统计篇(六)-- 大数定律与中心极限定理
极限定理是概率论的基本理论,在理论研究和应用中起着重要的作用,其中最重要的是称为“大数定律”与“中心极限定理”的一些定理。大数定律是叙述随机变量序列的前一些项的算术平均值在某种条件下收敛到这些项的均值的算术平均值;中心极限定理则是确定在什么条件下,大量随机变量之和的分布逼近于正态分布。
极限定理是概率论的基本理论,在理论研究和应用中起着重要的作用,其中最重要的是称为“大数定律”与“中心极限定理”的一些定理。大数定律是叙述随机变量序列的前一些项的算术平均值在某种条件下收敛到这些项的均值的算术平均值;中心极限定理则是确定在什么条件下,大量随机变量之和的分布逼近于正态分布。本文根据一些经典的教材和大神的总结,并结合自己的理解,在这里整理成自己的学习笔记。
1 随机变量序列的两种收敛性
(1)依概率收敛
设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1, X_2, \cdots, X_n, \cdots
X1,X2,⋯,Xn,⋯ 为概率空间
(
Ω
,
F
,
P
)
(\Omega, F, P)
(Ω,F,P) 上定义的随机变量序列(简称随机序列),若存在随机变数
a
a
a,对任意正数
ϵ
\epsilon
ϵ,恒有
lim
n
→
∞
P
(
∣
X
n
−
a
∣
≥
ϵ
)
=
0
或
lim
n
→
∞
P
(
∣
X
n
−
a
∣
≤
ϵ
)
=
1
\lim_{n \to \infty} P( \lvert X_n - a\rvert \geq \epsilon) = 0 \quad 或 \quad \lim_{n \to \infty} P( \lvert X_n - a\rvert \leq \epsilon) = 1
n→∞limP(∣Xn−a∣≥ϵ)=0或n→∞limP(∣Xn−a∣≤ϵ)=1
则称随机序列
{
X
n
}
\{X_n\}
{Xn} 依概率收敛于随机变量
a
a
a (
a
a
a 也可以是一个常数),记作
X
n
→
P
a
X_n \overset{P}{\to} a
Xn→Pa
依概率收敛的两个含义:
- 收敛:表明这是一个随机变量序列,而不是某个随机变量;且序列是无限长,而不是有限长。
- 依概率:表明序列无穷远处的随机变量 X ∞ X_\infty X∞ 的分布规律为:绝大部分分布于点 a a a,极少数位于 a a a 之外。且分布于 a a a 之外的事件发生的概率之和为0。
(2)依概率收敛的性质
-
若 X n → P a , Y n → P b X_n \overset{P}{\to} a,Y_n \overset{P}{\to} b Xn→Pa,Yn→Pb;则:
X n ± Y n → P a ± b X n Y n → P a b X n ÷ Y n → P a ÷ b X_n \pm Y_n \overset{P}{\to} a \pm b \\ X_n Y_n \overset{P}{\to} ab \\ X_n \div Y_n \overset{P}{\to} a \div b Xn±Yn→Pa±bXnYn→PabXn÷Yn→Pa÷b -
设函数 g ( x , y ) g(x, y) g(x,y) 在点 ( a , b ) (a, b) (a,b) 连续,则:
g ( X n , Y n ) → P g ( a , b ) g(X_n, Y_n) \overset{P}{\to} g(a, b) g(Xn,Yn)→Pg(a,b)
(3)弱收敛(按分布收敛)
随机变量
X
,
X
1
,
X
2
,
⋯
X, X_1, X_2, \cdots
X,X1,X2,⋯ 的分布函数为
F
(
x
)
,
F
1
(
x
)
,
F
2
(
x
)
,
⋯
F(x), F_1(x), F_2(x), \cdots
F(x),F1(x),F2(x),⋯,若对于
F
(
x
)
F(x)
F(x) 的任意一个连续点
x
x
x,有:
lim
n
→
∞
F
n
(
x
)
=
F
(
x
)
\lim_{n \to \infty}F_n(x) = F(x)
n→∞limFn(x)=F(x)
则称分布函数序列
F
n
(
x
)
{F_n(x)}
