使用DDPM(扩散模型)训练自己的数据集实现数据集扩容pytorch
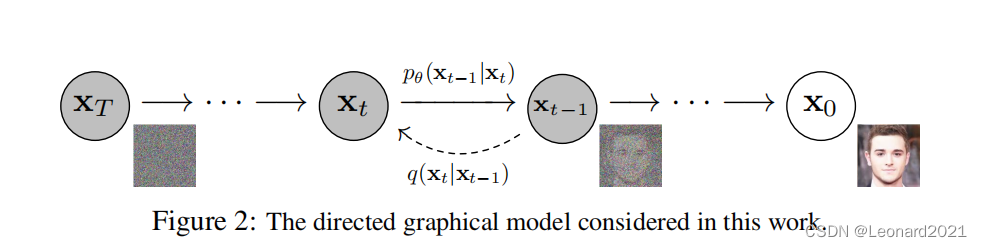
DDPM扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process)。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可以用来生成数据,可通过变分推断来进行建模和求解。在DDPM中,通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过
一、简介
DDPM扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process)。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可以用来生成数据,可通过变分推断来进行建模和求解。在DDPM中,通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。测试时,可以使用DDPM将随机采样的噪声传入模型中,通过学习去噪过程来生成数据。

二、实战
首先,下载安装指定的python包
pip install diffusers我使用的数据集为柑橘病害叶片数据集(未开源),三种类型,分别为黄龙病、缺镁、正常三种性状。

