DuckDB 为什么这么快?
在我们的第二个管道中,我们对sale表进行了两次部分扫描,第一次扫描表的前半部分,第二次扫描表的后半部分。读取一行输入,第一个值保持不变,将输入的第二个和第三个值相加的结果作为 输出中的第二个值,然后写出输出。最后,我谈到了 DuckDB 的并行模型:Morsel-Driven 并行支持跨任意数量核心的高效并行化,同时保持对多核处理的感知,从而有助于 DuckDB 的整体性能和效率。如果没有找到具
要点
- DuckDB 是一个开源 OLAP 数据库,专为管理数据分析而设计。与 SQLite 类似,它是一个可以嵌入到您的应用程序中的进程内数据库。
- 在进程内数据库中,引擎驻留在应用程序内,允许在同一内存地址空间内传输数据。这消除了通过套接字复制大量数据的需要,从而提高了性能。
- DuckDB 利用矢量化查询处理,可在 CPU 缓存内实现高效操作,并最大限度地减少函数调用开销。
- 在 DuckDB 中使用 Morsel-Driven 的并行性可以实现跨多个核心的高效并行化,同时保持对多核处理的感知。
为什么我要踏上建立新数据库的旅程?它以著名统计学家和软件开发人员 Hadley Wickham 的声明开头:
如果您的数据适合内存,那么将其放入数据库没有任何优势:只会更慢且更令人沮丧。
这种情绪对于像我这样的数据库研究人员来说是一个打击和挑战。哪些方面导致数据库缓慢且令人沮丧?第一个罪魁祸首是客户端-服务器模型。
当进行数据分析并将大量数据从应用程序移动到数据库中,或者将其从数据库提取到 R 或 Python 等分析环境中时,这个过程可能会非常缓慢。
我试图理解客户端-服务器架构模式的起源,并撰写了论文"Don’t Hold My Data Hostage – A Case For Client Protocol Redesign"。
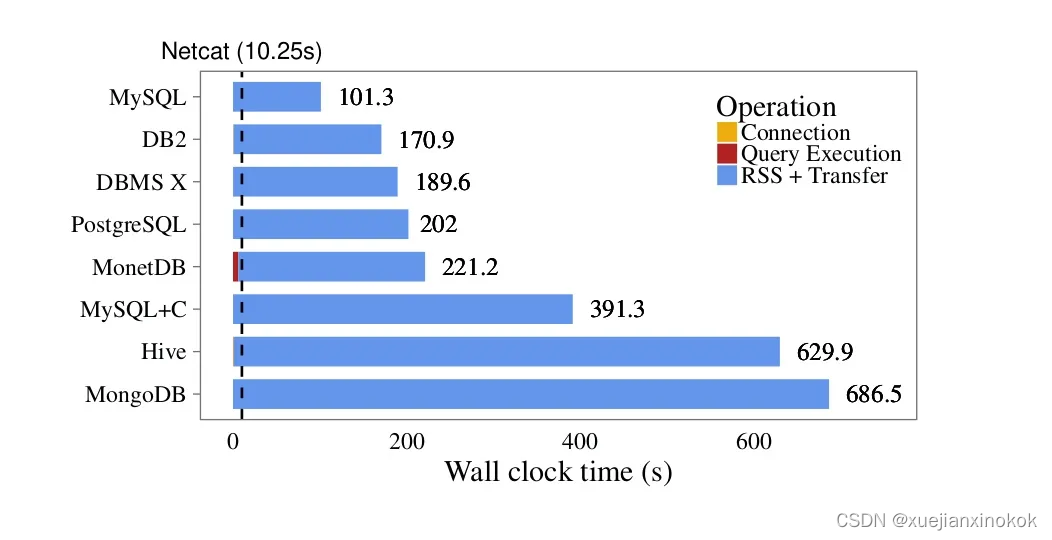
通过比较各种数据管理系统的数据库客户端协议,我计算了在客户端程序和多个数据库系统之间传输固定数据集所需的时间。
作为基准,我使用 Netcat实用程序通过网络套接字发送相同的数据集。

