们按照之前的方法 [21, 65, 71, 78] 对图像进行随机缩放和翻转。对于HRSC2016和DIOR-R,我们报告了五次运行的平均精度均值(mAP)。
测试阶段。测试阶段的图像分辨率与训练阶段保持一致。为了保证公平性,我们在测试时未使用任何数据增强技术。
评估指标。我们报告了平均精度均值(mAP)和在0.5阈值下的平均精度(AP50)。可重复性。我们的算法是在PyTorch中实现的。我们使用八块NVIDIA RTX 4090 GPU进行ImageNet预训练,四块NVIDIA Tesla V100 GPU进行下游任务的训练和测试。为了保证我们算法的可重复性,我们的实现可以在PKINet上找到。

4.2、定量结果
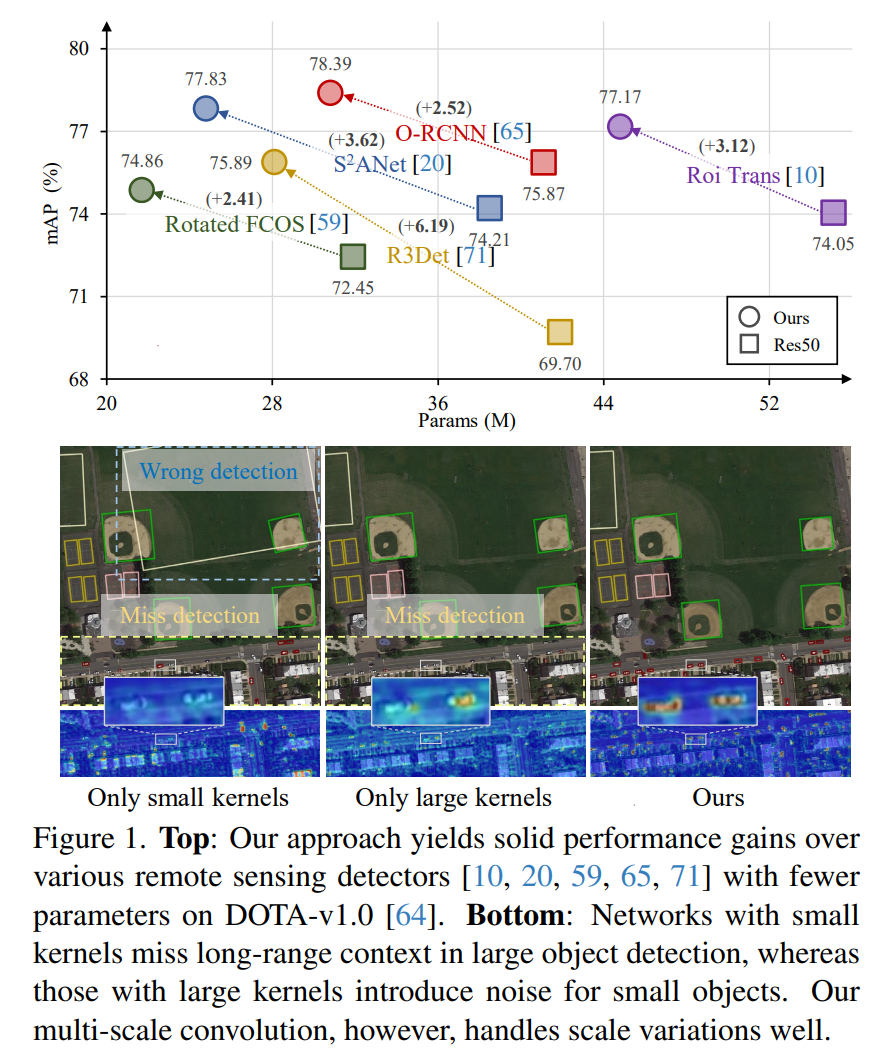
在DOTA-v1.0数据集上的性能 [64]。首先,我们在表3中将PKINet与在Oriented RCNN [65]框架内构建的ResNet [22]在DOTA-v1.0数据集上进行比较。PKINetT仅使用ResNet-18所需参数的36.7%和计算量的59.6%,性能就提高了3.67%。PKINet-S同样表现出色,仅使用ResNet-50的58.8%的参数和81.53%的计算量,性能就提升了2.52%。

