pyspark笔记:读取 & 处理csv文件 (pyspark DataFrame)
pyspark cmd上的命令。
pyspark cmd上的命令
1 读取文件
1.1 基本读取方式
pyspark中是惰性操作,所有变换类操作都是延迟计算的,pyspark只是记录了将要对数据集进行的操作
只有需要数据集将数据返回到 Driver 程序时(比如collect,count,show之类),所有已经记录的变换操作才会执行
注意读取出来的格式是Pyspark DataFrame,不是DataFrame,所以一些操作上是有区别的
1.1.1 format
DataFrame = spark.read.format("csv")
.option(name,value)
.load(path)- format表示读取格式csv
- option就是读取csv时可选的选项
- path就是文件所在的路径
1.1.2 csv
DataFrame = spark.read
.option(name,value)
.csv(path)- option就是读取csv时可选的选项
- path就是文件所在的路径
1.1.3 读取多个文件
使用spark.read.csv()可以读取多个csv文件
df = spark.read.csv("path1,path2,path3")
#读取path1,path2和path3df= spark.read.csv("Folder path")
#读取Folder path里面的所有csv文件1.2 option 主要参数
| sep | 默认, 指定单个字符分割字段和值 |
| encoding | 默认utf-8 通过给定的编码类型进行解码 |
| header | 默认false 是否将第一行作为列名 |
| schema | 手动设置输出结果的类型
|
| inferSchema | 根据数据预测数据类型 加了的话文件读取的次数是2次。 比如一列int 数据,不设置inferSchema=True的话,那么返回的类型就是string类型,设置了的话,返回类型就是int类型 |
| nullValues | 指定在 CSV 中要视为 null 的字符串 |

1.3 举例
三种设置option的方法:
celltable = spark.read.format("csv")
.option("header", "true")
.option("delimiter","\t")
.load("xxx/test.txt")
celltable = spark.read.format("csv")
.options(header=True,delimiter='\t')
.load("xxx/test.txt")
celltable = spark.read.format("csv")
.load("xxx/test.txt",header=True,delimiter='\t')celltable = spark.read
.option("header", "true")
.option("delimiter","\t")
.csv("xxx/test.txt")此时的celltable不会加载数据
1.3.1 读入多个文件(使用通配符)
celltable = spark.read.format("csv")
.option("header", "true")
.option("delimiter","\t")
.load("xxx/test_*.txt")2 其他主要函数
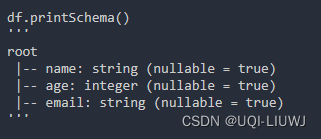
printSchema | 打印出 DataFrame /Dataset每个列的名称和数据类型
如果read的时候不手动设置schema,或者使用inferSchema的话,默认每一列的数据类型为string |
select | 从DataFrame中选取部分列的数据
|
| 将提取出来的某一列重命名
| |
filter | 条件查询 获得字段LAC是'307'的行 |
dropDuplicates | 去重 |
groupby |  |
sort | 排序 |
first | 数据的第一行
|
headtake | 默认是提取一行(此时和first同效果) 如果有参数,那么就是提取最前面的n行
此时返回的是python的list |
limit | 类似于head,只不过返回的是pyspark DataFrame
|
count | 行数
|
collect | 获取所有结点的数据 |
describe | 类似于pandas中的describe,不过如果需要展现结果,需要使用show()
|
withColumn | 修改/新增 某一列
!!!注:withColumn 后返回一个新的pyspark DataFrame 所以 即使是df=df.withColumn(...) ,且之前已经df.cache过了,withColumn之后的df仍然没有cache
|
withColumnRenamed | 某一列重命名
|
cast | 将列的数据类型转化成指定列
|
show | 显示前多少行(默认20行,修改需要设置参数n) truncate=False——显示每一行完整的内容 |
intersect | 两个pyspark DATa Frame取交集
|
union | 两个pyspark Data Frame取并集
|
dropna |
|






 —>
—>





3 stat
corr | 两列的相关系数
|

4 创建pyspark DataFrame
4.1 使用Row
from pyspark.sql import Row
data = [
Row(id=1, name="Alice", age=25),
Row(id=2, name="Bob", age=30),
Row(id=3, name="Charlie", age=28)
]
df = spark.createDataFrame(data)
df.show()
'''
+---+---+-------+
|age| id| name|
+---+---+-------+
| 25| 1| Alice|
| 30| 2| Bob|
| 28| 3|Charlie|
+---+---+-------+
'''4.2 不使用Row
employee_salary = [
("Ali", "Sales", 8000),
("Bob", "Sales", 7000),
("Cindy", "Sales", 7500),
("Davd", "Finance", 10000),
("Elena", "Sales", 8000),
("Fancy", "Finance", 12000),
("George", "Finance", 11000),
("Haffman", "Marketing", 7000),
("Ilaja", "Marketing", 8000),
("Joey", "Sales", 9000)]
columns= ["name", "department", "salary"]
df = spark.createDataFrame(data = employee_salary, schema = columns)
df.show(truncate=False)
参考内容:IBBD.github.io/hadoop/pyspark-csv.md at master · IBBD/IBBD.github.io · GitHub

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)