计算机基础 — 字符编码
字符编码,本质是二进制数据与语言文字的一一对应关系。
字符编码,本质是 二进制数据与 语言文字的一一 对应关系。
一、ASCII 编码
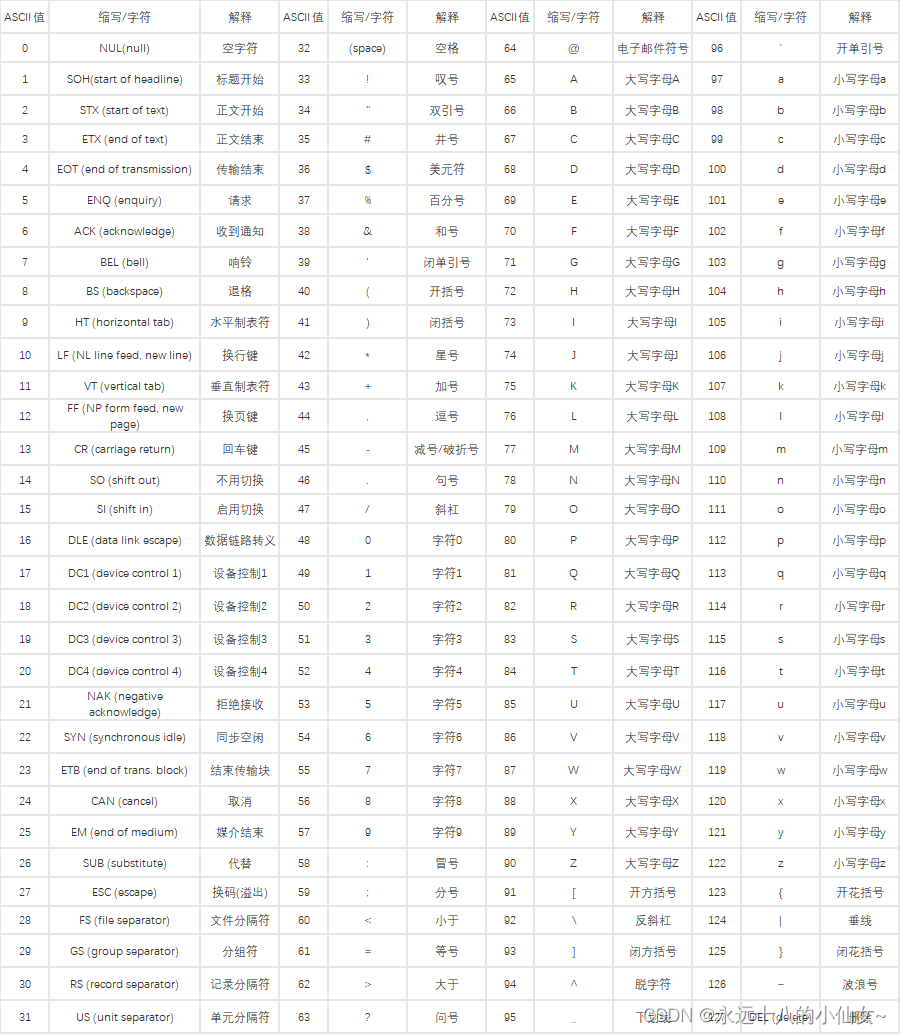
ASCII(American Standard Code for Information Interchange)是最早的字符编码标准,用于将字符表示为7位二进制数。它定义了128个字符的编码,包括英文字母(大写和小写)、数字、标点符号和一些控制字符。
1、编码范围:ASCII 编码使用7位二进制数表示字符,因此可以表示的字符范围是0-127(十进制)。这个范围被分为几个部分,包括控制字符、可打印字符和扩展字符。
2、控制字符:ASCII 编码的前32个字符(0-31)是控制字符,用于控制计算机的特殊操作,如换行、回车、制表等。这些字符通常无法在屏幕上显示,但它们对于控制文本的格式和布局非常重要。
3、可打印字符:ASCII 编码的可打印字符范围是32-126。这包括常见的英文字母(大写和小写)、数字、标点符号和一些特殊字符,如空格、换行符和回车符等。
4、扩展字符:ASCII 编码只能表示128个字符,这对于许多非英语字符是不够的。为了支持更多字符,出现了许多 ASCII 的扩展版本,如 ISO-8859 等。
5、ASCII 表:ASCII 表是一个字符与其对应 ASCII 码的对照表。可以通过查看 ASCII 表来了解每个字符的编码值。

二、中文编码
GB2312(GuoBiao 2312)是中国国家标准局于1980年发布,1981年开始实施的中文字符集编码标准。它是 GBK 编码的前身,主要用于表示简体中文字符。
1、字符集范围:GB2312 字符集包含了6763个字符,其中包括了基本的汉字、英文字母、数字、标点符号等。它主要覆盖了常用的简体中文字符,但并不包含所有中文字符。
2、编码方案:GB2312 采用双字节编码方案,每个中文字符用两个字节表示。第一个字节的范围是 0xA1-0xF7,第二个字节的范围是 0xA1-0xFE。每个字节的高位表示区号,低位表示位号,根据区号和位号的组合可以确定一个具体的字符。
3、汉字区域:GB2312 将中文字符划分为94个区,每个区包含94个位,共计8836个字符。区号从16到87,位号从1到94。GB2312 中最常见的汉字位于第一个区(区号16),并且按照拼音顺序排列。
4、兼容性:GB2312 与 ASCII 编码兼容,即 GB2312 编码的前128个字符与 ASCII 编码完全一致。这意味着可以在 GB2312 编码中直接使用 ASCII 字符,而无需进行额外的转换。
GB2312 所收录的汉字已经覆盖中国大陆99.75%的使用频率,但是对一些罕见的字和繁体字还有很多少数民族使用的字符都没法处理,于是后来就在 GB2312 的基础上创建了一种叫 GBK 的字符编码。GBK 是利用了 GB2312 中未被使用的编码空间上进行扩充,所以它能完全兼容 GB2312 和 ASCII。
三、Unicode(万国码)
Unicode 是一种国际标准,旨在为世界上所有的字符和符号分配唯一的标识号码。它定义了一个巨大的字符集,包含了几乎所有的语言字符、符号和标点符号。