Fn(x) 弱收敛于
F
(
x
)
F(x)
F(x),记作
F
n
(
x
)
→
W
F
(
x
)
F_n(x) \overset{W}{\to} F(x)
Fn(x)→WF(x)
也称
X
n
{X_n}
Xn 按分布收敛于
X
X
X,记作
X
n
→
L
X
X_n \overset{L}{\to} X
Xn→LX
2 切比雪夫不等式
2.1 切比雪夫不等式
假设随机变量
X
X
X 具有期望
E
(
X
)
=
μ
E(X) = \mu
E(X)=μ,方差
D
(
X
)
=
σ
2
D(X) = \sigma^2
D(X)=σ2,则对于任意正数
ϵ
\epsilon
ϵ,下面的不等式成立:
P
{
∣
X
−
μ
∣
≥
ϵ
}
≤
ϵ
2
σ
2
P\{ \lvert X - \mu \rvert \geq \epsilon \} \leq \frac{\epsilon^2}{\sigma^2}
P{∣X−μ∣≥ϵ}≤σ2ϵ2
其意义是:对于距离
E
(
X
)
E(X)
E(X) 足够远的地方(距离大于等于
ϵ
\epsilon
ϵ),事件出现的概率是小于等于
σ
2
ϵ
2
\frac{\sigma^2}{\epsilon^2}
ϵ2σ2 。即事件出现在区间
[
μ
−
ϵ
,
μ
+
ϵ
]
[\mu - \epsilon, \mu + \epsilon]
[μ−ϵ,μ+ϵ] 的概率大于
1
−
σ
2
ϵ
2
1 - \frac{\sigma^2}{\epsilon^2}
1−ϵ2σ2 。 所以该不等式给出了随机变量
X
X
X 在分布未知的情况下,事件
{
∣
X
−
μ
∣
≤
ϵ
}
\{ \lvert X -\mu \rvert\ \leq \epsilon\}
{∣X−μ∣ ≤ϵ} 的下限估计。
证明:
我们以连续随机变量的情况来证明,离散的情况类似可证。设连续随机变量
X
X
X 的密度函数为
f
(
x
)
f(x)
f(x),事件
X
X
X 即表示
X
X
X 落在区间
(
μ
−
ϵ
,
μ
+
ϵ
)
(\mu - \epsilon, \mu + \epsilon)
(μ−ϵ,μ+ϵ) 外,因此在积分范围内恒有
(
x
−
μ
)
2
ϵ
2
≥
1
\frac{(x - \mu)^2}{\epsilon^2} \geq 1
ϵ2(x−μ)2≥1,故:
P { ∣ X − μ ∣ ≥ ϵ } = ∫ ∣ X − μ ∣ ≥ ϵ p ( x ) d x ≤ ∫ ∣ X − μ ∣ ≥ ϵ ∣ X − μ ∣ 2 ϵ 2 p ( x ) d x ≤ 1 ϵ 2 ∫ − ∞ ∞ ∣ X − μ ∣ 2 p ( x ) d x = σ 2 ϵ 2 P \{ \lvert X - \mu \rvert \geq \epsilon \}= \int_{\lvert X - \mu \rvert \geq \epsilon }p(x)dx \leq \int_{\lvert X - \mu \rvert \geq \epsilon }\frac{{\lvert X - \mu \rvert}^2}{\epsilon^2}p(x)dx \\ \leq \frac{1}{\epsilon^2} \int_{-\infty}^{\infty} {\lvert X - \mu \rvert}^2p(x)dx = \frac{\sigma^2}{\epsilon^2} P{∣X−μ∣≥ϵ}=∫∣X−μ∣≥ϵp(x)dx≤∫∣X−μ∣≥ϵϵ2∣X−μ∣2p(x)dx≤ϵ21∫−∞∞∣X−μ∣2p(x)dx=ϵ2σ2
3 大数定律
大数定律(Law of Large Numbers,LLN)是指某个随机事件在单次试验中可能发生也可能不发生,但在大量重复实验中往往呈现出明显的规律性,即该随机事件发生的频率会向某个常数值收敛,该常数值即为该事件发生的概率。另一种表达方式为当样本数据无限大时,样本均值趋于总体均值。
大数定律的作用:现实生活中,我们无法进行无穷多次试验,也很难估计出总体的参数。大数定律告诉我们能用频率近似代替概率;能用样本均值近似代替总体均值。
大数定律的表达方式主要有:辛钦大数定律、切比雪夫(Cheby—shev)大数法则、贝努利(Bernoulli)大数法则。
