情绪识别数据集汇总心电相关and申请方法 呕心沥血之作 全网唯一 AMIGOS ASCERTAIN CLAS DECAF DREAMER MANHOB-HCI MPED SWELL CASE
针对情绪识别的任务,在学习了一定的代码知识之后,摆在面前最大的问题就是如何寻找并申请使用数据集,这里我找到了9个情绪识别相关的数据集,由于我的课题原因,所以根据一篇综述找一下目前所公开的包含心电信号的情绪识别数据集并且找一下他们申请的网站。
心电信号情绪识别数据集
针对情绪识别的任务,在学习了一定的代码知识之后,摆在面前最大的问题就是如何寻找并申请使用数据集,这里我找到了9个情绪识别相关的数据集,由于我的课题原因,所以根据一篇综述找一下目前所公开的包含心电信号的情绪识别数据集并且找一下他们申请的网站。最终我找到了9个数据集,并且获得了其中几个数据集的成功申请的经验,下文将首先铺垫一下情绪识别数据集的一些基础知识,之后会介绍申请数据集的的详细方式,以及我申请成功的数据所返回的邮件内容,以及数据集的下载,和其中一些数据的读取方式,本篇文章是我写的所有文章里的内容之最,并且我感觉是一定程度上填补了目前国内网上相当一部分申请情绪识别相关数据集教程的空白
综述: Electrocardiogram-Based Emotion Recognition Systems and Their Applications in Healthcare—A Review
这是一篇2021年的基于心电信号的情绪识别系统以及在健康领域的应用的回顾,其中介绍了目前公开的所有的心电信号相关的数据集,以及一些准确率较高的心电信号情绪识别相关的论文信息对比。
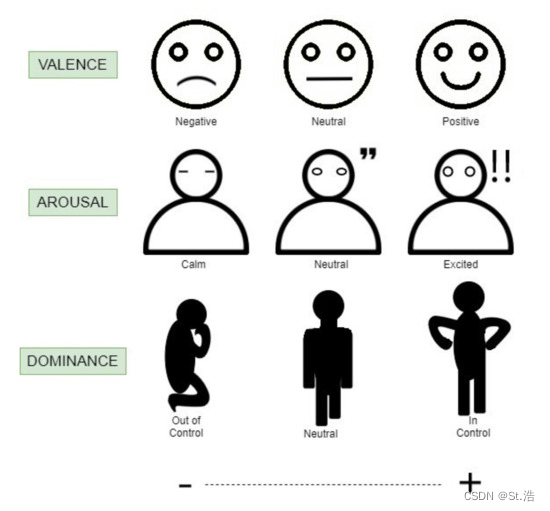
情绪评价模型(Emotion model)
首先需要了解在研究中,科研人员们评价情绪的几种方式
(1)离散情绪模型Discrete Emotional Model(DEM)
离散情绪模型是指用一个具体的情绪词汇表达当前个体的情绪状态,例如,快乐(joy),恐惧(fear),愤怒(anger),厌恶(disgust),悲伤(sad),有趣(funny),平静/自然(neutral)等,这种情绪表达模式被标准化并且在不同的语言和文化中共同分享,在这种情绪表示方式也就是情绪模型中最常见的是,幸福(happiness),悲伤(sadness),愤怒(anger),选择这三种情绪的原因是与其他更放松的情绪相比,具有更显著的唤醒水平。
(2)感情维度模型Affective Dimensional Model(ADM)
将情绪状态在两个维度,愉悦度(Valence),唤醒度(Arousal),也有研究人员加入了第三个维度,受迫度(Dominance)。在两个或者三个维度上用数字量化出当前情绪的状态。

与DEM相比,ADM的多功能性如下图所示。基于价和唤醒量表,可以根据强度程度对情绪类别进行细分。高价-高唤醒(HVHA)映射到兴奋,而高价-低唤醒(HVLA)映射到感觉平静或放松。低-高唤醒(LVHA)被认为是愤怒和痛苦,而低-低唤醒(LVLA)与悲伤和沮丧有关。刻度的中间被视为中性状态。

