【编译原理】 实验二:词法分析器的手动实现(基于状态机的词法分析器)
1.借助词法分析工具Flex或Lex完成(参考教材伪代码)2.输入:高级语言源代码(如helloworld.c)3.输出:以二元组表示的单词符号序列。通过设计、编制、调试一个具体的词法分析程序,加深对词法分析原理的理解,并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。大多数程序语言的单词符号都可以用状态转换图进行识别。状态转换图可以用程序实现,最简单的办法就是让每一个状
写在前面
理论与习题讲解移步视频
https://www.bilibili.com/video/BV12w411D76w/
一、实验内容
1.借助词法分析工具Flex或Lex完成(参考教材伪代码)
2.输入:高级语言源代码(如helloworld.c)
3.输出:以二元组表示的单词符号序列。
二、实验目的
通过设计、编制、调试一个具体的词法分析程序,加深对词法分析原理的理解,并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
三、实验分析
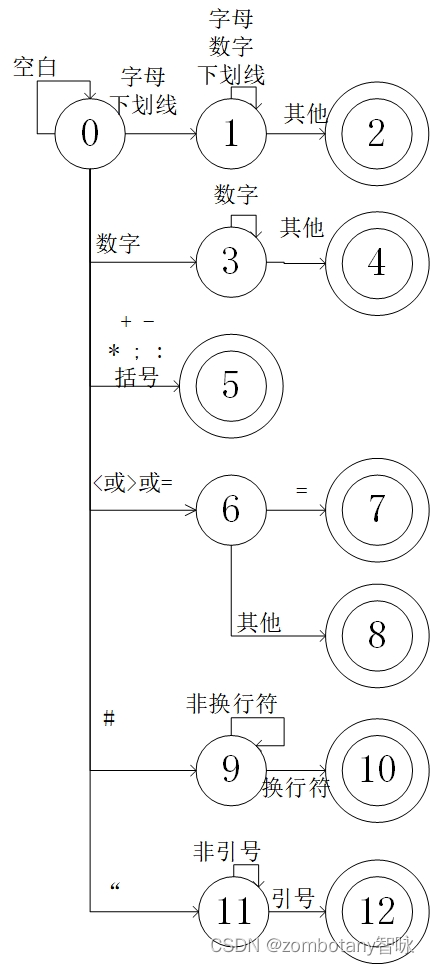
大多数程序语言的单词符号都可以用状态转换图进行识别。状态转换图可以用程序实现,最简单的办法就是让每一个状态对应一小段程序。在本实验中,为了识别c语言的源程序,需要首先构造出c语言的子集的单词符号及其内码值。针对字符串、括号、头文件语句,需要对书上的表格加以修改,以正确地识别出这些单词。
| 单词符号 | 种别编码 | 助记符 | 内码值 |
|---|---|---|---|
| while | 1 | while | - |
| if | 2 | if | - |
| else | 3 | else | - |
| switch | 4 | switch | - |
| case | 5 | case | - |
| 标识符 | 6 | id | id在符号表中的位置 |
| 常数 | 7 | num | Num在常数表中的位置 |
| + | 8 | + | - |
| - | 9 | - | - |
| * | 10 | * | - |
| <= | 11 | relop | LE |
| < | 11 | relop | LT |
| == | 11 | relop | EQ |
| >= | 11 | relop | GE |
| > | 11 | relop | GT |
| = | 12 | = | - |
| ; | 13 | ; | - |
| : | 14 | : | - |
| # | 15 | # | - |
| ( | 16 | 括号 | - |
| ) | 16 | 括号 | - |
| { | 16 | 括号 | - |
| } | 16 | 括号 | - |
| “” | 17 | string | 字符串string在常数表中的位置 |
| (其他关键字) | 18 | - | - |
在设计完单词符号表后,就需要设计状态转换图。
首先对输入串处理,剔除多余的空白符(包括空格、换行符\n、回车符\r、制表符\t、文件结束符等)。将保留字视为一类特殊的标识符进行处理。即:在识别出单词后,若其可能为标识符或保留字,则再对其是否为保留字加以进一步判断,不需要专门对保留字设计状态转换图。
在处理保留字与标识符时,不断读取字母、数字、下划线,直到读到了非字母、非数字、非下划线,则将扫描指针回退,识别到的单词即为保留字与标识符。
在处理数字时,不断读取数字,直到读取到非数字,将扫描指针回退,识别到的单词即为数字。
识别加号、减号、乘号较为简单,识别到后即可直接直接视为单词。
同样的,识别到分号、括号、冒号时,直接视作单词。
识别<号或>号时,还需要再扫描下一个字符是否为等号。
同样的,识别到=时,也需要扫描下一个字符,以区分=或==。
识别到#号时,继续往下读取,直到识别到换行符。
识别到引号时,继续往后读取,直到识别到另一个引号。被引号引起来的部分视为字符串常量。
简要的状态转换图如下所示。
事实上,状态转换图非常容易用程序实现。最简单的办法是让每个状态对应一小段程序。程序的总体流程与实现细节,将在第四与第五章节展开介绍。
四、实验流程
程序的总体流程如下:
1.首先读取文件。
2.只要当前字符不是文件结束符,就反复进行如下过程:
3.将当前的token字符串清空。
4.读取到下一个字符character。
5.再次读取掉空格、换行符。
6.若读取到的第一个字符为字母或下划线,则重复读取当前字符,并将当前字符加到token字符串末尾。直到当前字符不为字母、数字、下划线后,扫描指针回退一字符:
7.判断当前token字符串是否为标识符。若为标识符,则直接识别并输出。若不为标识符,则在符号表中登录该字符串。
8.若读取到的第一个字符为数字,则重复读取当前字符,并将当前字符加到token字符串末尾。直到当前字符不为数字后,扫描指针回退一字符。则当前识别到的单词为数字,需要将常数登录到常数表中。
9.若当前字符为加号+、减号-、乘号*、分号;、冒号:、括号(){},则直接读取并识别出该字符。
10.若当前字符为小于号<、大于号>、等号=,则读取下一字符。若下一字符不为等号,则回退,识别出了小于、大于、赋值。若下一字符为等号,则不回退,识别出了小于等于、大于等于、判断相等。
11.若当前字符为井号#,则重复读取当前字符,并将当前字符加到token字符串末尾。直到当前字符不为字母、数字、下划线。
12.若当前字符为引号,则重复读取当前字符,并将当前字符加到token字符串末尾。直到当前字符不为引号后,扫描指针回退一字符。则当前识别到的单词为字符串。字符串也是常量,需要将常量登记到常量表中。