3.1 辛钦大数定律
弱大数定律即辛钦大数定律,设
X
1
,
X
2
,
⋯
X_1, X_2, \cdots
X1,X2,⋯ 是相互独立,服从同一分布的随机变量序列,且具有数学期望
E
(
X
k
)
=
μ
(
k
=
1
,
2
,
⋯
)
E(X_k) = \mu (k = 1, 2, \cdots)
E(Xk)=μ(k=1,2,⋯)。前
n
n
n 个变量的算术平均
1
n
∑
k
=
1
n
X
k
\frac{1}{n} \sum_{k = 1}^{n}X_k
n1∑k=1nXk,则对任意
ϵ
>
0
\epsilon > 0
ϵ>0,有
lim
n
→
∞
P
{
∣
1
n
∑
k
=
1
n
X
k
−
μ
∣
<
ϵ
}
=
1
\lim_{n \to \infty}P\{\lvert \frac{1}{n} \sum_{k = 1}^{n}X_k - \mu \rvert < \epsilon \} = 1
n→∞limP{∣n1k=1∑nXk−μ∣<ϵ}=1
辛钦大数定理从理论上指出,对于独立同分布且具有均值 μ \mu μ 的随机变量 X 1 , ⋯ , X n X_1, \cdots, X_n X1,⋯,Xn,当 n n n 很大时,用它们的算术平均值 1 n ∑ k = 1 n X k \frac{1}{n} \sum_{k = 1}^{n}X_k n1∑k=1nXk 来近似实际真值 μ \mu μ 是合理的。
另外一种描述,设随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 相互独立,服从同一分布且具有数学期望 E ( X k ) = μ ( k = 1 , 2 , ⋯ ) E(X_k) = \mu (k = 1, 2, \cdots) E(Xk)=μ(k=1,2,⋯),则序列 X ‾ = 1 n ∑ k = 1 n X k \overline{X} = \frac{1}{n} \sum_{k = 1}^{n}X_k X=n1∑k=1nXk 依概率收敛于 μ \mu μ,即 X ‾ → P μ \overline{X} \overset{P}{\to} \mu X→Pμ。
注:(1)这里并没有要求随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 的方差存在。(2)当 X X X 为服从0-1分布的随机变量时,辛钦大数定律就是伯努利大数定律,故伯努利大数定律是辛钦伯努利大数定律的一个特例。
3.2 伯努利大数定理
设
f
A
f_A
fA 是
n
n
n 次独立重复试验中事件
A
A
A 发生的次数,
p
p
p 是事件
A
A
A 在每次试验中发生的概率,则对于任意正数
ϵ
>
0
\epsilon > 0
ϵ>0,有:
lim
n
→
∞
P
{
∣
f
A
n
−
p
∣
<
ϵ
}
=
1
或
lim
n
→
∞
P
{
∣
f
A
n
−
p
∣
≥
ϵ
}
=
0
\lim_{n \to \infty}P\{\lvert \frac{f_A}{n} - p \rvert < \epsilon \} = 1 \quad 或 \quad \lim_{n \to \infty}P\{\lvert \frac{f_A}{n} - p \rvert \geq \epsilon \} = 0
n→∞limP{∣nfA−p∣<ϵ}=1或n→∞limP{∣nfA−p∣≥ϵ}=0
伯努利大数定律说明:当独立重复实验执行非常大的次数时,事件 A A A 发生的频率逼近于它的概率。
3.3 切比雪夫大数定律
设随机变量
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, \cdots, X_n
X1,X2,⋯,Xn 相互独立,分别有数学期望
E
(
X
1
)
,
E
(
X
2
)
,
⋯
,
E
(
X
n
)
E(X_1), E(X_2), \cdots, E(X_n)
E(X1),E(X2),⋯,E(Xn) 及方差
D
(
X
1
)
,
D
(
X
2
)
,
⋯
,
D
(
X
n
)
D(X_1), D(X_2), \cdots, D(X_n)