(3)二元情绪模型Binary Emotional Model
二元情绪模型包括积极和消极情绪状态(Pos/Neg)。该模型的目的是简单地概括哪些情绪是坏的,哪些情绪是好的。负面情绪可能会给携带者及其周围的人带来心理压力。长期暴露于负面情绪是不健康的,因为它会影响一个人的生理状态。抑郁症、焦虑和双相情感障碍是情绪和精神压力的已知影响。此外,通过将情感模型简化为两类,可以以较低的复杂度构建情感识别系统的目标应用。还可以预期训练和测试模型的更高精度。下图显示了一种二元情绪压力模型。任何被归类为负面情绪的情绪,如悲伤、愤怒、恐惧和厌恶,都是可能导致并发症的潜在压力因素。因此,二元情感模型是情感计算研究的另一个重要分类模型。

情绪激发Emotion Elicitation
在实验中,为了获得实验者的情绪需要通过一套标准的操作程序,以及选择合理的方法来诱导受试者产生目标情绪。有五种常见的激发技术,即视听、图像、音乐、回忆和情景诱导。
情绪评估Emotion Evaluation
情感评估是对收集的数据进行情感标签的填写。最常见的方法是通过第一人称视角或自我评估。通过这种方式,受试者在自我评估人体模型(SAM)上对自己的情绪进行个人标记。还有一种方法是第二人称或者第三人称视角,通过怪查受试者的面部表情和身体姿势的变化对受试者感受到情绪进行猜测。
数据集(我能找到申请方式的)
AMIGOS
AMIGOS是一个代表了个人和群体个性特征和情绪的多模式研究数据集。这些数据来自40名观看视频的受试者,每个受试者有16个样本。包括ECG、EEG和GSR的生物信号。采样频率为256 Hz。使用的心电图导联配置为右臂-左腿(RA-LL)和左臂-左脚(LA-LL)。情感注释标签来自自我评估,以及使用三维的感情维度模型的第三人称视角。
AMIGOS官网链接: http://www.eecs.qmul.ac.uk/mmv/datasets/amigos/index.html
官网界面如下点击download跳转到用于申请和下载数据的界面

点击End User License Agreement 下载EULA签署使用许可协议

然后点击红色的AMIGOS dataset request server 跳转链接

进入申请服务界面之后,提交申请信息,和签好的申请许可协议的扫描文件

虽然这是一个很好的数据集但是感觉很难申请的下来,我申请了8次前几次还给我回信,后来直接确认接受邮件的链接都不给我发了,我找了香港的同学,暂时好像是崩了。
2024.5.20信息补充
根据之前有小伙伴在评论区里的评论说申请这个数据集需要永久职位,因此需要用导师的邮箱申请,我目前是还没有申请的需求,如果想用这个数据集的小伙伴可以注意一下这块,看能不能跟老师申请一下用老师的邮箱发邮件。
ASCERTAIN
ASCERTAIN 数据集这些数据来自58名观看36段视频片段的受试者。使用的生理信号为ECG、EEG和GSR。对于ECG,采样率为256 Hz,有两种未指定的导联配置。情绪注释视角仅来自我评估,所使用的模型是在价和觉醒量表上的ADM。
ASCERTAIN 官网链接: https://ascertain-dataset.github.io/
进到官网之后点击获取数据集

点进去之后下载EULA签了之后给官方发邮件题目叫ASCERTAIN access request按照EULA里面的邮件地址和要求发


这个官方也不太喜欢搭理人
CLAS
收集了30名受试者实时的ECG、BVP、EMG和GSR(EDA)。配置设置有三个导联,采样频率1 kHz。注释是通过使用ADM进行自我评估。
CLAS IEEE dataset官网链接: https://ieee-dataport.org/open-access/database-cognitive-load-affect-and-stress-recognition/
点进去之后直接按红色箭头下载文件和文档

改数据集虽然下载方便但是很难找标签,目前我也还是没找到所以只提供了下载的方式。
DECAF
DECAF dataset官网链接: https://decaf-dataset.github.io/
这是一个使用音乐和视频两种方式刺激的的数据集,一共有30位受试人员,每个受试人员分别有40段的音乐刺激以及36段的视频刺激主界面如下。

进入了官网以后点上面的Preoeocessd Data 然后点击EULA下载

之后按照里面的要求签好对应的内容之后,然后把附件法发到蓝色的这个邮箱,最好用机构邮箱并且附上你的谷歌ID,就是等登录谷歌浏览器的邮箱账号,得自己注册一个,大陆可能不太行,然后可能还得求助美国的朋友😎。