当我们的PKINet骨干网络与表2中显示的多个检测架构结合时,它始终优于ResNet-50以及更多为遥感检测任务设计的网络(即ARC [50]和LSKNet [32])。对于单阶段架构,我们的骨干网络能够为Rotated FCOS [59]、R3Det [71]和S²ANet [20]分别带来2.41%/6.19%/3.71%的mAP提升,相比于ResNet-50。即使与经典的S²ANet [20]结合,我们的方法也超越了先前的方法,达到了77.83%的性能。对于两阶段架构,PKINet也实现了显著的提升(3.12%/3.28%/2.23%)。当配备先进的检测器Oriented RCNN [65]时,性能达到了优越的78.39%,与先前的最佳方法LSKNet [32]相比,在小类别上的性能提升尤为显著(SV/LV分别为5.3%/5.76%)。对于需要更多上下文信息的RA类别,PKINet相比LSKNet也实现了6.46%的提升。

在DOTA-v1.5数据集上的性能 [64]。如表4所示,我们的方法在更具挑战性的DOTA-v1.5数据集上实现了出色的性能,特别是对小目标,这证明了其有效性和对小目标的泛化能力。我们的PKINet超越了先前最先进的方法,性能提升了1.21%。

在HRSC2016数据集上的性能 [41]。如表5所示,我们的PKINet-S在HRSC2016数据集上超越了12种领先的方法,并且使用的参数更少。相较于LSKNet [32]的微弱优势主要源于HRSC2016将31个子类合并为单一的“船”类别进行训练和测试。这种协议并没有充分展示我们方法在处理类间对象尺寸变化方面的优势。
在DIOR-R数据集上的性能 [3]。我们在表6中展示了在DIOR-R上的比较结果。我们取得了最佳性能,达到了67.03%。
在COCO 2017数据集上的性能 [34]。为了评估PKINet作为一个通用框架,对各种形式的边界框的适应性,我们在广泛使用的通用检测基准COCO上评估了我们的方法。如表7所示,PKINet在参数相似的情况下优于几种著名的骨干网络,从而进一步证实了我们方法作为通用骨干网络的有效性,并不局限于遥感影像。

4.3、定性结果
图3展示了在DOTA [64]数据集上的代表性可视化结果。如图所见,与先前表现最佳的方法LSKNet [32]相比,该方法仅依赖大内核,我们的PKINet展示出了强大的适应能力,能够应对场景中目标对象尺寸的显著变化。它确保了大型物体(如PL、TC、ST和BD)的检测,同时保持了对小型物体(如SV和LV)的关注。

4.4、诊断实验
为了更深入地了解PKINet,我们在DOTA-v1.0数据集上进行了一系列消融研究,采用Oriented RCNN [65]作为检测器。为了提高效率,本节中提到的所有骨干网络都在ImageNet-1K [9]上进行了100个epoch的预训练。
多尺度内核设计。首先,我们在表8a中研究了PKINet中的关键多尺度内核设计(参见第3.2节)。结果表明,仅使用小尺寸的3×3内核由于纹理信息提取有限,性能较差。然后,我们采用了一种多尺度内核结构,其内核大小从3×3到11×11不等,步长为2。在这种设置下,模型表现出最佳性能。接下来,我们测试了当内核大小增加时步长为4的情况,其性能略逊一筹。进一步尝试仅使用大内核导致计算量增加但性能下降,分别下降了0.49%和0.84%,这表明大内核可能会引入背景噪声并导致性能下降(参见第1节)。
接下来,我们研究了多尺度内核设计中的内核数量,具体细节见第3.2节。如表8b所示,仅使用两个内核(仅保留3×3和5×5内核)时,网络无法捕获长距离像素关系。随着内核数量的增加,网络性能得到提升,使用五个内核时达到最佳效果。
内核膨胀率。然后,我们检查了PKI模块中膨胀率的影响(参见第3.2节)。如表8d所示,尽管与没有内核膨胀相比,感受野增加了,但性能却下降了1.09%。随着我们进一步增加膨胀率,性能进一步下降。这证明仅通过应用膨胀来扩展感受野是行不通的。
上下文锚点注意力。接下来,我们证明了CAA模块(参见第3.3节)的有效性。首先,我们在表8f中应用不同内核大小的CAA来检查其影响。第一列中的三个内核大小代表平均池化和两个条形卷积中的大小。可以看出,较小的内核无法捕获长距离依赖关系,导致性能下降,而较大的内核通过包含更多上下文信息来改善这一点。我们采用的扩展内核大小策略随着块的加深而增加条形卷积的内核大小,从而实现了最佳性能。