图1:不同客户端的比较;虚线是 netcat 传输 CSV 数据的时钟时间
与Netcat相比,使用MySQL传输相同量的数据需要花费十倍的时间,而使用Hive和MongoDB则需要一个多小时。客户端-服务器模型似乎有很大问题。
SQLite
然后我的思绪转向了 SQLite。 SQLite 拥有数十亿的副本,是世界上使用最广泛的 SQL 系统。它确实无处不在:您每天都会与数十个甚至数百个您不知道的实例打交道。
SQLite 在进程内运行,这是一种将数据库管理系统直接集成到客户端应用程序中的不同架构方法,避免了传统的客户端-服务器模型。数据可以在同一内存地址空间内传输,从而无需通过套接字复制和序列化大量数据。
然而,SQLite 并不是为大规模数据分析而设计的,其主要目的是处理事务性工作负载。
DuckDB
几年前,Mark Raasveldt 和我开始开发一个新数据库: DuckDB。 DuckDB 完全用 C++ 编写,是一个采用矢量化执行引擎的数据库管理系统。它是一个进程内数据库引擎,我们经常将其称为“用于分析的 SQLite”。该项目是在高度宽松的麻省理工学院许可下发布的,在基金会的管理下运作,而不是典型的风险投资模式。
与 DuckDB 交互是什么样的?
import duckdb
duckdb.sql('LOAD httpfs')
duckdb.sql("SELECT * FROM 'https://github.com/duckdb/duckdb/blob/master/data/parquet-testing/userdata1.parquet'").df()
在上边三行中,DuckDB 作为 Python 包导入,加载扩展以启用与 HTTPS 资源的通信,并从 URL 读取 Parquet 文件并将其转换回 Panda DataFrame (DF)。
如本示例所示,DuckDB 原生支持 Parquet 文件,我们将其视为新的 CSV。 LOAD httpfs 调用说明了如何使用插件扩展 DuckDB。
转换为 DF 中隐藏着许多复杂的工作,因为它涉及传输结果集,可能有数百万行。但由于我们在相同的地址空间中操作,因此我们可以绕过序列化或套接字传输,从而使该过程非常快。
我们还开发了一个命令行客户端,具有查询自动完成和 SQL 语法突出显示等功能。例如,我可以从我的计算机启动 DuckDB shell 并读取相同的 Parquet 文件:

考虑以下查询:
SELECT * FROM userdata.parquet;
注意到这通常不适用于传统的 SQL 系统,因为 userdata.parquet 不是表,而是文件。该表尚不存在,但 Parquet 文件存在。如果没有找到具有特定名称的表,我们会搜索具有该名称的其他实体,例如 Parquet 文件,直接对其执行查询。
In-Process Analytics
从架构的角度来看,我们拥有一类新的数据管理系统:进程内(in-process) OLAP 数据库。
SQLite 是一个进程内系统,但它面向 OLTP(在线事务处理)。当您考虑 OLTP 的传统客户端-服务器架构时,PostgreSQL 是最常见的选择。

Figure 2: OLTP versus OLAP
在 OLAP 方面,存在多种客户端-服务器系统,其中 ClickHouse 是最受认可的开源选项。然而,在DuckDB出现之前,并没有进程内OLAP选项。
DuckDB技术视角
让我们讨论 DuckDB 的技术方面,逐步完成以下查询的处理阶段:

Figure 3: A simple select query on DuckDB
该示例用公共列 cid 连接customer 和 sale 两个表 并选择 name列和sum列。目标是计算每个客户的总收入,汇总 所有收入(revenue)并包括每笔交易的税费(tax)。
当我们运行此查询时,系统会连接两个表,根据 cid 列中的值聚合客户。然后,系统计算 revenue + tax 投影,然后按 cid 进行分组聚合,在其中计算name和最终sum。
DuckDB 通过标准阶段处理此查询:查询规划、查询优化和物理规划,查询规划阶段进一步分为所谓的管道。
例如,此查询具有三个管道,由它们以流方式定义。当我们遇到 终端算子时,流结束,该算子需要在处理之前检索整个输入。

图 4:第一条管道
第一个管道扫描 customer 表并构造一个哈希表。哈希联接分为两个阶段,在联接的一侧构建哈希表,并在另一侧进行探测。哈希表的构建需要查看连接左侧的所有数据,这意味着我们必须遍历整个 customer 表并将其全部输入到 hash join build 阶段。一旦这条管道完成,我们就转向第二条管道。