我使用数据集格式:(数据集不需要划分为train、val、test)
dataset_orgin
--Huanglong_disease
----0.jpg
----1.jpg
----~~~~~
--Magnesium_deficiency
----0.jpg
----1.jpg
----~~~~~
--Normal
----0.jpg
----1.jpg
----~~~~~新建python文件,用于训练 train_unconditional.py
import argparse
import inspect
import math
import os
from pathlib import Path
from typing import Optional
import torch
import torch.nn.functional as F
from accelerate import Accelerator
from accelerate.logging import get_logger
from datasets import load_dataset
from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version
from huggingface_hub import HfFolder, Repository, whoami
from torchvision.transforms import (
CenterCrop,
Compose,
InterpolationMode,
Normalize,
RandomHorizontalFlip,
Resize,
ToTensor,
)
from tqdm.auto import tqdm
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.10.0.dev0")
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # 设备
logger = get_logger(__name__)
def _extract_into_tensor(arr, timesteps, broadcast_shape):
"""
Extract values from a 1-D numpy array for a batch of indices.
:param arr: the 1-D numpy array.
:param timesteps: a tensor of indices into the array to extract.
:param broadcast_shape: a larger shape of K dimensions with the batch
dimension equal to the length of timesteps.
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
"""
if not isinstance(arr, torch.Tensor):
arr = torch.from_numpy(arr)
res = arr[timesteps].float().to(timesteps.device)
while len(res.shape) < len(broadcast_shape):
res = res[..., None]
return res.expand(broadcast_shape)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--dataset_name",
type=str,
default=r'D:\pyCharmdata\datasets_orgin\Huanglong_disease',#None
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that HF Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,#None
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=r'D:\pyCharmdata\datasets_orgin\Huanglong_disease',# None
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="ddpm-model-128",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--overwrite_output_dir", action="store_true")
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument(
"--resolution",
type=int,
default=128,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--eval_batch_size", type=int, default=1, help="The number of images to generate for evaluation."
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"The number of subprocesses to use for data loading. 0 means that the data will be loaded in the main"
" process."
),
)
parser.add_argument("--num_epochs", type=int, default=300)
parser.add_argument("--save_images_epochs", type=int, default=10, help="How often to save images during training.")
parser.add_argument(
"--save_model_epochs", type=int, default=10, help="How often to save the model during training."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="cosine",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--adam_beta1", type=float, default=0.95, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument(
"--adam_weight_decay", type=float, default=1e-6, help="Weight decay magnitude for the Adam optimizer."
)
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer.")
parser.add_argument(
"--use_ema",
action="store_true",
default=True,
help="Whether to use Exponential Moving Average for the final model weights.",
)
parser.add_argument("--ema_inv_gamma", type=float, default=1.0, help="The inverse gamma value for the EMA decay.")
parser.add_argument("--ema_power", type=float, default=3 / 4, help="The power value for the EMA decay.")
parser.add_argument("--ema_max_decay", type=float, default=0.9999, help="The maximum decay magnitude for EMA.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--hub_private_repo", action="store_true", help="Whether or not to create a private repository."
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--mixed_precision",
type=str,
default="fp16",#"no"
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--prediction_type",
type=str,
default="epsilon",
choices=["epsilon", "sample"],
help="Whether the model should predict the 'epsilon'/noise error or directly the reconstructed image 'x0'.",
)
parser.add_argument("--ddpm_num_steps", type=int, default=1000)
parser.add_argument("--ddpm_beta_schedule", type=str, default="linear")
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("You must specify either a dataset name from the hub or a train data directory.")
return args
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
if token is None:
token = HfFolder.get_token()
if organization is None:
username = whoami(token)["name"]
return f"{username}/{model_id}"
else:
return f"{organization}/{model_id}"
def main(args):
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with="tensorboard",
logging_dir=logging_dir,
)
model = UNet2DModel(
sample_size=args.resolution,
in_channels=3,
out_channels=3,
layers_per_block=2,
block_out_channels=(128, 128, 256, 256, 512, 512),
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D",
"DownBlock2D",
),
up_block_types=(
"UpBlock2D",
"AttnUpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)
accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
if accepts_prediction_type:
noise_scheduler = DDPMScheduler(
num_train_timesteps=args.ddpm_num_steps,
beta_schedule=args.ddpm_beta_schedule,
prediction_type=args.prediction_type,
)
else:
noise_scheduler = DDPMScheduler(num_train_timesteps=args.ddpm_num_steps, beta_schedule=args.ddpm_beta_schedule)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
augmentations = Compose(
[
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