13.若当前字符为空格或换行符,则再次读掉空格与换行符。
14.若当前位其他字符,则出错处理。
15.回到第2步,除非当前读取到了文件结束符。
针对这一过程,可以构建出的整体流程图如下:

五、实验代码
5.1 数据结构设计
在设计数据结构时,设计如下的全局变量:
1.token,表示当前识别到的字符串。
2.character,字符变量,存放最新读入的字符。
3.fin与fout,表示文件流。
4.number_table,为数组,记录常数表。
5.identifier_table,为map,记录了标识符与标识符在符号表中的位置。
6.string_table,为map,记录了字符串与字符串在字符串常量表中的位置。
7.id_point,string_point,cur_point,为在各个表中的指针。
8.reserved_Word,保留字(关键字表)。
5.2 函数设计
由于本程序的整体流程已在第四章节进行了详细的说明,其代码的实现也与课本上的过程是类似的。所以在此不必赘述。本程序涉及了如下函数用于辅助:
getch():在文件流中读入一个字符
void getch() {
if (fin)
character = fgetc(fin);
}
getbe():若character的字符为空白,则调用getch()直到character为非空字符为止。
void getbe() {
while (character == ' '||character=='\n'||character=='\r'||character=='\t')
getch();
}
concatenation():将token中的字符串与character中的字符连接作为token中的字符串。在实际编写时,调用string的链接即加号即可。
void concatenation() {
token += character;
}
letter()、digit()和underline():判断当前字符是否为字母或数字。
bool letter() {
if ((character >= 'a') && (character <= 'z') || (character >= 'A') && (character <= 'Z'))
return 1;
else
return 0;
}
bool underline() {
if (character == '_')
return 1;
else
return 0;
}
bool digit() {
if ((character >= '0') && (character <= '9'))
return 1;
else
return 0;
}
reserve():判断当前字符是否为保留字。若为保留字,则返回在保留字表中的位置。
int reserve() {
for (int i = 1; i <=reserved_Len; i++) {
if (reserved_Word[i] == token)
return i;
}
return 0;
}
retract():扫描指针回退一个字符,将character置为空白。
void retract() {
fseek(fin, -1, SEEK_CUR);
character = ' ';
}
buildlist():将标识符登录到符号表中或将常数登录到常数表中。
void buildlist() {
char temp = token[0];
int temp_num = 0;//存放转换后的常数值
if (temp >= '0' && temp <= '9') {//如果是数字
temp_num = stoi(token);//则字符串变为常数
int i;
for (i = 0; i < number_point; i++) {
if (temp_num == number_table[i]) {
cur_point = i;
break;
}
}
if (i == number_point) {//如果常数表中没有该常数,则登记常数
number_table[number_point] = temp_num;
cur_point = number_point;
number_point++;
}
}
else if (temp == '\"') {//登记该字符串
if (string_table.count(token))
cur_point = string_table[token];
else {
string_table[token] = string_point++;
cur_point = string_table[token];
}
}
else {
if (identifier_table.count(token))
cur_point=identifier_table[token];
else {
identifier_table[token] = id_point++;
cur_point = identifier_table[token];
}
}
}
error:检测到非法字符,显示出错信息。
void error() {
printf("非法字符:%c\n", character);
}
5.3 完整代码
#include<stdio.h>
#include<stdlib.h>
#include<cstring>
#include<string>
#include<map>
#include<set>
#include<vector>
#include<iostream>
#define _CRT_SECURE_NO_WARNINGS
using namespace std;