图 5:第二条管道
第二个管道更大,包含更多流算子:它可以扫描 sales 表,并查看我们之前构建的哈希表,从 customer 表中查找连接伙伴。然后,它投影 revenue + tax 列并运行聚合(一个终端算子)。最后,我们运行 group by build 阶段并完成第二个管道。

图 6:第三条管道
我们可以安排第三个也是最后一个 pipeline 来读取 GROUP BY 的结果并输出结果。这个过程相当标准,许多数据库系统都采用类似的方法来进行查询规划。
Row-at-a-time 一次一行
为了理解 DuckDB 如何处理查询,我们首先考虑通过一系列迭代器进行操作的传统 Volcano 风格的迭代器模型:每个算子 都公开一个迭代器,并有一组迭代器作为其输入。
执行首先尝试从顶部算子读取,在本例中为 GROUP BY BUILD 阶段。但是,它还无法读取任何内容,因为尚未摄取任何数据。这会触发对其子运算符投影的读取请求,该投影从其子运算符 HASH JOIN PROBE 读取。这会向下级联,直到最终到达 sale 表。

图 7:火山式迭代器模型
sale 表生成一个元组,例如 (42 、 1233 、 422 ),表示 ID、revenue和tax列。然后,该元组向上移动到 HASH JOIN PROBE ,它会查阅其构建的哈希表。例如,它知道 ID 42 对应于 ASML公司,它会生成一个新行作为连接结果,即(ASML 、 1233 、 422) 。
然后,这个新行由下一个算子(投影)处理,该算子将最后两列相加,产生一个新行: (ASML 、 1355) 。该行最终进入 GROUP BY BUILD 阶段。
这种一次元组、一次一行的方法对于许多数据库系统都很常见,例如 PostgreSQL、MySQL、Oracle、SQL Server 和 SQLite。它对于以单行为焦点的事务用例特别有效,但它在分析处理中存在一个主要缺点:由于算子和迭代器之间的不断切换,它会产生大量开销。
文献建议的一种可能的改进是 just-in-time (JIT) 编译整个管道。这一选择虽然可行,但并不是唯一的选择。
Vector-at-a-time
让我们考虑一下像投影这样的简单流 算子的操作。

图 8:投影的实现
这有一个输入行和一些伪代码: input.readRow 读取一行输入,第一个值保持不变,将输入的第二个和第三个值相加的结果 作为 输出中的第二个值 ,然后写出输出。虽然这种方法很容易实现,但由于每次读取值都要进行函数调用,因此会产生较大的性能成本。
对 row-at-a-time 模型的改进是 vector-at-a-time 模型,该模型于 2005 年在"MonetDB/X100: Hyper-Pipelining Query Execution"”中首次提出。
该模型不是一次仅处理单个值,而是处理称为向量的 短列值(short columns of values)。不是检查每行的单个值,而是一次检查每列的多个值。这种方法减少了开销,因为类型切换是对 值向量 而不是 单行值 执行的。

Figure 9: The vector-at-a-time model
vector-at-a-time 模型在列式执行和行式执行之间取得了平衡。虽然列式执行效率更高,但它可能会导致内存问题。通过将 列的大小限制在可管理的范围内,一次向量模型可以避免 JIT 编译。它还提升了缓存局部性,这对于效率至关重要。
[每个人都应该知道的延迟数字]](https://gist.github.com/jboner/2841832)说明了缓存局部性的重要性。

Figure 10: Latency Numbers Everyone Should Know
该图由 Google 的 Peter Norvig 和 Jeff Dean 提供,突出显示了 L1 缓存引用(0.5 纳秒)和主内存引用(100 纳秒)之间的差异,相差 200 倍。考虑到 L1 缓存引用的速度已经快了 200 倍。与 1990 内存引用相比,目前内存引用的速度提升只有两倍,所以让 操作适合 CPU 缓存具有显着的优势。
这就是矢量化查询处理的美妙之处。

图 11:使用矢量化查询处理进行投影的实现
让我们考虑一下我们之前讨论过的 revenue + tax 示例的相同投影算子。我们不是检索单行,而是获取 三值向量 作为输入并输出 二值向量。我们读取 一个块(列的小向量的集合)而不是单行。由于第一个向量保持不变,因此它被重新分配给输出。创建一个新的结果向量,并对 range 中从 0 到 2048 的每个单独值执行加法运算。
这种方法允许编译器自动插入特殊指令,并通过仅在向量级别解释和切换数据类型和运算符来避免函数调用开销。这是矢量化处理的核心。
Exchange-Parallelism
矢量化处理在单个 CPU 上高效还不够,还需要在多个 CPU 上表现良好。我们如何支持并行性?
Google 首席科学家 Goetz Graefe 在他的论文《Volcano - An Extensible and Parallel Query Evaluation System》中描述了交换算子(exchange operator)并行性的概念。