CenterCrop(args.resolution),
RandomHorizontalFlip(),
ToTensor(),
Normalize([0.5], [0.5]),
]
)
if args.dataset_name is not None:
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
split="train",
)
else:
dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
def transforms(examples):
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
return {"input": images}
logger.info(f"Dataset size: {len(dataset)}")
dataset.set_transform(transforms)
train_dataloader = torch.utils.data.DataLoader(
dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
)
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
)
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler
)
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
ema_model = EMAModel(
accelerator.unwrap_model(model),
inv_gamma=args.ema_inv_gamma,
power=args.ema_power,
max_value=args.ema_max_decay,
)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
if args.hub_model_id is None:
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
else:
repo_name = args.hub_model_id
repo = Repository(args.output_dir, clone_from=repo_name)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if accelerator.is_main_process:
run = os.path.split(__file__)[-1].split(".")[0]
accelerator.init_trackers(run)
global_step = 0
for epoch in range(args.num_epochs):
model.train()
progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process)
progress_bar.set_description(f"Epoch {epoch}")
for step, batch in enumerate(train_dataloader):
clean_images = batch["input"]
# Sample noise that we'll add to the images
noise = torch.randn(clean_images.shape).to(clean_images.device)
bsz = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=clean_images.device
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
with accelerator.accumulate(model):
# Predict the noise residual
model_output = model(noisy_images, timesteps).sample
if args.prediction_type == "epsilon":
loss = F.mse_loss(model_output, noise) # this could have different weights!
elif args.prediction_type == "sample":
alpha_t = _extract_into_tensor(
noise_scheduler.alphas_cumprod, timesteps, (clean_images.shape[0], 1, 1, 1)
)
snr_weights = alpha_t / (1 - alpha_t)
loss = snr_weights * F.mse_loss(
model_output, clean_images, reduction="none"
) # use SNR weighting from distillation paper
loss = loss.mean()
else:
raise ValueError(f"Unsupported prediction type: {args.prediction_type}")
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
if args.use_ema:
ema_model.step(model)
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
if args.use_ema:
logs["ema_decay"] = ema_model.decay
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
progress_bar.close()
accelerator.wait_for_everyone()
# Generate sample images for visual inspection
if accelerator.is_main_process:
if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
pipeline = DDPMPipeline(
unet=accelerator.unwrap_model(ema_model.averaged_model if args.use_ema else model),
scheduler=noise_scheduler,
)
generator = torch.Generator(device=pipeline.device).manual_seed(0)
# run pipeline in inference (sample random noise and denoise)
images = pipeline(
generator=generator,
batch_size=args.eval_batch_size,
output_type="numpy",
).images
# denormalize the images and save to tensorboard
images_processed = (images * 255).round().astype("uint8")
accelerator.trackers[0].writer.add_images(
"test_samples", images_processed.transpose(0, 3, 1, 2), epoch
)
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
# save the model
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message=f"Epoch {epoch}", blocking=False)
accelerator.wait_for_everyone()
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
开始训练前对argparse部分代码修改:
将"--dataset_name"部分修改为你使用的数据集的文件路径位置;
将"--train_data_dir"部分修改为你使用的数据集的文件路径位置;
将"--output_dir"部分修改为你训练得到模型文件夹的输出名称;
将"--resolution"部分修改为你想要后续生成的假图像的大小分辨率,比较考验电脑算力,可以自行尝试不同分辨率的,可以从64*64不断往上尝试,比如:64*64、128*128、256*256、512*512等
将"--train_batch_size"、"--eval_batch_size"、"--dataloader_num_workers"这三个参数与训练是否能继续息息相关,DDPM模型较大,对电脑算力要求高,显存不足时需要调小这三个参数才能正常运行程序;
将"--num_epochs"修改为你想要训练的轮数,不同数据集要求不同,数据集简单的100轮可能可以搞定,数据集复杂得自行尝试确定轮数。
总而言之,看菜吃饭,算力充足的可以任意调整,算力有限则需要慢慢调试参数进行运行训练。
新建python文件,用于生产“假”图像
generate.py
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
import os
model_id = "ddpm-model-512-Huanglong_disease"
# 生成的图像放的位置
img_path = 'results' + '/' + model_id + '-img'
if not os.path.exists(img_path): os.mkdir(img_path)
device = "cuda"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(
model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
ddpm.to(device)
for i in range(1000):
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
# save image
# 不修改格式
image.save(os.path.join(img_path,f'{i}.png'))
# 改成单通道
#image.convert('L').save(os.path.join(img_path, f'{i}.png'))
# 看看跑到哪里了
if i % 10 == 0: print(f"i={i}")
model_id为项目根目录下,训练好的模型文件夹名称。
修改for i in range()的循环次数,可以指定为你想要生成的合成图像的数量
生成彩色图像则使用
image.save(os.path.join(img_path,f'{i}.png'))生成黑白图像则使用
#image.convert('L').save(os.path.join(img_path, f'{i}.png'))两种各自使用,需要屏蔽另外一种的代码。
部分生成的图像:
黄龙病

缺镁:

正常:

此外,由于是train_unconditional,当使用多个种类的数据集一起训练时,生成的图像类型不可控(即不能做到生成指定类型的图像数据),且由于扩散模型训练的是扩散(去噪)的模型,本身不带有鉴别的功能,训练生成的彩色合成图像可能带有一定的色差,我的建议是,先使用ResNet50等分类网络对原始数据集进行训练,得到一个类似于GAN算法中鉴别器的模型,再对生成好的合成图像进行分类并且筛选掉质量较差的图像。
三、小结
总的来说,对比效果实现数据扩容的合成图像方向的算法GAN,GAN是同时训练生成器和鉴别器,让两者相互作用进而实现拟合,但是大多数情况下GAN算法很难训练到很高程度的拟合,且常常会出现梯度消失或者梯度爆炸等不稳定的情况。
DDPM(扩散模型)训练的是模型对图像的去噪能力,比较容易拟合,训练得到的模型,输入无序的高斯噪声再执行模型的去噪能力,来实现“生产”合成图像的功能。优点是训练得到的图像精度较高,与原始图像更相似;缺点是模型训练需要的算力较大,且生成合成图像所需时间较长。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果本文对你有帮助,欢迎一键三连!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)