string reserved_Word[41] = {"","while","if","else","switch","case","int","main","using","namespace","std","printf"};
int reserved_Len = 40;
FILE* fin, * fout;//文件流
char character;//字符变量,存放最新读入的源程序字符
string token;
int number_table[50];//常数表,存放构成的常数
int number_point;//常数表指针
map<string, int> identifier_table;
map<string, int> string_table;
int id_point = 0;
int string_point = 0;
int cur_point=0;//当前指针
void getch() {
if (fin)
character = fgetc(fin);
}
void getbe() {
while (character == ' '||character=='\n'||character=='\r'||character=='\t')
getch();
}
void concatenation() {
token += character;
}
bool letter() {
if ((character >= 'a') && (character <= 'z') || (character >= 'A') && (character <= 'Z'))
return 1;
else
return 0;
}
bool underline() {
if (character == '_')
return 1;
else
return 0;
}
bool digit() {
if ((character >= '0') && (character <= '9'))
return 1;
else
return 0;
}
int reserve() {
for (int i = 1; i <=reserved_Len; i++) {
if (reserved_Word[i] == token)
return i;
}
return 0;
}
void retract() {
fseek(fin, -1, SEEK_CUR);
character = ' ';
}
void buildlist() {
char temp = token[0];
int temp_num = 0;//存放转换后的常数值
if (temp >= '0' && temp <= '9') {//如果是数字
temp_num = stoi(token);//则字符串变为常数
int i;
for (i = 0; i < number_point; i++) {
if (temp_num == number_table[i]) {
cur_point = i;
break;
}
}
if (i == number_point) {//如果常数表中没有该常数,则登记该常数
number_table[number_point] = temp_num;
cur_point = number_point;
number_point++;
}
}
else if (temp == '\"') {//登记该字符串
if (string_table.count(token))
cur_point = string_table[token];
else {
string_table[token] = string_point++;
cur_point = string_table[token];
}
}
else {
if (identifier_table.count(token))
cur_point=identifier_table[token];
else {
identifier_table[token] = id_point++;
cur_point = identifier_table[token];
}
}
}
void error() {
printf("非法字符:%c\n", character);
}
void test() {
token = "";
getch();//获取字符
getbe(); //滤除空格
switch (character) {
case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':case 'l':case 'm':
case 'n':case 'o':case 'p':case 'q':case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':case 'z':
case 'A':case 'B':case 'C':case 'D':case 'E':case 'F':case 'G':case 'H':case 'I':case 'J':case 'K':case 'L':case 'M':
case 'N':case 'O':case 'P':case 'Q':case 'R':case 'S':case 'T':case 'U':case 'V':case 'W':case 'X':case 'Y':case 'Z':
case '_':
{
while (letter() || digit() || underline()) {
concatenation(); //将当前读入的字符送入token数组
getch();
}
retract(); //扫描指针回退一个字符
int c = reserve();
if (c == 0) {