Figure 12: Exchange operator parallelism
在此示例中,同时读取三个分区(partitions)。应用过滤器并对值进行 预聚合,然后进行哈希处理。根据哈希值,数据被分割、进一步聚合、重新聚合,然后组合输出。通过这样做,查询的大部分部分都被有效地并行化。
例如,您可以在 Spark 执行简单查询时观察到这种方法。扫描文件后,哈希聚合会执行 partial_sum 。然后,单独的操作对数据进行分区,然后重新聚合来计算总和。然而,这在许多情况下已被证明是有问题的。
Morsel-Driven Parallelism
在 SQL 引擎中实现并行性的更现代的模型是 Morsel-Driven 并行性。与上述方法一样,输入层 扫描 (input level scans) 被分割为部分,从而产生 部分扫描。在我们的第二个管道中,我们对sale表进行了两次部分扫描,第一次扫描表的前半部分,第二次扫描表的后半部分。

Figure 13: Morsel-Driven parallelism
HASH JOIN PROBE 保持不变,因为它仍然在两个管道的同一个哈希表上进行操作。投影操作是独立的,所有这些结果都同步到 GROUP BY 运算符中,这是我们的阻塞运算符。值得注意的是,您在这里看不到 交换算子(exchange operator)。
与传统的基于交换算子的模型不同, GROUP BY 能够意识到并行化的发生,并能够有效地管理由可能发生冲突的不同线程读取组引起的争用。

Figure 14: Partitioning hash tables for parallelized merging
在 Morsel-Driven 并行性中,该过程从每个线程预聚合其值开始(阶段 1)。输入数据的单独子集或片段被构建到单独的哈希表中。
下一阶段(阶段 2)涉及分区聚合:在本地哈希表中,数据根据组键的基数进行分区,确保每个哈希表不能包含任何其他哈希表中存在的键。当所有数据都已读取并且最终确定哈希表和聚合时,我们可以从每个参与线程中选择相同的分区并安排更多线程来读取所有数据。
尽管这个过程比标准聚合哈希表更复杂,但它允许 Morsel-Driven 模型实现出色的并行性。该模型有效地构建了多个输入的聚合,避免了与exchange operator相关的问题。
简单基准
我使用示例查询进行了一个简单的基准测试,并以 ORDER BY 和 LIMIT 子句的形式稍微增加了一些复杂性。该查询从 customer 和 sale 表中选择 name 以及 revenue + tax 之和,这些表按 customer ID 连接和分组。
该实验涉及两个表:一个包含一百万个 customers,另一个包含一亿个 sales条目。这相当于约 1.4 GB 的 CSV 数据,这并不是一个异常大的数据集。

图 15:简单基准测试
DuckDB 在我的笔记本电脑上仅用了半秒就完成了查询。另一方面,在我优化配置后,PostgreSQL 花了 11 秒来完成相同的任务。使用默认设置,需要 21 秒。
虽然 DuckDB 处理查询的速度比 PostgreSQL 快大约 40 倍,但值得注意的是,这种比较并不完全公平,因为 PostgreSQL 主要是为 OLTP 工作负载设计的。
结论
本文的目标是解释 DuckDB(封装在紧凑包中的数据引擎)背后的设计、功能和基本原理。 DuckDB 作为一个直接链接到应用程序进程的库,占用空间小且无依赖性,允许开发人员轻松集成 SQL 引擎进行分析。
我强调了进程内数据库的强大之处,在于它们能够有效地将结果集传输到客户端并将数据写入数据库。
DuckDB 设计的一个重要组成部分是矢量化查询处理:该技术允许高效的缓存内操作并消除函数调用开销的负担。
最后,我谈到了 DuckDB 的并行模型:Morsel-Driven 并行支持跨任意数量核心的高效并行化,同时保持对多核处理的感知,从而有助于 DuckDB 的整体性能和效率。
原文连接:In-Process Analytical Data Management with DuckDB - InfoQ

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)