D(X1),D(X2),⋯,D(Xn) 并且方差是一致有界的,即存在某一个常数
K
K
K,使得
D
(
X
k
)
<
K
,
k
=
1
,
2
,
⋯
D(X_k)< K, k=1, 2, \cdots
D(Xk)<K,k=1,2,⋯ 则对任意
ϵ
>
0
\epsilon > 0
ϵ>0,恒有
lim
n
→
∞
P
(
∣
1
n
∑
k
=
1
n
X
k
−
1
n
∑
i
=
1
n
E
(
X
k
)
∣
<
ϵ
)
=
1
\lim_{n \to \infty}P(\lvert \frac{1}{n} \sum_{k=1}^{n}X_k - \frac{1}{n} \sum_{i=1}^{n}E(X_k) \rvert < \epsilon) =1
n→∞limP(∣n1k=1∑nXk−n1i=1∑nE(Xk)∣<ϵ)=1
切比雪夫大数定理的意义:由于独立随机变量 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 的算术平均值 X n ‾ = 1 n ∑ k = 1 n X k \overline{X_n} = \frac{1}{n} \sum_{k=1}^{n} X_k Xn=n1∑k=1nXk 的数学期望 E ( X n ‾ ) = 1 n ∑ k = 1 n E ( X k ) E(\overline{X_n}) = \frac{1}{n} \sum_{k=1}^{n} E(X_k) E(Xn)=n1∑k=1nE(Xk) 及方差 D ( X n ‾ ) = 1 n 2 ∑ k = 1 n D ( X k ) D(\overline{X_n}) = \frac{1}{n^2} \sum_{k=1}^{n} D(X_k) D(Xn)=n21∑k=1nD(Xk),当各个方差一致有界时, D ( X n ‾ ) < 1 n 2 n K = K n D(\overline{X_n}) < \frac{1}{n^2}nK = \frac{K}{n} D(Xn)<n21nK=nK,由此可见,当 n n n 充分大时,随机变量 X n X_n Xn 的分布的分散度是很小的, X n ‾ \overline{X_n} Xn 的值比较集中在其数学期望附近。
3.4 马尔科夫大数定律
马尔科夫条件:
lim
n
→
∞
D
(
∑
k
=
1
n
X
k
)
n
2
=
0
\lim_{n \to \infty} \frac{D(\sum_{k =1}^{n}X_k)}{n^2} = 0
n→∞limn2D(∑k=1nXk)=0
满足马尔科夫条件的随机变量序列
X
n
X_n
Xn 服从大数定律。
小结:
| 大数定理 | 分布 | 期望 | 方差 | 用途 |
|---|---|---|---|---|
| 伯努利 | 二项分布 | 相同 | 相同 | 估算概率 |
| 辛钦 | 独立同分布 | 相同 | 相同 | 估算期望 |
| 切比雪夫 | 独立 | 存在 | 存在 有限 | 估算期望 |
小概率原理或实际推断原理——一个事件如果发生的概率很小的话,那么它在一次试验中是几乎不可能发生的,但在多次重复试验中几乎是必然发生的。统计学里,把小概率事件在一次实验中看成是实际不可能发生的事件,一般认为等于或小于0.05或0.01的概率为小概率。实际推断原理通常在假设检验中使用,即如果小概率事件在一次试验中居然发生了,则有理由首先怀疑原假设的真实性,从而拒绝原假设。
4 中心极限定理
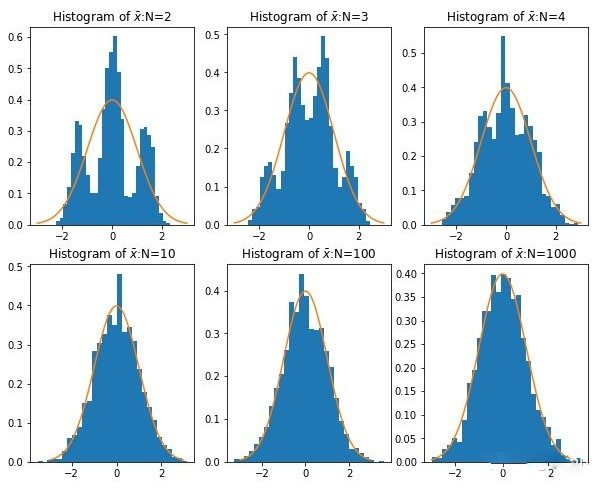
当样本量 n n n 逐渐趋于无穷大时, n n n 个抽样样本的均值的频数逐渐趋于正态分布,其对原总体的分布不做任何要求,意味着无论总体是什么分布,其抽样样本的均值的频数的分布都随着抽样数的增多而趋于正态分布。 如下图所示:

注:图中虚线表示正态分布,可以发现当样本量 n n n 逐渐增大时,样本的分布趋于正态分布。
4.1 独立同分布的中心极限定理
设随机变量
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1, X_2, \cdots, X_n, \cdots
X1,X2,⋯,Xn,⋯ 相互独立,服从同一分布,且具有数学期望和方差:
E