然后呢很幸运的是这个数据集我申请下来了,记住发的时候要付上你得谷歌ID邮件里也得付上,申请协议也就是EULA上要写要做为附件一起发送,然后他会把数据集分享到你谷歌账号的Google Drive里,谷歌Drive国内也是不可以直接用的,还得求助美国的朋友😎懂得都懂。

然后点击与我共享,就可以看到官方给你分享的文件,Google Drive 就类似于国内的百度网盘

下载之后的文件如下

这两个文件里包含的是视频刺激的数据,和音乐刺激的数据

按照下图文件的路径DECAF dataset\DECAF-CLS-Features\DECAF-CLS-Features,就可以找到音乐刺激和视频刺激的标签,当然读取文件需要用Matlab

这个数据我尝试过了,数据之间关联度不是很高,我只用了心电信号,很容易出现较强的过拟合,并且使用的人也非常少,并不推荐优先选择使用。
DREAMER
这是我最喜欢的一个数据库,好申请标注也清晰,DREMAER数据集一共有23个受试者,然后每个受试者都会接受18个片段的测试,采集ECG和EEG,然后每一段有一个AMD评分。
DREAMER dataset官网链接: https://zenodo.org/record/546113#
点进主页面如下

然后滑倒底部,点击提交申请,然后你会进入一个提交界面

填好了之后就直接点发送就可以了

然后他会给你回复一个回执邮件说接受到了你的申请,应该是让你确认邮件,点进去内个长的链接然后再填一遍应该。

然后第二天顺利的话就会再发一个回执说是不是给你通过我们还要决定一下。

然后最后通过了的话会给你发一个私人链接,然后郑重警告你不允许分享给其他人。

如果你申请成功了通过你的私人链接点进去之后,你发现你的界面地下和别人就不一下了会变成一个文档和两个下载链接,并且数据形式是Matlab格式的,想把数据读出出来再用python做深度学习的话还需要点Matlab技能,这个数据集的分布也是非常清晰,并不需要过多的补充说明。

MANHOB-HCI
这是一个迷一样的数据库,包含ECG、EEG、GSR、EDA、RSP和SKT从27名受试者收集了20个样本的数据。采样率为1024Hz,并下采样至256 Hz。基于观看的情感视频,受试者用3D ADM自我报告他们的情感状态。
MANHOB-HCI dataset官网链接: https://mahnob-db.eu/hci-tagging/
这个数据集最开始要申请一个账号从官网进去之后,然后点有上角的Request account

老规矩需要签一个申请许可协议,然后把中间的信息都填上,扫描件也附件上。

然后就会给你发邮件,说已经激活了你注册的账号。然后进去登录就行了。

然后点登录

要是忘了密码酒店蓝色的内阁Forgot your pass word,然后就会给你的邮箱发一个改密码的链接,直接点进去改然后再登录就行了。

然后点这个搜索数据集,在之后就是这个数据集迷的地方了,根本找不到信号和标签在哪里,拆解起来贼麻烦我就直接放弃了,之后再说吧。

MPED
这是一个国内的数据集东南大学的一个数据集,分类标签是 AMD,采样频率是250Hz,刺激材料是小于5分钟的视频,这是唯一一个我感觉可以直接写中文申请的。然后这个申请就是在一个Git Hub 的连接了里下载 EULA,然后发邮件给他就行了。暂时人家还没回我,回了我会更新读取数据和标签。
MPED dataset申请链接: https://github.com/Tengfei000/MPED

签完之后挑一个发过去,一看这邮箱,edu后缀真是很熟悉了。

SWELL
这个数据集论文里也有叫(SWELL-KW)的加了一个后缀但是是一个东西,这些数据是从25名受试者收集的,这些受试者执行写作、展示、阅读和搜索等任务以引起压力。记录的生理信号为ECG和SC。ECG通过Mobi设备(TMSi)记录,电极以三角形配置放置在胸部。采样率为2048 Hz。评估由受试者通过标记两种情绪模型进行,即ADM和Pos/Neg。这个数据集特别大,下起来很麻烦好处是不需要写EULA就可以直接下载,最后发论文的时候记得引用人家就可以了,这是一个常用的数据集,找对比也比较容易而且读取方式也比较麻烦后面我会详细的说一下。
SWELL dataset官网链接: http://cs.ru.nl/~skoldijk/SWELL-KW/Dataset.html