日本把日文编到 JIS 里,韩国把韩文编到 Euc-kr 里。各国有各国的标准,难免会出现冲突,所以在多语言混合的文件中,显示出来会有乱码。Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。现代操作系统和大多数编程语言都直接支持 Unicode。
1、字符集范围:Unicode 字符集包含了超过130,000个字符,其中包括了几乎所有已知的语言字符,包括汉字、拉丁字母、希腊字母、西里尔字母、阿拉伯字母、日文假名、数学符号、货币符号等。Unicode 的目标是覆盖全球范围内的所有字符。
2、编码方案:Unicode 采用了固定长度的编码方案,其中最常见的编码方案是 UTF-8、UTF-16 和 UTF-32。
1)UTF-8:UTF-8 是一种可变长度编码方案,用1到4个字节表示一个字符,可以表示 Unicode 字符集中的所有字符。它是最常用的 Unicode 编码方案,也是互联网上广泛使用的编码方案。
2)UTF-16:UTF-16 是一种固定长度编码方案,用2或4个字节表示一个字符,可以表示 Unicode 字符集中的所有字符。它主要用于操作系统和程序内部的字符串表示。
3)UTF-32:UTF-32 是一种固定长度编码方案,用4个字节表示一个字符,可以表示 Unicode 字符集中的所有字符。UTF-32 编码在存储和处理上需要更多的空间,因此在实践中使用较少。
3、Unicode 码点:每个 Unicode 字符都有一个唯一的码点(Code Point),它是一个数字,表示字符在 Unicode 字符集中的位置。例如,拉丁字母 “A” 的码点是 U+0041,汉字"中"的码点是 U+4E2D。码点通常以 U+ 前缀加上一个十六进制数表示。
4、Unicode 实现:Unicode 的实现是通过分配每个字符一个唯一的码点,并为每个码点定义一个字符的名字和属性。Unicode Consoritum 负责维护和发展 Unicode 标准,它不仅定义了字符集,还提供了字符属性、排序规则、标点符号规范等。
5、字符编码转换:在实际编程中,常常需要在不同的字符编码之间进行转换。例如,将 Unicode 字符转换为 UTF-8 编码的字节序列,或者将 UTF-8 编码的字节序列转换为 Unicode 字符。编程语言提供了相关的编码转换函数,如 Python 中的 encode() 和 decode() 方法。
四、不同语言/平台的编码类型
| 语言/平台 | 编码类型 |
|---|---|
| Java | UTF-16 |
| JavaScript | UTF-16 |
| C/C++ | UTF-8 |
| Python | UTF-8 |
| Linux | UTF-32 |
| Windows | UTF-16 |
GBK 和 UTF-8 的区别:
GBK 编码专门用来解决中文编码的,是双字节的。不论中英文都是双字节的。GBK 包含全部中文字符;
做中文程序的开发用 GBK,因为 utf-8 编码的中文使用了三个字节,用 gbk 节省空间。
如果是英文网站开发,用 utf-8,因为英文只占一个字节,而 gbk 中英文是两个字节,并且国外客户访问 gbk 要下载语言包。
记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)