buildlist(); //将标识符登录到符号表中
//return(id, 指向id的符号表入口指针);
printf("(id,%s)id表入口指针:%d\n", token.c_str(), cur_point);
}
else {
//return(保留字码,null);
printf("(reserved word,%s)种别编码:%d\n", token.c_str(),c);
}
break;
}
case '0':case '1':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':
while (digit()) {
concatenation();
getch();
}
retract();
buildlist();
printf("(num,%d)常数表入口指针:%d\n", number_table[cur_point], cur_point);
break;
case '\"': {
do {
concatenation();
getch();
} while (character != '\"');
concatenation();
getch();
retract();
buildlist();
printf("(string,%s)string表入口指针:%d\n", token.c_str(), cur_point);
break;
}
case '+':
printf("(%c,-)\n", '+');
break;
case '-':
printf("(%c,-)\n", '-');
break;
case '*':
printf("(%c,-)\n", '*');
break;
case '<':
getch();
if (character == '=')
printf("(relop,LE)\n");
else {
retract();
printf("(relop,LT)\n");
}
break;
case '>':
getch();
if (character == '=')
printf("(relop,GE)\n");
else {
retract();
printf("(relop,GT)\n");
}
break;
case '=':
getch();
if (character == '=')
printf("(relop,EQ)\n");
else {
retract();
printf("(assign,=)\n");
//return('=', null);
}
break;
case ';':
printf("(semicolon,;)\n");
//return(';', null);
break;
case ':':
printf("(colon,:)\n");
//return(';', null);
break;
case '#': {
while (character!='\n') {
concatenation(); //将当前读入的字符送入token数组
getch();
}
printf("(head,%s)\n",token.c_str());
break;
}
case '(':case ')':case '{':case '}':
printf("(bracket,%c)\n", character);
break;
default:
if (character == '\n' || character == '\t' || character == EOF)
break;
error();
}
}
int main() {
fin=fopen("F:/HOMEWORK/Compiler/Lab2/test.c", "r");
while (character != EOF)
test();
if (fin)
fclose(fin);
if (fout)
fclose(fout);
return 0;
}
六、运行结果
首先,编写一个可以真实地被执行的c++语言源程序用于测试。

读取该文件,对其进行词法分析,运行得到的结果如图4

该词法分析器首先将头文件识别出来。然后识别了语句using namespace std均为保留字并给出了这几个保留字的种别编码,并识别出了之后的分号。
识别保留字int main并识别出种别编码,并识别出了之后的括号。
识别a1为一个标识符,并记录其在id表中的入口指针为0。
识别单个等号=为赋值符号。
识别常数0,并记录其在常数表中的入口指针为0。
识别标识符_b2,并记录其在id表中的入口指针为1。
识别赋值号后,识别常数3,并记录其在常数表中的入口指针为1。
识别关键字if,给出种别编码。
识别a1。因为在之前a1已经定义过了且已经在id表中被登记过了,所以再次调用a1变量的标识符时,给出其在id表中的入口指针为0。
识别两个等号==为关系运算符判断是否相等。
识别常数1,并记录其在常数表中的入口指针为2。
识别关键字printf,给出种别编码。
识别字符串”hello world”,并给出其在字符串常量表中的指针为0。
识别关键字else与关键字switch。
识别_b2。因为在之前_b2已经定义过了且已经在id表中被登记过了,所以再次调用_b2变量的标识符时,给出其在id表的入口指针为1。
识别关键字case,给出种别编码。
识别常数1。因为之前已经在常数表中将该常数登记过了,所以找到其在常数表中的入口指针为2。
剩余的单词识别过程与前文的识别过程是类似的,单词被识别后的处理过程也与前文的处理过程是类似的,在此不必继续赘述。
七、实验感悟

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)