往下哗啦,找到Access然后点击这蓝色的链接跳转到下载数据集的界面

2024.4.25:下面的内容对比写该博客的时候出现了变化,下面页面中的数据迁移到了其他页面,页面样式出现了变化,但是基本逻辑不变,如果适应不了的话就看文末补充部分,这里不再替换,保留之前的学习逻辑过程
点进去之后会有一些描述,作者还说因为数据太大,你可以给他发邮件,要是获得许可了的话,就把完整的几十个数据的文件传给你,下载文件点右边的这个Data file

然后这里就选择文件下载,我花了好长时间下载,而且还只是下载心电的内一部分,每次只能下载一个文件,下载速度又慢,而且只能同时下载一个文件,需要挨个点,可以说是超级麻烦了。

然后给大家节省点时间,这数据下完了标签不知道在哪找,我找了好几天才找到这个数据库的标签在哪,我在官网看了半天描述也没找到,最后把文件挨个点开,最后才发现的

点击去之后AMD三个维度的标签在这里就能看到后面还有其他的,其他的对着论文慢慢研究就能知道是啥了,主要还是使用AMD,然后这里的Valence和Arousal给了两套,一套后面有一个recoded就是记录值,然后没有recoded后缀的值是有recoded后缀的值与9的差值,比如这个有recoded Valnce后缀的值是3对应的没有recoded后缀的值是9-3就是6。做实验的时候我认为要用实际值不用记录值也就是不带recoded后缀内一排。

以ECG信号为例子,它的文件路径在这里,这里有两个文件夹,下面的文件夹里面就是生理信号采集的源文件,里面包含心电,呼吸等外体征信号,所提供的信号是S00后缀的文件是一种采集软件独有的文件格式,然后上面的文件夹就是读取信号所用的Matlab文件,想读取的话还是需要一点matlab基础,哎,既然都写到这了,那就让这块完美一些说一下这个怎么用这个文件读取信号。

首先把这俩文件下载下和信号文件放到一个文件夹下。

这个tms_read.m是一个函数文件文件就是一个解码的乱起八糟的过程,不用关注,放进去就好了。

然后这个myDoReadData.m文件也是一个函数文件,他是调用上面tms_read.m这个解码函数的函数文件,然后获得将原数据格式转换成Matlab变量的格式。

然后在在这个文件夹下再建一个新文件,注意一定要在一个文件夹,要是自己不太会整,找一个会Matlab的小伙伴帮你
然后用在这个文件夹里调用myDoReadData函数,函数后面的括号里写上要读取的源文件的名字,点击运行,它会弹出来一个进度条。

然后右边的工作区就会读取出三个变量。
[ portiHRdata, portiHeartPre, portiSkinRaw ] = myDoReadData('pp1_18-9-2012_c1.S00');

然后接下来解释着三个变量都是什么意思,先上一张官方的图。从图中可以看到一个S00后缀文件包含这8个信号,在我们用Matlab读出来的三个变量里,portiHRdata包含的是全部的8个信号,portiHeartPre存储的是用滤波等方法处理过的心电信号,portiSkinRaw里存储的应该就是原始的未经处理的肌电信号,但是做心电的话大概率还是需要用到原始的心电信号,也就是下图中的Heart_raw,从上到下也就是第六个信号,这样就需要到portiHRdata里面去找,先不要着急,在matlab的工作区里给这个结构体变量点开看一下。

点开之后发现里面记录了,频率,时间,路径,文件名称等,而里面的data记录的就是上图中的8个信号

再给这个data点开,这里面就是8个一通道的数据,在上面的文件内容示意图中可以看见心电信号对应的是第六个信号,那我们就根据这个包含关系,把心电信号单独提取出来,然后在打、截取一部分信号画个图看看是不是正确读取到了原始的心电信号。

[ portiHRdata, portiHeartPre, portiSkinRaw ] = myDoReadData('pp1_18-9-2012_c1.S00');
heart_raw = portiHRdata.data{6,1};
plot(heart_raw(1:10000))
可以发现我们的分析是正确的打印出了我们想要的信号

