机器学习工程实践——基于随机森林模型的数据挖掘项目流程
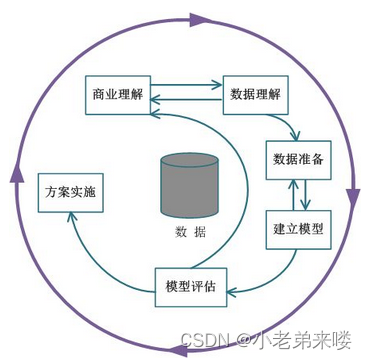
一个完整的数据挖掘项目流程主要包含六大部分,分别是商业理解、数据理解、数据准备、建立模型、模型评估、方案实施,如图所示数据挖掘项目流程。
一个完整的数据挖掘项目流程主要包含六大部分,分别是商业理解、数据理解、数据准备、建立模型、模型评估、方案实施,如图所示

数据挖掘项目流程
1.0 问题导入
以2023年西北大学数学建模竞赛A题为例,完成一个完整的数据挖掘项目流程
赛题链接:https://math.nwu.edu.cn/info/1124/3415.htm
问题1:
附件1中有 608个已知类别的肿瘤数据序列样本,包含特征属性和分类属性,其中分类属性中的2为良性,4为恶性。请建立分类属性与特征属性之间关系的数学模型,并评估你们所建模型的优良程度。
问题2:
请预测附件2中各样本的分类属性,并分析结果的可靠性。
问题3:
研究附件1中的样本数据,寻找癌症病例的标志性特征
1.1 商业理解(Business Understanding)
商业理解也称业务理解,在我们拿到一个数据挖掘任务时,首先要明确三点:
需要解决什么样的问题,比如是分类问题还是聚类问题
要达到什么样的效果,比如预测准确率达到什么级别
项目规模有多大,比如是否需要大数据分布式平台处理
从以上三个角度对问题进行分析:
1、我们需要完成一个分类任务,判断肿瘤的类别
2、题目未对准确率做要求,我们尽可能提高模型的预测精度
3、本题项目规模较小,目前不需要使用大数据等技术
1.2 数据理解(Data Understanding)
数据理解也称数据分析,在正式使用模型之前首先要了解数据情况,一般包括:
数据规模:考虑样本数目,特征维度,需要什么级别的数据处理平台
特征数据类型:数值型和类别型
数据完整度:各样本特征的取值是否存在缺失,如有缺失,缺失规模各自多大
各特征取值的分布情况:比如类别特征一共包含多少个类别,每个类别占比多少?数值型特征的分布情况如何,是否满足高斯分布等?
已知类别样本部分截图:

注:1、数据中“?”表示该值不清楚;2、分类中2和4分别代表良性肿瘤和恶性肿瘤
待预测样本部分截图:

注:1、数据中“?”表示该值不清楚
从以上四个角度对数据进行分析:
1、题目给定 608个已知类别的肿瘤数据序列样本,数据规模是比较小的,不需要采取大数据分布式平台去处理
2、特征数据全部为数值型,取值范围[1,10]
3、样本特征的取值存在缺失,缺失数量较少
4、数值型特征的分布情况在数据准备阶段通过图标输出观察
1.3 数据准备(Data Preparation)
数据准备是数据挖掘任务中最重要且最耗时的环节,它决定着模型优良程度的上限,模型所做的是尽可能接近这一上限
1、从文件层面对数据进行简单处理,将附件1命名为 data_train,作为原始训练集,附件2 命名为data_pred,这是待预测数据,作为测试集;去除数据文件中的冗余,比如注释;经观察得数据文件中的缺失数据量非常少,所以可以直接手动删除“?”,减少不必要的编程
2、导入数据并输出整体信息
import pandas as pd
from collections import Counter
#=======数据导入===============
def readDataFile(readPath):
try:
dfFile = pd.read_excel(readPath,header=0) #读取excel表格中的数据
except Exception as e:
print("读取数据文件失败:{}".format(str(e)))
return
return dfFile
#=======整体查看数据===============
def dataShow(data):
print("————查看数据整体信息————")
data.describe()
data.info()
def main():
#数据文件地址
readPath_train = "data_train.xlsx"
readPath_pred = "data_pred.xlsx"
#导入训练数据
data_train = readDataFile(readPath_train)
dataShow(data_train)
print('类别: ', Counter(data_train['类别'])) #因变量‘类别’分布情况
#导入待预测数据
data_pred = readDataFile(readPath_pred)
dataShow(data_pred)
if __name__ == '__main__':
main()
原始训练集输出:

测试集输出:

反映出的数据信息还是比较完善的
3、特征工程
特征工程详情: https://blog.csdn.net/T940842933/article/details/131893991?spm=1001.2014.3001.5502
(1)数据清洗
#=======数据清洗===============
def dataComplement(data):
#将数据中类别属性'4'置换为'0','2'置换为'1'
#为随机森林构建中true和false判断做准备
for v in range(len(data)):
if data['类别'][v] == 4:
data.loc[data.index == v, '类别'] = 0
if data['类别'][v] == 2:
data.loc[data.index == v, '类别'] = 1
print("————数据清洗————")
#输出缺失值信息
total = data.isnull().sum() #各列数据缺失个数
print(total)
percent = data.isnull().sum()/data.isnull().count() #缺失值数据比例
print(percent)
#缺失值用该列数据中的中位数作填充
data_new = data.fillna(data.median())
#显示处理结果
total = data_new.isnull().sum()
print("填充后各列缺失个数:")
print(total)
return data_new
改变类别标签这几行代码暂时可以忽略,缺失信息输出如下(左:原始训练集,右:预测集):


填补后的结果(左:原始训练集,右:预测集);


(2)特征处理
经观察可知,本次数据挖掘项目得特征均为数值型,且取值范围为[1,10],本身便是离散的,不需要再进行处理;我们可以输出各特征的分布情况:
#=======特征分布===============
def featureDistribution(data):
plt.rcParams['font.sans-serif'] = ['FangSong'] #显示中文,黑体
plt.rcParams['axes.unicode_minus'] = False
#建立列索引
feature = ['特征1','特征2','特征3','特征4','特征5','特征6','特征7','特征8','特征9']
fit,axes=plt.subplots(3,3)
i = 1
for v in feature:
if i%3==0:j = int(i/3-1)
else:j = int(i/3)
k = (i+2)%3
print(j,k)
plt.subplot(3,3,i)
sns.set(style="darkgrid",font='FangSong',rc={'figure.figsize':(15,15)})
sns.distplot(data[v],hist=True,kde=True,ax=axes[j][k])
i += 1
plt.show()原始训练集特征分布情况:

预测集特征分布情况:

这特征分布多少有点抽象,但很明显,他们都基本符合高斯分布
至于特征交互和特征映射,暂时也不做处理,后续根据模型训练情况再进行相关操作
4、相关性分析
相关分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度,相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析;相关系数的取值范围为[-1,1]
区间[-1,0)为负相关,代表一个变量的增加会引起另一个变量的减少,相关系数等于-1时则说明两个变量完全负相关
区间(0,1]为正相关,代表两个变量同增同减,相关系数等于1时则说明两个变量完全正相关
相关系数为0时则意味着两个变量不相关
相关性包括特征与特征之间的相关性、特征与类别之间的相关性,可采用热力图的形式展示:
#=======特征相关性分析===============
def dataRelevance(data):
plt.rcParams['font.sans-serif'] = ['FangSong'] #显示中文,仿宋
plt.rcParams['axes.unicode_minus'] = False
data.drop(['样本编号'], axis=1, inplace=True) #删除无关列‘样本编号’和‘类别’
plt.figure(figsize=(10,10)) #设置画布大小
plt.title("特征间的相关系数", fontsize = 25) #设置标题
sns.heatmap(data.corr(), square=True, annot=True, annot_kws={"fontsize":10}) #对数据进行相关性分析
# 设置刻度字体大小
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.yticks(rotation=360) #纵坐标横向展示
plt.show()
print(data.corr()["类别"])热力图输出:

数值输出:

由图可以看出,特征间均为正相关,特征与类别呈负相关,且没有与类别不相关的特征
1.4 建立模型(Modeling)
机器学习中的分类模型有逻辑回归、朴素贝叶斯、决策树、支持向量机、随机森林、梯度提升树等分类算法,不仅可以进行二分类,还可以进行多分类,我们使用随机森林模型
模型选择:https://blog.csdn.net/T940842933/article/details/131959196?spm=1001.2014.3001.5502
1、数据集切分
#=======数据集切分===============
def dataTakeApart(data):
X= data.drop(columns=['样本编号','类别']) #存放所有自变量‘特征’数据
y = data['类别'] #存放因变量‘类别’数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 5)
return X_train, X_test, y_train, y_test训练集:


验证集:


2、建立模型并调优
网格搜索调优:https://blog.csdn.net/T940842933/article/details/131968261?spm=1001.2014.3001.5502
第一次寻优:
#=======随机森林模型网格搜索寻优===============
def createRandomForest(X_train, X_test, y_train, y_test, data):
#随机森林模型
rfc = ensemble.RandomForestClassifier()
#基于网格搜索获取最优模型
params = {
'criterion':['entropy','gini'], #节点分裂依据
'max_depth':[3, 5, 7, 9], #决策树模型的最大深度
'n_estimators':[10, 25, 50, 75, 100], #随机森林模型中包含决策树模型的个数
'max_features':[0,4, 0.5, 0.6, 0.7], #用于构建决策树时选取的最大特征数量
'min_samples_split':[2, 3, 5, 8, 12, 16], #当前节点允许分裂的最小样本
'min_samples_leaf':[1, 2, 5, 10]}
#进行网格搜索和交叉验证
rfc_cv = GridSearchCV(estimator=rfc, param_grid=params, scoring='roc_auc', cv=10)
rfc_cv.fit(X_train, y_train) #训练模型
print("模型的最优参数:",rfc_cv.best_params_)
print("最优模型分数:",rfc_cv.best_score_)
print("最优模型对象:",rfc_cv.best_estimator_)
print("预测准确率:",rfc_cv.score(X_test, y_test))
使用网格搜索寻优切记不要一次性设置过多参数,不然真的会跑超级长的时间!!!第一次设置的参数跑了四个小时没出结果,上面这段寻优代码跑了块1h,有兴趣的朋友可以自己尝试一下
采用先粗调再细调的方式,先获得一组参数值,再依次调整每一个参数的取值,最终得到最优模型
粗调后的结果:

可以看出模型准确率是非常高的
下面开始细调参数:
先将所有参数设置为网格搜索出的最优值,再依次对每个参数取值细调
参数 criterion :
'criterion':['gini'], 参数 n_estimators:
在10的附近取值
'n_estimators':[6, 7, 8, 9, 10, 11, 12, 13, 14],结果:

寻找出的最优值为 11,将 n_estimators参数设置为11,同时可以看出模型预测的准确率提高了
但最优模型分数有所下降,最优模型分数其实指代的是模型拟合优度,由于数据集切分是随机的,随机森林算法在选取特征构建决策树时也是随机的,所以都会给拟合度带来影响
参数 max_depth:
#取6,7,8三个值
'max_depth':[6, 7, 8],结果:

得到参数 max_depth 的最优取值为7
参数 max_features:
#在0.5附近取值
'max_features':[0.45, 0.46, 0.47, 0.48, 0.49, 0.5, 0.51, 0.52, 0.53, 0.54, 0.55],结果:

发现最优值为0.55,为我们设置的最大值,所以进行第二次细调
#在0.55-0.6附近取值
'max_features':[0.55, 0.56, 0.57, 0.58, 0.59],结果:

所以参数 max_features的最终取值为0.57
参数 min_samples_split:
#取值3,4
'min_samples_split':[3, 4],结果:

所以我们将参数 min_samples_split 的值更改为 4
参数 min_samples_leaf:
这个参数就取值 1,不用更改
最终确定模型参数:
params = {
'criterion':['gini'], #节点分裂依据
'max_depth':[7], #决策树模型的最大深度
'n_estimators':[11], #随机森林模型中包含决策树模型的个数
'max_features':[0.57], #用于构建决策树时选取的最大特征数量
'min_samples_split':[3, 4], #当前节点允许分裂的最小样本
'min_samples_leaf':[1]} 1.5 模型评估(Evaluation)
链接:https://blog.csdn.net/T940842933/article/details/131667393?spm=1001.2014.3001.5502
#=======随机森林模型评估===============
def modelEvaluation(X_train, X_test, y_train, y_test, rfc_cv):
print(rfc_cv.best_score_)
y_train_pred = rfc_cv.predict(X_train) #使用随机森林对训练集进行预测
y_test_pred = rfc_cv.predict(X_test) #使用随机森林对验证集进行预测
r_train = rfc_cv.score(X_train,y_train)
r_test = rfc_cv.score(X_test,y_test)
#训练集
Evaluation(y_train, y_train_pred, r_train)
#验证集
Evaluation(y_test, y_test_pred, r_test)
#=======评估角度===============
def Evaluation(y_true, y_pred, r):
print('随机森林模型查全率、查准率和 F1 值:')
print(metrics.classification_report(y_true, y_pred))
print('绝对误差: ',mean_absolute_error(y_true, y_pred))
print('均方误差: ',mean_squared_error(y_true, y_pred))
print("拟合优度r^2: ",r)
print("混淆矩阵:\n", confusion_matrix(y_true, y_pred))
#画ROC/AUC曲线图,直观显示模型优良程度
fpr, tpr, threshold = metrics.roc_curve(y_true, y_pred)
roc_auc = metrics.auc(fpr, tpr)
print('随机森林 AUC = %.3f' %roc_auc)
plt.figure(figsize=(6,6))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.3f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()从训练集角度进行评估:


从验证集角度进行评估:


整体来说,模型还是优化的不错滴
1.6 方案实施(Deployment)
对所给待预测数据样本进行预测,并以文件的形式保存
#=======数据预测及存储===============
def forecast(data, rfc_cv):
data_pred = data.drop(columns=['样本编号','类别']) #待预测数据自变量
test_pred = rfc_cv.predict(data_pred) #结果预测
data['类别'] = pd.DataFrame(test_pred,columns=['类别']) #自变量数据与结果整合
#将类别预测结果'0'置换为’4', '1'置换为'2', 符合题目所给数据格式
for v in range(len(data)):
if data['类别'][v] == 0:
data.loc[data.index == v, '类别'] = 4
if data['类别'][v] == 1:
data.loc[data.index == v, '类别'] = 2
print(data)#显示预测结果
#将预测的数据存入xlsx表格中
data.to_excel("result.xlsx",index=False)预测结果:

并且题目中要求寻找癌症病例的标志性特征,我们将特征重要性输出
#=======模型特征重要性===============
def featureImportance(rfc_cv,X_train):
#特征重要性评估
importances = list(rfc_cv.best_estimator_.feature_importances_)
feature_list = list(X_train.columns) #特征变量名称
x_values = list(range(len(importances))) #每个特征对应的权重
plt.rcParams['font.sans-serif']=['FangSong'] #图片显示中文
plt.rcParams['axes.unicode_minus'] = False #减号unicode编码
plt.bar(x_values, importances, orientation='vertical') #画柱状图
for a,b in zip(x_values,importances):#显示柱状图数值
plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=15);
plt.xticks(x_values, feature_list, rotation=6) #x轴坐标
plt.ylabel('Importance') #y轴标题
plt.xlabel('Variable') #x轴标题
plt.title('Variable Importances') #柱状图标题
plt.show()输出结果:

观察可以看出,癌症病例的标志性特征为特征2、特征3以及特征6
随机森林模型建立完成,基本上可以满足题目要求,如果有更好的改进方案,可以评论或者私信我,一起讨论
完整代码:
import pandas as pd
from collections import Counter
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import metrics
import sklearn.ensemble as ensemble
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import confusion_matrix
#=======数据导入===============
def readDataFile(readPath):
try:
dfFile = pd.read_excel(readPath,header=0) #读取excel表格中的数据
except Exception as e:
print("读取数据文件失败:{}".format(str(e)))
return
return dfFile
#=======整体查看数据===============
def dataShow(data):
print("————查看数据整体信息————")
data.describe()
data.info()
#=======数据清洗===============
def dataComplement(data):
#将数据中类别属性'4'置换为'0','2'置换为'1'
#为随机森林构建中true和false判断做准备
for v in range(len(data)):
if data['类别'][v] == 4:
data.loc[data.index == v, '类别'] = 0
if data['类别'][v] == 2:
data.loc[data.index == v, '类别'] = 1
#print("————数据清洗————")
#输出缺失值信息
total = data.isnull().sum() #各列数据缺失个数
#print(total)
percent = data.isnull().sum()/data.isnull().count() #缺失值数据比例
#print(percent)
#缺失值用该列数据中的中位数作填充
data_new = data.fillna(data.median())
#显示处理结果
total = data_new.isnull().sum()
#print("填充后各列缺失个数:")
#print(total)
return data_new
#=======特征分布===============
def featureDistribution(data):
plt.rcParams['font.sans-serif'] = ['FangSong'] #显示中文,黑体
plt.rcParams['axes.unicode_minus'] = False
#建立列索引
feature = ['特征1','特征2','特征3','特征4','特征5','特征6','特征7','特征8','特征9']
fit,axes=plt.subplots(3,3)
i = 1
for v in feature:
if i%3==0:j = int(i/3-1)
else:j = int(i/3)
k = (i+2)%3
print(j,k)
plt.subplot(3,3,i)
sns.set(style="darkgrid",font='FangSong',rc={'figure.figsize':(15,15)})
sns.distplot(data[v],hist=True,kde=True,ax=axes[j][k])
i += 1
plt.show()
#=======特征相关性分析===============
def dataRelevance(data):
plt.rcParams['font.sans-serif'] = ['FangSong'] #显示中文,仿宋
plt.rcParams['axes.unicode_minus'] = False
data.drop(['样本编号'], axis=1, inplace=True) #删除无关列‘样本编号’和‘类别’
plt.figure(figsize=(10,10)) #设置画布大小
plt.title("特征间的相关系数", fontsize = 25) #设置标题
sns.heatmap(data.corr(), square=True, annot=True, annot_kws={"fontsize":10}) #对数据进行相关性分析
# 设置刻度字体大小
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.yticks(rotation=360) #纵坐标横向展示
plt.show()
print(data.corr()["类别"])
#=======数据集切分===============
def dataTakeApart(data):
X= data.drop(columns=['样本编号','类别']) #存放所有自变量‘特征’数据
y = data['类别'] #存放因变量‘类别’数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 5)
return X_train, X_test, y_train, y_test
#=======随机森林模型网格搜索寻优===============
def createRandomForest(X_train, X_test, y_train, y_test, data):
#随机森林模型
rfc = ensemble.RandomForestClassifier()
#基于网格搜索获取最优模型
params = {
'criterion':['gini'], #节点分裂依据
'max_depth':[7], #决策树模型的最大深度
'n_estimators':[11], #随机森林模型中包含决策树模型的个数
'max_features':[0.57], #用于构建决策树时选取的最大特征数量
'min_samples_split':[3, 4], #当前节点允许分裂的最小样本
'min_samples_leaf':[1]}
#进行网格搜索和交叉验证
rfc_cv = GridSearchCV(estimator=rfc, param_grid=params, scoring='roc_auc', cv=5)
rfc_cv.fit(X_train, y_train) #训练模型
"""
print("模型的最优参数:",rfc_cv.best_params_)
print("最优模型分数:",rfc_cv.best_score_)
print("最优模型对象:",rfc_cv.best_estimator_)
print("预测准确率:",rfc_cv.score(X_test, y_test))
"""
y_train_pred = rfc_cv.predict(X_train) #使用随机森林对训练集进行预测
y_test_pred = rfc_cv.predict(X_test) #使用随机森林对验证集进行预测
y_train_pred_prob = rfc_cv.predict_proba(X_train) #训练集X_test属于各个类别的概率
y_test_pred_prob = rfc_cv.predict_proba(X_test) #验证集X_test属于各个类别的概率
r_train = rfc_cv.score(X_train,y_train)
r_test = rfc_cv.score(X_test,y_test)
return rfc_cv
#=======随机森林模型评估===============
def modelEvaluation(X_train, X_test, y_train, y_test, rfc_cv):
y_train_pred = rfc_cv.predict(X_train) #使用随机森林对训练集进行预测