(
X
k
)
=
μ
,
D
(
X
k
)
=
σ
2
(
k
=
1
,
2
,
⋯
)
E(X_k) = \mu, \quad D(X_k) = \sigma^2 (k = 1, 2, \cdots)
E(Xk)=μ,D(Xk)=σ2(k=1,2,⋯),则随机变量之和
∑
k
=
1
n
X
k
\sum_{k = 1}^{n}X_k
∑k=1nXk 的标准化变量
Y
n
=
∑
k
=
1
n
X
k
−
E
(
∑
k
=
1
n
X
k
)
D
(
∑
k
=
1
n
X
k
)
=
∑
k
=
1
n
X
k
−
n
μ
n
σ
Y_n = \frac{\sum_{k=1}^{n}X_k - E(\sum_{k=1}^{n}X_k)}{\sqrt{D(\sum_{k=1}^{n}X_k)}} = \frac{\sum_{k=1}^{n}X_k - n\mu}{\sqrt n \sigma}
Yn=D(∑k=1nXk)∑k=1nXk−E(∑k=1nXk)=nσ∑k=1nXk−nμ
的分布函数
F
n
(
x
)
F_n(x)
Fn(x) 对于任意
x
x
x 满足
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
k
=
1
n
X
k
−
n
μ
n
σ
≤
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\lim_{n \to \infty}F_n(x) = \lim_{n \to \infty}P\{\frac{ \sum_{k = 1}^{n}X_k - n \mu}{\sqrt{n} \sigma} \leq x \} = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)
n→∞limFn(x)=n→∞limP{nσ∑k=1nXk−nμ≤x}=∫−∞x2π1e−t2/2dt=Φ(x)
其物理意义为:均值方差为
μ
,
σ
2
\mu, \sigma^2
μ,σ2 的独立同分布的随机变量
X
1
,
X
2
,
⋯
,
X
n
X_1, X_2, \cdots, X_n
X1,X2,⋯,Xn 之和
∑
k
=
1
n
X
k
\sum_{k = 1}^{n}X_k
∑k=1nXk 的标准变化量
Y
n
Y_n
Yn,当
n
n
n 充分大时,其分布近似于标准正态分布。 一般情况下,很难求出
n
n
n 个随机变量之和的分布函数。因此当
n
n
n 充分大时,可以通过正态分布来做理论上的分析或者计算。
4.2 棣莫弗-拉普拉斯定理
棣莫弗-拉普拉斯(De Moivre-Laplace)中心极限定理是独立同分布中心极限定理的特殊情况,它是最先被发现的中心极限定理。设随机变量
η
n
(
n
=
1
,
2
,
⋯
)
\eta_n(n=1, 2, \cdots)
ηn(n=1,2,⋯) 服从参数为 n, p(0<p<1)的二项分布,则对于任意 a,有:
lim
n
→
∞
P
{
η
n
−
n
p
n
p
(
1
−
p
)
≤
a
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\lim_{n \to \infty}P\{\frac{\eta_n - np}{\sqrt{np(1-p)}} \leq a \} = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)
n→∞limP{np(1−p)ηn−np≤a}=∫−∞x2π1e−t2/2dt=Φ(x)
该定理表明,正态分布是二项分布的极限分布。当 n n n 充分大时,我们可以利用上式来计算二项分布的概率。
4.3 独立不同分布下的中心极限定理
长度、重量、时间等等实际测量量一般符合正态分布,因为它们受各种微小的随机因素的扰动。这些随机因素的独立性是很普遍的,但很难说它们一定同分布。
实际上,一系列独立不同分布的随机变量也可能满足中心极限定理,只是这些不同分布的随机变量要有所限制。以下给出两个独立不同分布下的中心极限定理,不予证明,简单扩展一下。
4.3.1 林德伯格中心极限定理
设
{
X
n
}
\{ X_n\}