WESAD
WESAD数据集的刺激包括看视频和一些压力任务测试,里面的生物信号包括ECG、BVP、EDA、EMG、RSP和温度(TEMP)。采样率为700Hz。受试者使用三类Pos/Neg模型对自己的情绪进行自我注释。
WESAD dataset官网链接: https://ubicomp.eti.uni-siegen.de/home/datasets/icmi18/
如果你是新手,你想找一个数据库我就推荐你用这个,这也是我入行的第一个数据库,不需要申请,标签是情绪不是价校指标,包含多种外生理信号数据集又小,准确率又高,入行的不二之选。

直接点击这个就能下载,下载之后里面的文件是这个样子的S2-S17没有S12一共是15个实验人员的数据文件夹。

weasd_readme 文件就是数据集的描述,这里浅看一下标签的定义,0对应的是情绪之间的切换状态,1是baseline平静状态,2是stress压力状态,3是amusement愉悦状态,4是meditation静心的状态。

这里稍微有一点麻烦的就是怎么读取数据的问题,没关系这里准备了例程。
import os
import pickle
import numpy as np
class read_data_one_subject:
def __init__(self, path, subject):
self.keys = ['label', 'subject', 'signal']
self.signal_keys = ['wrist', 'chest']
self.chest_sensor_keys = ['ACC', 'ECG', 'EDA', 'EMG', 'Resp', 'Temp']
self.wrist_sensor_keys = ['ACC', 'BVP', 'EDA', 'TEMP']
os.chdir(path)
os.chdir(subject)
with open(subject + '.pkl', 'rb') as file:
data = pickle.load(file, encoding='latin1')
self.data = data
def get_labels(self):
return self.data[self.keys[0]]
def get_wrist_data(self):
signal = self.data[self.keys[2]]
wrist_data = signal[self.signal_keys[0]]
return wrist_data
def get_chest_data(self):
signal = self.data[self.keys[2]]
chest_data = signal[self.signal_keys[1]]
return chest_data
if __name__ == '__main__':
#读取S2号受试者的所有数据(记得填对路径)
data = read_data_one_subject('WESAD','S2')
#获取胸部传感器中的ECG数据
ECG_data = data.get_chest_data()['ECG']
#拉平信号
ECG_data = ECG_data.flatten()
#读取标签
label = data.get_labels()
#获取标签为1处的信号样本点的索引,按照文档也就是对应baseline情绪的信号
baseine_index = np.where(label == 1)
#将索引值带入完整信号中获取出对应标签为1也就是情绪为baseline情绪的内一部分
baseine = ECG_data[baseine_index]
通过例程就可以读取WESAD数据中你想读取的任何生理信号
CASE
CASE数据集专注于参与者在观看各种视频时所经历的实时连续情绪注释。开发了一种新颖、直观的基于操纵杆的注释界面,该界面允许同时报告效价和唤醒度,通常是独立注释的。包含有从ECG、BVP、EMG (3x)、GSR(或 EDA)、呼吸和皮肤温度传感器获得八个高质量、同步的生理记录(1000 Hz、16 位 ADC)。该数据集包含来自不同文化背景的 30 名志愿者(15 名男性,年龄 28.6 ± 4.8 岁,15 名女性,年龄 25.7 ± 3.1 岁;年龄范围 22-37 岁)。实验中,他们被要求穿宽松的衣服,而男性则被要求最好剃掉面部毛发,以方便放置传感器。所有参与者都具有英语工作能力,并以相同的方式进行交流。连接生理传感器,参与者坐在面对 42 英寸平板电视的位置(见图 1,左),通过观看视频注释从视频中产生的情感体验,实验持续约40min。其中图1的中心图显示了带有嵌入式注释界面的视频播放窗口,最右图则详细展示了标注界面,可以看到添加到效价轴和唤醒轴的自我评估模型。

此实验目的是通过视频刺激引发有趣、无聊、放松和可怕的情绪状态,选择了八个视频用于主要实验,且每个视频都有两个视频用于我们想要引发的情绪状态。此外,实验中还使用了其他三个视频,即起始视频、结束视频和交错蓝屏视频。起始视频是一段轻松的纪录片摘录,旨在展示情感视频之前让参与者平静下来,添加结束视频的目的与之相同,即作为实验结束前的“冷却”阶段,下图中为所用视频的相关信息,分别为来源、标签、视频的 ID、预期效价唤醒属性以及用于数据集的视频的持续时间。