之后,由于我们的PKINet有四个阶段,因此实施位置如何影响最终性能是一个值得研究的问题。如表8c所示,CAA模块(参见第3.3节)在任何阶段实施时都能带来性能提升。因此,当在所有阶段都部署CAA模块时,性能提升达到了1.03%。
跨阶段部分结构。表8e进一步探讨了跨阶段部分(CSP)结构的影响。消除CSP会导致参数和计算成本呈指数级增长(分别增加211%和159%)。将阶段块从(4,12,20,4)减少到(2,2,4,2)允许没有CSP结构的模型达到与前者相似的参数数量,但由于块数较少,导致性能次优。
4.5、分析
为了衡量模型对不同类别大小的检测敏感性,我们利用皮尔逊相关系数(PCC)来量化DOTA-v1.0中每类平均边界框面积与每类平均检测分数之间的线性相关性。
首先,我们计算第 k k k类所有标注的平均面积,记为 S k S_k Sk。所有类别的平均面积 S ˉ \bar{S} Sˉ计算为 S ˉ = 1 K ∑ k = 1 K S k \bar{S} = \frac{1}{K} \sum_{k=1}^{K} S_k Sˉ=K1∑k=1KSk,其中 K K K是类别的数量。每类平均分数 Q k Q_k Qk和所有类别的平均分数 Q ˉ \bar{Q} Qˉ的计算方式类似。
其次,我们计算类别平均面积 { S k } k = 1 K \{S_k\}_{k=1}^{K} {Sk}k=1K和类别平均分数 { Q k } k = 1 K \{Q_k\}_{k=1}^{K} {Qk}k=1K之间的协方差 D D D,计算方式为 D = 1 ( K − 1 ) ∑ k = 1 K ( S k − S ˉ ) × ( Q k − Q ˉ ) D = \frac{1}{(K-1)} \sum_{k=1}^{K} (S_k - \bar{S}) \times (Q_k - \bar{Q}) D=(K−1)1∑k=1K(Sk−Sˉ)×(Qk−Qˉ)。
最后,PCC计算为:
r = D σ S σ Q (9) r = \frac{D}{\sigma_S \sigma_Q} \tag{9} r=σSσQD(9)
其中,
σ
S
\sigma_S
σS和
σ
Q
\sigma_Q
σQ分别是类别平均面积
{
S
k
}
k
=
1
K
\{S_k\}_{k=1}^{K}
{Sk}k=1K和类别平均分数
{
Q
k
}
k
=
1
K
\{Q_k\}_{k=1}^{K}
{Qk}k=1K的标准差。PCC绝对值
∣
r
∣
|r|
∣r∣接近0表示线性相关性很小,说明模型的检测性能很少受到物体大小影响。如表9所示,我们的PKINet既达到了最高的mAP,又获得了最低的PCC绝对值
∣
r
∣
|r|
∣r∣,这表明PKINet对不同类别的大小变化最不敏感。

5、讨论与结论
在本文中,我们提出了用于遥感对象检测的Poly Kernel Inception Network(PKINet),旨在解决遥感图像中对象尺度变化和上下文多样性带来的挑战。PKINet采用不同大小的并行深度卷积核,以有效地捕获不同尺度上的密集纹理特征。此外,还引入了上下文锚点注意力机制来进一步捕获长距离的上下文信息。我们通过实验表明,PKINet在四个著名的遥感基准数据集上达到了最先进的性能。总体而言,我们希望这项工作能为未来的研究铺平道路。
局限性与未来工作。尽管PKINet-T和PKINet-S都展示了优于之前方法的检测性能,但由于计算资源的限制,我们未能将PKINet的模型容量扩展到最大潜力。关于模型可扩展性的类似研究在通用对象检测领域已经引起了广泛关注,如Swin Transformer [42]和ConvNeXt [43]所强调的。我们将把对PKINet可扩展性的进一步研究留待未来进行。
致谢。本工作得到了国家自然科学基金(No. 62102182, 62202227, 62302217, 62306292)、江苏省自然科学基金(No. BK20220934, BK20220938, BK20220936)、中国博士后科学基金(No. 2022M721626, 2022M711635)、江苏省优秀博士后人才资助计划(No. 2022ZB267)以及中央高校基本科研业务费专项资金(No. 30923010303)的资助。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)