{Xn} 是一系列相互独立的连续随机变量,它们具有有限的期望
E
(
X
k
)
=
μ
k
E(X_k) = \mu_k
E(Xk)=μk 和方差
D
(
X
k
)
=
σ
k
2
D(X_k) = \sigma_{k}^{2}
D(Xk)=σk2 ,记
Y
n
=
∑
k
=
1
n
X
k
,
D
(
Y
n
)
=
∑
k
=
1
n
σ
k
2
=
B
n
2
Y_n = \sum_{k = 1}^{n}X_k, \quad D(Y_n) = \sum_{k = 1}^{n}\sigma_{k}^{2} = B_{n}^{2}
Yn=∑k=1nXk,D(Yn)=∑k=1nσk2=Bn2 ,记
X
k
X_k
Xk 的概率密度函数是
f
i
(
x
)
f_i(x)
fi(x),若
∀
τ
>
0
:
lim
n
→
∞
1
τ
2
B
n
2
∑
k
=
1
n
∣
X
−
μ
∣
≥
τ
B
n
(
x
−
μ
)
2
f
k
(
x
)
d
x
=
0
\forall \tau > 0:\lim_{n \to \infty} \frac{1}{\tau^2 B_n^2}\sum_{k=1}^{n} \lvert X - \mu \rvert \geq \tau B_n (x - \mu)^2f_k(x)dx = 0
∀τ>0:n→∞limτ2Bn21k=1∑n∣X−μ∣≥τBn(x−μ)2fk(x)dx=0
则
lim
n
→
∞
P
(
1
B
n
∑
k
=
1
n
(
X
k
−
μ
)
<
a
)
=
Φ
(
a
)
\lim_{n \to \infty}P(\frac{1}{B_n}\sum_{k = 1}^{n}(X_k - \mu) < a) = \Phi(a)
n→∞limP(Bn1k=1∑n(Xk−μ)<a)=Φ(a)
林德伯格中心极限定理对 { X n } \{ X_n \} {Xn} 的约束基本上是最弱的,也就是最强的中心极限定理。
4.3.2 Lyapunov定律
设随机变量
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1, X_2, \cdots, X_n, \cdots
X1,X2,⋯,Xn,⋯ 相互独立,他们具有数学期望和方差:
E
(
X
k
)
=
μ
k
,
D
(
X
K
)
=
σ
k
2
>
0
,
k
=
1
,
2
,
⋯
E(X_k) = \mu_k,\quad D(X_K) = \sigma_{k}^2>0,k = 1, 2, \cdots
E(Xk)=μk,D(XK)=σk2>0,k=1,2,⋯
记
B
n
2
=
∑
k
=
1
n
σ
k
2
B_{n}^2 = \sum_{k = 1}^{n} \sigma_{k}^2
Bn2=∑k=1nσk2
若存在正数
δ
\delta
δ,使得当
n
→
∞
n \to \infty
n→∞ 时,
1
B
n
2
+
δ
∑
k
=
1
n
E
{
∣
X
k
−
μ
k
∣
2
+
δ
}
→
0
\frac{1}{B_{n}^{2 + \delta}} \sum_{k=1}^{n}E\{{\lvert X_k - \mu_k \rvert }^{2 + \delta}\} \to 0
Bn2+δ1k=1∑nE{∣Xk−μk∣2+δ}→0
则随机变量之和
∑
k
=
1
n
X
k
\sum_{k = 1}^{n}X_k
∑k=1nXk 的标准化变量
Z
n
=
∑
k
=
1
n
X
k
−
E
(
∑
k
=
1
n
X
k
)
D
(
∑
k
=
1
n
X
k
)
=
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
Z_n = \frac{\sum_{k = 1}^{n}X_k - E(\sum_{k = 1}^{n}X_k)}{\sqrt{D(\sum_{k = 1}^{n}X_k)}} = \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n}
Zn=D(∑k=1nXk)∑k=1nXk−E(∑k=1nXk)=Bn∑k=1nXk−∑k=1nμk
的分布函数
F
n
(
x
)
F_n(x)
Fn(x) 对于任意
x