实验所采集的信号包含有ECG、RESP、BVP、GSR、EMG_z(颧大肌)、EMG_c(皱眉肌)、EMG_t(斜方肌)、SKT八种生理信号,其中注释和生理数据的采集速率分别为 20 Hz 和 1000 Hz。
数据集中有三个以下根目录(数据、元数据、脚本):

(1)data:包含多个子文件夹,这些子文件夹被进一步细分为生理信号和注释文件夹

/raw:包含从LabVIEW获取的数据,没有任何视频ID,并且该文件夹进一步细分为注释和生理信号文件夹
/initial-保存从原始数据生成的mat文件。单个mat文件包含注释和生理数据
/interpolated-包含视频ID的插值数据,已预处理的数据,并进一步细分为生理和注释文件夹。(通过执行(3)scripts中的matlab文件生成)
由于技术限制和记录延迟,样本可能并不总是以一致的预定速率记录,因此使用标准线性插值方法进行插值获得的数据,注释的范围由[−26225 ,+26225]转换为[0.5,9.5]。生成之后的生理信号数据以及注释数据样例见下所示:


/non-interpolated-包含视频ID的非插值数据。
(2)metadata:此文件夹包含实验的其他信息。
如,关于参与者的信息,他们的顺序以及观看视频等。

(3)scripts:包含允许用户进行/验证的脚本
将原始数据转换为包含在中的已处理数据所需的步骤,插值文件夹和非插值文件夹。

数据集下载:有三种数据集样本
三种数据样本,以及储存地点,以第一个为例

Sharma, K., Castellini, C., van den Broek, E. L., Albu-Schaeffer, A. & Schwenker, F. A dataset of continuous affect annotations and physiological signals for emotion analysis. figshare.
https://doi.org/10.6084/m9.figshare.c.4260668
Sharma, K. Source Code for: CASE Dataset. GitLab,
https://gitlab.com/karan-shr/case_dataset
点引用部分对应的地址

进入此页面


直接下载

引用即可
这里我是下载的第三种数据集样本。
下面是读取此数据集的代码:
import pandas as pd
from matplotlib import pyplot as plt
# 指定CSV文件路径
csv_file_path1 = r'D:\case数据集\case_dataset-master\data\interpolated\physiological\sub_1.csv'
csv_file_path2 = r'D:\case数据集\case_dataset-master\data\interpolated\annotations\sub_1.csv'
df1 = pd.read_csv(csv_file_path1)
df2 = pd.read_csv(csv_file_path2)
ECG_data = df1['ecg'].values
valence = df2['valence'].values
arousal = df2['arousal'].values
if __name__ == '__main__':
# 读取S2号受试者的ECG数据、效价和唤醒度
print(ECG_data)
plt.plot(ECG_data)
plt.show()
# 获取S2受试者的ECG数据并绘图
print(valence)
#获取效价数据
print(arousal)
#获取唤醒度数据
结束语
这些数据集中SWELL WESAD CLAS是可以直接下载的,但是和其他的数据集一样发论文的话要引用协议中数据集发表的时候用的原文,找我的话我是可以发给别人的,但是需要申请的数据集,在第三方获得许可之前,是不能发给第三方的,因为即使发了,因为许可没有通过也是不允许用没申请下来的数据集发表论文的,所以最好还是自己申请,不然就得找一个申请下来数据集的人然后需要带他的名字,要是实在嫌麻烦,就可以直接用不用申请的数据集,如果我又申请下来了其他数据集,我会在这个文章的基础上进行更新,Dreamer,SWELL,WESAD数据库可以在我的公众号浩浩的科研笔记上购买。
本人邮箱: chenhao@smail.sut.edu.cn
2024.2.4 更新信息 补充了CASE数据集
2024.2.4 补充了CASE数据集 本部分由我的学妹 小胖今天学习了吗 提供
2024.4.25 补充信息 SWELL数据集的文件下载页面出现了变化
点进SWELL页面之后提示数据集网页进行了迁移,只需要点击给的迁移网址就可以寻找到数据集所在的新家。

可以点击Tree找到到迁移网址之前的结构页面。

这里除了样式出现了变化结构和之前相同。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 56
56 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)