CRNN介绍:用于识别图中文本的深度学习模型
在计算机视觉和机器学习的领域中,文本识别是一个重要的研究领域,它旨在从图像中检测和识别文字。CRNN(Convolutional Recurrent Neural Network,卷积递归神经网络)是这个领域内的一个代表性的框架,它融合了卷积神经网络(CNN)和递归神经网络(RNN),特别适用于对图像中的序列文本进行识别。
CRNN:用于识别图中文本的深度学习模型
CRNN介绍:用于识别图中文本的深度学习模型
在计算机视觉和机器学习的领域中,文本识别是一个重要的研究领域,它旨在从图像中检测和识别文字。CRNN(Convolutional Recurrent Neural Network,卷积递归神经网络)是这个领域内的一个代表性的框架,它融合了卷积神经网络(CNN)和递归神经网络(RNN),特别适用于对图像中的序列文本进行识别。

CRNN的结构
组成部分
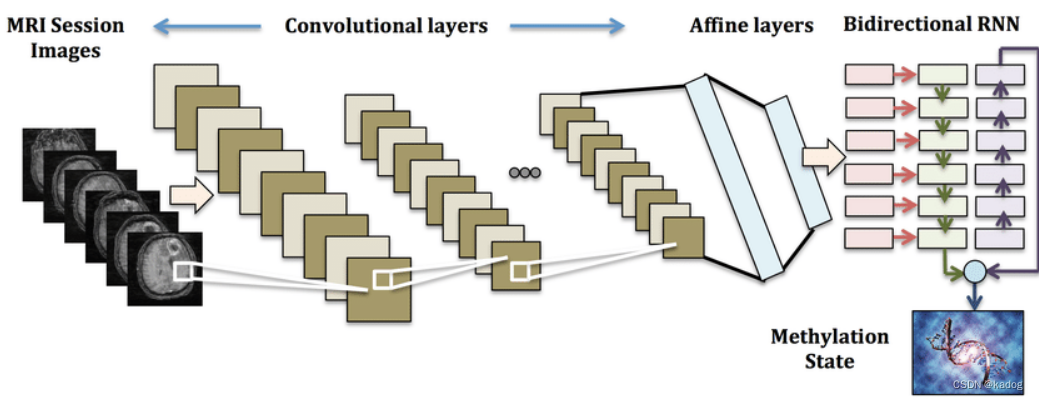
CRNN模型主要包含三个部分:一个用于提取图像特征的卷积层序列、一个用于序列建模的递归层序列和一个转录层,将递归层的输出解码为一个文本序列。
工作原理
卷积层负责提取图像的特征,这些特征随后被展平并输入到递归层。在递归层中,RNN处理输入序列,并且能够在序列的每个时间步捕捉上下文信息。这对于理解文本的意义尤其重要,因为文本的特定字符通常需要对前文和后文的了解。最后是转录层(通常使用CTC即Connectionist Temporal Classification)对RNN的输出进行解码,生成最终的文本序列。
CRNN结构分析
卷积层(Convolutional Layers)
CRNN的第一部分是一系列卷积层,用于从输入图像中提取视觉特征。设输入图像为 I ,通过 L 层卷积操作后得到的特征图(feature map)为:
F L = c o n v ( I ; W L , b L ) F^L = conv(I; W^L, b^L) FL=conv(I;WL,bL)
其中 W^L和 b^L 分别代表第 L 层的卷积权重和偏置。卷积操作提取的特征 F^L将被送入后续的递归层进行进一步的处理。
递归层(Recurrent Layers)
递归层的作用是对特征序列进行建模,捕捉序列中的时间依赖性。最常用的RNN单元是长短时记忆(LSTM),它在处理长序列数据时表现出色。LSTM有三个门控机制:遗忘门 f_t,输入门 i_t 和输出门 o_t 。LSTM单元中在时间步 t 的状态更新公式如下:
遗忘门:
f
t
=
σ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
ft=σ(Wf⋅[ht−1,xt]+bf)
输入门:
i
t
=
σ
(
W
i
⋅
[
h
t
−
1
,
x
t
]
+
b
i
)
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
it=σ(Wi⋅[ht−1,xt]+bi)
输出门:
o
t
=
σ
(
W
o
⋅
[
h
t
−
1
,
x
t
]
+
b
o
)
o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)
ot=σ(Wo⋅[ht−1,xt]+bo)
新记忆单元内容:
C
~
t
=
tanh
(
W
C
⋅
[
h
t
−
1
,
x
t
]
+
b
C
)
\tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)
C~t=tanh(WC⋅[ht−1,xt]+bC)
记忆单元更新:
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
~
t
C_t = f_t * C_{t-1} + i_t * \tilde{C}_t
Ct=ft∗Ct−1+it∗C~t
隐藏状态更新:
h
t
=
o
t
∗
tanh
(
C
t
)
h_t = o_t * \tanh(C_t)
ht=ot∗tanh(Ct)
在CRNN中,通常使用双向LSTM(Bi-LSTM),在每个时间步 t 同时考虑先前h_{t-1} 和后续h_{t+1} 的上下文信息。
转录层(Transcription Layer)
CRNN的最后部分是转录层,负责将递归层的输出映射到最终的序列标签。转录通常通过CTC(Connectionist Temporal Classification)完成,CTC利用概率论原理解决无对齐数据的序列学习问题,其目标是最大化条件概率:
P ( π ∣ x ) P(\pi|x) P(π∣x)
其中π表示一个路径,它通过删除重复的标签和空白标签来映射到最终的标签序列l 。CTC的目标函数定义如下:
P ( l ∣ x ) = ∑ π ↦ l P ( π ∣ x ) P(l|x) = \sum_{\pi \mapsto l} P(\pi|x) P(l∣x)=π↦l∑P(π∣x)
该函数对所有可能映射到标签序列 l 的路径π的概率求和。
CRNN在文本识别中的应用
识别不定长文本
CRNN特别适用于识别图像中的不定长文本。它不需要预先定义文本的长度,这给识别流程带来了极大的灵活性。
单词和场景文本的识别
CRNN不仅可以在图像中识别单个字符或者单词,还能很好地工作在识别自然场景中的文本,如街道标志、广告牌等。
强大的泛化能力
CRNN已被证实在多个文本识别数据集上表现出色,并能够很好地泛化到新的、未见过的图像。
CRNN的优势与局限性
优势
- 端到端学习: CRNN能够从原始图像直接学习到文本识别所需要的最终输出,无需手动特征提取或其他预处理步骤。
- 对于图像扭曲的鲁棒性: CRNN对图像的畸变和扭曲有很好的适应性,提高了模型在现实世界应用的实用性。
局限性
- 计算成本: CRNN结合了CNN和RNN两个复杂的模型,可能导致较高的计算成本。
- 训练数据: 获得大量带有标注的训练数据对于训练CRNN模型来说至关重要,但这有时候可能既昂贵又耗时。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)