x
x,满足
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
≤
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\lim_{n \to \infty}F_n(x) = \lim_{n \to \infty}P\{ \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n} \leq x\} \\ = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)
n→∞limFn(x)=n→∞limP{Bn∑k=1nXk−∑k=1nμk≤x}=∫−∞x2π1e−t2/2dt=Φ(x)
该定理表明,随机变量
Z
n
=
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
Z_n = \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n}
Zn=Bn∑k=1nXk−∑k=1nμk
当 n n n 很大时,近似地服从正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。 由此,当 n n n 很大时, ∑ k = 1 n X k = B n Z n + ∑ k = 1 n μ k \sum_{k = 1}^{n}X_k = B_nZ_n + \sum_{k = 1}^{n}\mu_k ∑k=1nXk=BnZn+∑k=1nμk 近似地服从正态分布 N ( ∑ k = 1 n μ k , B n 2 ) N(\sum_{k = 1}^{n}\mu_k, B_n^2 ) N(∑k=1nμk,Bn2)。这就是说,无论各个随机变量 X k ( k = 1 , 2 , ⋯ ) X_k(k=1, 2, \cdots) Xk(k=1,2,⋯) 服从什么分布,只要满足定理的条件,那么它们的 ∑ k = 1 n X k \sum_{k = 1}^{n}X_k ∑k=1nXk,当 n n n 很大时,就近似地服从正态分布。
5 总结
一、大数定律和中心极限定理的区别
(1)大数定律是说, n n n 只要越来越大,把这 n n n 个独立同分布的数加起来去除以 n n n 得到的这个样本均值(也是一个随机变量)会依概率收敛到真值 μ \mu μ,但是样本均值的分布是怎样的我们不知道。
(2)中心极限定理是说, n n n 只要越来越大,这 n n n 个数的样本均值会趋近于正态分布,并且这个正态分布以 μ \mu μ 为均值, σ 2 / n \sigma^2/n σ2/n 为方差。
(3)综上所述,这两个定律都是在说在独立分布条件下的随机变量平均值的表现。随着 n n n 增大,大数定律说样本均值几乎必然等于总体均值即期望。中心极限定律说,它越来越趋近于正态分布,并且这个正态分布的方差越来越小。
综上:大数定理就是样本均值在总体数量趋于无穷时依概率收敛于样本均值的数学期望(可不同分布)或者总体的均值(同分布)。中心极限定理就是一般在同分布的情况下,样本值的和在总体数量趋于无穷时的极限分布近似于正态分布。
参考资料
- 概率论与随机过程:http://www.huaxiaozhuan.com/数学基础/chapters/2_probability.html
- 大数定律与中心极限定理:https://www.cnblogs.com/大数定律
- 漫谈系列-大数定律:https://blog.csdn.net/qizhuchuanghongdeng/article/details/69214822
- 概率论——大数定律与中心极限定理:https://zhuanlan.zhihu.com/p/259280292
- 中心极限定理与大数定律:https://zhuanlan.zhihu.com/p/406038977

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 52
52 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)