y_test_pred = rfc_cv.predict(X_test) #使用随机森林对验证集进行预测
r_train = rfc_cv.score(X_train,y_train)
r_test = rfc_cv.score(X_test,y_test)
#训练集
Evaluation(y_train, y_train_pred, r_train)
#验证集
Evaluation(y_test, y_test_pred, r_test)
#=======评估角度===============
def Evaluation(y_true, y_pred, r):
print('随机森林模型查全率、查准率和 F1 值:')
print(metrics.classification_report(y_true, y_pred))
print('绝对误差: ',mean_absolute_error(y_true, y_pred))
print('均方误差: ',mean_squared_error(y_true, y_pred))
print("拟合优度r^2: ",r)
print("混淆矩阵:\n", confusion_matrix(y_true, y_pred))
#画ROC/AUC曲线图,直观显示模型优良程度
fpr, tpr, threshold = metrics.roc_curve(y_true, y_pred)
roc_auc = metrics.auc(fpr, tpr)
print('随机森林 AUC = %.3f' %roc_auc)
plt.figure(figsize=(6,6))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.3f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#=======模型特征重要性===============
def featureImportance(rfc_cv,X_train):
#特征重要性评估
importances = list(rfc_cv.best_estimator_.feature_importances_)
feature_list = list(X_train.columns) #特征变量名称
x_values = list(range(len(importances))) #每个特征对应的权重
plt.rcParams['font.sans-serif']=['FangSong'] #图片显示中文
plt.rcParams['axes.unicode_minus'] = False #减号unicode编码
plt.bar(x_values, importances, orientation='vertical') #画柱状图
for a,b in zip(x_values,importances):#显示柱状图数值
plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=15);
plt.xticks(x_values, feature_list, rotation=6) #x轴坐标
plt.ylabel('Importance') #y轴标题
plt.xlabel('Variable') #x轴标题
plt.title('Variable Importances') #柱状图标题
plt.show()
#=======数据预测及存储===============
def forecast(data, rfc_cv):
data_pred = data.drop(columns=['样本编号','类别']) #待预测数据自变量
test_pred = rfc_cv.predict(data_pred) #结果预测
data['类别'] = pd.DataFrame(test_pred,columns=['类别']) #自变量数据与结果整合
#将类别预测结果'0'置换为’4', '1'置换为'2', 符合题目所给数据格式
for v in range(len(data)):
if data['类别'][v] == 0:
data.loc[data.index == v, '类别'] = 4
if data['类别'][v] == 1:
data.loc[data.index == v, '类别'] = 2
print(data)#显示预测结果
#将预测的数据存入xlsx表格中
data.to_excel("result.xlsx",index=False)
#=======模型特征重要性===============
def featureImportance(rfc_cv,X_train):
#特征重要性评估
importances = list(rfc_cv.best_estimator_.feature_importances_)
feature_list = list(X_train.columns) #特征变量名称
x_values = list(range(len(importances))) #每个特征对应的权重
plt.rcParams['font.sans-serif']=['FangSong'] #图片显示中文
plt.rcParams['axes.unicode_minus'] = False #减号unicode编码
plt.bar(x_values, importances, orientation='vertical') #画柱状图
for a,b in zip(x_values,importances):#显示柱状图数值
plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=15);
plt.xticks(x_values, feature_list, rotation=6) #x轴坐标
plt.ylabel('Importance') #y轴标题
plt.xlabel('Variable') #x轴标题
plt.title('Variable Importances') #柱状图标题
plt.show()
def main():
#数据文件地址
readPath_train = "data_train.xlsx"
readPath_pred = "data_pred.xlsx"
#导入训练数据
data_train = readDataFile(readPath_train)
#dataShow(data_train)
#print('类别: ', Counter(data_train['类别'])) #因变量‘类别’分布情况
#导入待预测数据
data_pred = readDataFile(readPath_pred)
#dataShow(data_pred)
#数据清洗
data_train=dataComplement(data_train)
data_pred=dataComplement(data_pred)
#特征分布
featureDistribution(data_train)
featureDistribution(data_pred)
#相关性分析
dataRelevance(data_train)
dataRelevance(data_pred)
#数据集切分
X_train, X_test, y_train, y_test = dataTakeApart(data_train)
#print(X_train,"\n", X_test,"\n", y_train,"\n", y_test)
#模型构建和调优
rfc_cv = createRandomForest(X_train, X_test, y_train, y_test, data_train)
#模型评估
modelEvaluation(X_train, X_test, y_train, y_test, rfc_cv)
#预测结果
forecast(data_pred,rfc_cv)
#特征重要性
featureImportance(rfc_cv,X_train)
if __name__ == '__main__':
main()

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)