人脸识别算法评价指标——TAR,FAR,FRR,ERR
前言最近在阅读人脸识别的论文,发现里面用到的指标是TAR(True Accept Rate)和FAR(False Accept Rate),开始没有在意以为相当于TPR(True Positive Rate)和FPR(False Positive Rate), 后来发现并不是这么回事,在百度上也找直接的解释,但是也有一些收获,这里结合自己的理解把学到的东西记录一下。定义TPR和...
前言
最近在阅读人脸识别的论文,发现里面用到的指标是TAR(True Accept Rate)和FAR(False Accept Rate),开始没有在意以为相当于TPR(True Positive Rate)和FPR(False Positive Rate), 后来发现并不是这么回事,在百度上也没有找到直接的解释,但是也有一些收获,这里结合自己的理解把学到的东西记录一下。
定义
TPR和FPR
首先我们来看我们熟悉的TPR(True Positive Rate)和FPR(False Positive Rate),TPR(True Positive Rate)和FPR(False Positive Rate)是二分类算法常用的评价指标,分别是真正例率和假正例率。他们都是基于混淆矩阵的度量标准。
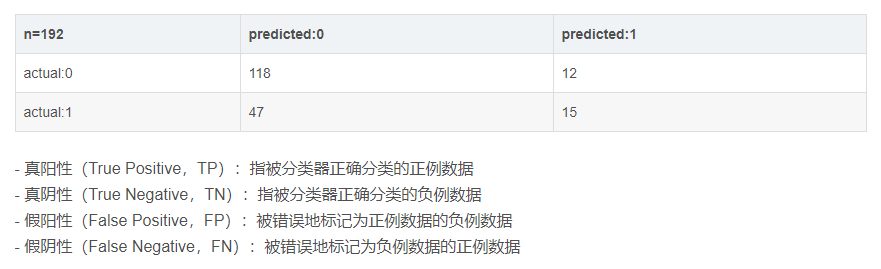
混淆矩阵

下面我们来看看他们的怎么进行计算。
TPR (True Positive Rate)为真正例率,也成召回率和灵敏性: 正确识别的正例数据在实际正例数据中的百分比。
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP }{TP+FN}
TPR=TP+FNTP
FPR (Frue Positive Rate)为假正例率: 实际值是负例数据,预测错误的百分比。
F
P
R
=
F
P
T
N
+
F
P
FPR = \frac{FP }{TN+FP}
FPR=TN+FPFP
关于基于混淆矩阵的分类器的性能度量还有一些别的指标,具体请参考:scikit-learn中评估分类器性能的度量,像混淆矩阵、ROC、AUC等
TAR,FAR 和 FRR,ERR
FAR
接下来看人脸识别中的 常用的指标TAR和FAR。TAR(True Accept Rate)表示正确接受的比例,FAR(False Accept Rate)表示错误接受的比例。所谓的接受就是在进行人脸验证的过程中,两张图像被认为是同一个人。在网上到的了FAR(False Accept Rate)的计算方式如下:
F
A
R
=
非同人分数
>
T
非同人比较的次数
FAR = \frac{非同人分数>T}{非同人比较的次数}
FAR=非同人比较的次数非同人分数>T
对于人脸识别不太了解的小伙伴可能不太了解上面公式的意思,下面我就来解释一下。做人脸验证的时候我们会给出两张图像让算法判断两张图片是不是同一个人的。一般是先将两张图片表示成两个高维的特征向量,然后计算两个特征向量的相似度或者距离。在这里定义FAR时使用的是相似度,公式中分数就是指的相似度。在比较的过程中我们希望同一个人的图像相似度比较高,不同人的相似度比较低。我们会给定一个相似度阈值T,比如0.6, 如果两张图像的相似度大于T我们就认为两张图片是一个人的,如果小于T我们就认为两证图像 是不同人的。但是无论将T设置成什么样值都会有一定得错误率,就是FAR,因为我们提取的图像的特征向量总是不够好,并不总能 满足:同一个人的图像相似度比较高,不同人的相似度比较低。偶尔也会出现不同人的图像的相似度大于给定的阈值T,这样我们就会犯错误接受的错误。FAR就是我们比较不同人的图像时,把其中的图像对当成同一个人图像的比例。我们希望FAR越小越好。
TAR
TAR(True Accept Rate)表示正确接受的比例。所谓的就是在进行人脸验证的过程中,两张图像被认为是同一个人。我在网上并没有查到TAR的定义,在这里我参照FAR的定义猜测一下,不一定正确,如有错误还望批评指正。
T
A
R
=
同人分数
>
T
同人比较的次数
TAR = \frac{同人分数>T}{同人比较的次数}
TAR=同人比较的次数同人分数>T
参考上面对 FAR的解释,我们知道对相同人的图片对进行比较也会出现相似度小于阈值T的情况,这是我们就会犯错误,这个错误就是FRR( False Reject Rate),就是把相同的人的图像当做不同人的了,这个下面我们再讲。可以理解 TAR就是对相同人的图片对进行比较,我们计算出的相似度大于阈值的图像对所占的比例。我们希望TAR越大越好。
FRR
上面讲解TAR的时候,提到了FRR(False Reject Rate)就是错误拒绝率。就是把相同的人的图像当做不同人的了。有了上面的基础,FRR就很好理解了:
F
R
R
=
同人比较分数
<
T
同人比较的次数
FRR=\frac{同人比较分数<T}{同人比较的次数}
FRR=同人比较的次数同人比较分数<T
根据上述公式的定义,我们知道 $ FRR + TAR = 1 $ ,
T
A
R
=
1
−
F
R
R
TAR = 1 - FRR
TAR=1−FRR
FAR和FRR的定义可以概括如下:

EER
EER(Equal Error Rate)即等误率。
EER为 取某个T值时,使得FAR=FRR 时,的FAR或FRR值。
一般画两条曲线,看看交点。
下面以二分类问题来理解一下怎么看EER。在介绍EER之前,首先简单介绍一下混淆矩阵和ROC曲线。
混淆矩阵
针对预测值和真实值之间的关系,我们可以将样本分为四个部分,分别是:
真正例(True Positive,TP):预测值和真实值都为1
假正例(False Positive,FP):预测值为1,真实值为0
真负例(True Negative,TN):预测值与真实值都为0
假负例(False Negative,FN):预测值为0,真实值为1
我们将这四种值用矩阵表示(图片引自《machine learning:A Probabilistic Perspective》):

上面的矩阵就是混淆矩阵。
ROC曲线
通过混淆矩阵,我们可以得到真正例率(True Positive Rate , TPR):

我们还可以得到假正例率(False Positive Rate , FPR):

可以看到,TPR也就是我们所说的召回率,那么只要给定一个决策边界阈值clip_image002[7],我们可以得到一个对应的TPR和FPR值,然而,我们不从这个思路来简单的得到TPR和FPR,而是反过来得到对应的clip_image002[9],我们检测大量的阈值clip_image002[7],从而可以得到一个TPR-FPR的相关图,如下图所示(图片引自《machine learning:A Probabilistic Perspective》):
 图中的红色曲线和蓝色曲线分别表示了两个不同的分类器的TPR-FPR曲线,曲线上的任意一点都对应了一个t(阈值)值。该曲线就是ROC曲线(receiver operating characteristic curve)。该曲线具有以下特征:
图中的红色曲线和蓝色曲线分别表示了两个不同的分类器的TPR-FPR曲线,曲线上的任意一点都对应了一个t(阈值)值。该曲线就是ROC曲线(receiver operating characteristic curve)。该曲线具有以下特征:
- 一定经过(0,0)点,此时t=1,没有预测为P的值,TP和FP都为0
- 一定经过(1,1)点,此时t=0,全都预测为P
- 最完美的分类器(完全区分正负样例):(0,1)点,即没有FP,全是TP
- 曲线越是“凸”向左上角,说明分类器效果越好
- 随机预测会得到(0,0)和(1,1)的直线上的一个点
- 曲线上离(0,1)越近的点分类效果越好,对应着越合理的t
从图中可以看出,红色曲线所代表的分类器效果好于蓝色曲线所表示的分类器。
利用ROC的其他评估标准
AUC(area under thecurve),也就是ROC曲线的下夹面积,越大说明分类器越好,最大值是1,图中的蓝色条纹区域面积就是蓝色曲线对应的 AUC
EER(equal error rate),也就是FPR=FNR的值,由于
F
N
R
=
1
−
F
N
T
P
+
F
N
=
T
P
R
FNR=1- \frac{FN}{TP+FN}=TPR
FNR=1−TP+FNFN=TPR,TPR =-FNR+1 可以画一条从(0,1)到(1,0)的直线,此时的横坐标是FNR。找到交点,图中的A、B两点。曲线交点对应的横坐标是FPR,黑色直线对应的横坐标是FNR,此时FPR等于FNR,假正率等于假负率,即等误率(EER)。
TAR @ FAR=0.00100
我们阅读论文的时候经常看到,TAR = ** @ FAR=0.00100 这样的算法性能报告,意思是说在FAR=0.00100的情况下TAR=**。之所以采用这种形式是因为在不同的FAR下度量的TAR是会不同的。我们可以考虑,增大相似度阈值T的话,可以减小FAR使错误接受的比例降低,但是同时,TAR也会减小,FRR会增加,使错误拒接的比例增加。这相当于提高了标准,会有更少的图像对满足相似度的要求。相反,减小相似度阈值T的话,可以增大TAR使正确接受的比例增加,FRR会减小是错误拒绝的比例减小,但是同时FAR也会增加,使错误接受的人增加。
我们考虑极端情况,相似度阈值T设置为1,这样的话,所有的人都将被拒绝,绝对不会发生错误接受,也不存在正确接受,FRR=1,FAR=0,TAR =0。相反,可以把相似度阈值T设置为0。
所以我看可以看到在报告TAR时,必须说明FAR=0.00100才是有意义的,否则的话,我把FAR设置为1(所有不同的也被全部接受),我的算法的TAR就能达到1。
一般在评价算法的性能时,我们会统计 FAR=0.001/FAR=0.01时,FRR的值作为参考。FRR值越小,TAR越大, 性能越好。
参考文章

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 63
63 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)