ASF-YOLO:一种基于注意尺度序列融合的细胞实例分割YOLO模型
随着样本制备技术和显微成像技术的快速发展,细胞图像的定量处理和分析在医学、细胞生物学等领域发挥着重要作用。基于卷积神经网络(CNN),可以通过神经网络训练学习不同细胞图像的特征信息,具有很强的泛化性能。两阶段的R-CNN系列[1,2,3]及其一阶段变体[4,5]是实例分割任务的经典CNN基础框架。在最近的研究中,You Only Look Once(YOLO)系列[6,7,8,9]已经成为实时实例
摘要
我们提出了一种基于注意力尺度序列融合的You Only Look Once(YOLO)框架(ASF-YOLO),该框架结合了空间和尺度特征,用于准确快速的细胞实例分割。在YOLO分割框架的基础上,我们采用尺度序列特征融合(SSFF)模块增强网络的多尺度信息提取能力,并采用三重特征编码器(TPE)模块融合不同尺度的特征图以增加详细信息。我们进一步引入通道和位置注意力机制(CPAM),将SSFF和TPE模块集成在一起,专注于信息通道和与空间位置相关的小对象,以提高检测和分割性能。在两个细胞数据集上的实验验证表明,所提出的ASF-YOLO模型具有显著的分割精度和速度。它在2018年数据科学碗数据集上实现了0.91的box mAP、0.887的mask mAP和47.3 FPS的推理速度,优于最先进的方法。源代码可在https://github.com/mkang315/ASF-YOLO上获得。
关键词:医学图像分析、小对象分割、You Only Look Once(YOLO)、序列特征融合、注意力机制
1、简介
随着样本制备技术和显微成像技术的快速发展,细胞图像的定量处理和分析在医学、细胞生物学等领域发挥着重要作用。基于卷积神经网络(CNN),可以通过神经网络训练学习不同细胞图像的特征信息,具有很强的泛化性能。两阶段的R-CNN系列[1,2,3]及其一阶段变体[4,5]是实例分割任务的经典CNN基础框架。在最近的研究中,You Only Look Once(YOLO)系列[6,7,8,9]已经成为实时实例分割中速度最快、最准确的模型之一。由于一阶段的设计理念和特征提取能力,YOLO实例分割模型相比两阶段分割模型具有更好的精度和速度。然而,细胞实例分割的困难在于细胞小、密集、重叠以及边界模糊,导致细胞分割精度较差。细胞实例分割需要对细胞图像中的不同类型的对象进行准确细致的分割。如图1所示,不同类型的细胞图像在颜色、形态、纹理等特征信息上存在很大的差异,这是由于细胞形态、制备方法和成像技术的差异造成的。

典型的YOLO框架架构由三个主要部分组成:backbone、neck和head。YOLO的backbone网络是一个卷积神经网络,用于提取不同粒度的图像特征。Cross Stage Partial[10] Darknet具有53个卷积层(CSPDarknet53)[11],是从YOLOv4[12]修改而来的,并设计为YOLOv 5[8]的backbone网络,其中包含C3(包括3个卷积层的CSP瓶颈)和ConvBNSiLU模块。在YOLOv8[9]的backbone中,C3模块被C2f(包括2个带有shortcut的卷积层的CSP瓶颈)模块取代,这是与YOLOv5的唯一区别。如图2所示,YOLOv5和YOLOv8的backbone中的级别1-5特征提取分支{P1, P2, P3, P4, P5}对应于与这些特征图中的每一个相关联的YOLO网络的输出。YOLOv5 v7和YOLOv8是第一个基于YOLO的主流架构,除了检测和分类外,还可以处理分割任务。在YOLOv5的特征提取阶段,使用了由多个C3模块堆叠的CSPDarkNet53 backbone网络,然后将backbone网络的三个有效特征分支P3、P4和P5作为Feature Pyramid Network(FPN)结构的输入,在neck部分构建多尺度融合结构。在特征层的解码过程中,使用与backbone网络的有效特征分支相对应的三个不同大小的head进行对象的边界框预测。对P3特征进行上采样后,进行逐像素解码,作为目标的分割掩模预测,完成目标的实例分割。在分割head中,三个尺度的特征输出三个不同的锚框,mask proto模块负责输出原型掩模,经过处理得到用于实例分割任务的检测框和分割掩模。

本文提出了一种针对细胞图像的一阶段实例分割模型,该模型在You Only Look Once(YOLO)框架中集成了注意力尺度序列融合(ASF-YOLO)。首先,利用CSPDarknet53 backbone网络在特征提取阶段从细胞图像中提取多维特征信息。针对细胞实例分割问题,我们在neck部分提出了新颖的网络设计。本文的贡献总结如下:
1)针对不同类型细胞的多尺度问题和小细胞的目标检测和分割问题,我们设计了尺度序列特征融合(SSFF)模块和三重特征编码器(TFE)模块,以在路径聚合网络(PANet)[13]结构中融合从backbone中提取的多尺度特征图。
2)然后,我们设计了通道和位置注意力机制(CPAM),以集成来自SSFF和TFC模块的特征信息,进一步提高实例分割精度。
3)我们在训练阶段利用EIoU [14]通过最小化边界框和锚框的宽度和高度之间的差异来优化边界框位置损失,在后处理阶段使用Soft NonMaximum Suppression(Soft-NMS)[15]来改善密集重叠细胞问题。
4)我们将提出的ASF-YOLO模型应用于密集重叠和各种细胞类型的具有挑战性的实例分割任务。据我们所知,这是首次利用基于YOLO的模型进行细胞实例分割的工作。对两个基准细胞数据集的评估表明,与其他最先进的方法相比,该方法的检测精度和速度更高。
2、相关工作
2.1、细胞实例分割
细胞实例分割可以进一步帮助完成图像中的细胞计数任务,而细胞图像的语义分割则无法完成。深度学习方法提高了自动细胞核分割的准确性[16]。Johnson等人[17]、Jung等人[18]、Fujita等人[19]和Bancher等人[20]提出了基于Mask R-CNN[2]的细胞同时检测和分割的改进方法。Yi等人[21]和Cheng等人[22]利用Single-Shot multi-box Detector (SSD)[23]方法检测和分割神经细胞实例。Mahbod等人[24]采用基于U-Net[25]的语义分割算法模型进行细胞核分割。具有注意力机制的混合模型SSD和U-Net[19]或U-Net和Mask R-CNN[26]在细胞实例分割数据集上取得了一些提升。BlendMask[27]是一个具有扩张卷积聚合模块和上下文信息聚合模块的细胞核实例分割框架。Mask R-CNN是一个两阶段的对象分割框架,其速度较慢。SSD、U-Net和BlendMask是统一的端到端(即一阶段)框架,但在分割密集和小细胞时性能较差。
2.2、改进的YOLO用于实例分割
最近针对实例分割任务的YOLO改进主要集中在注意力机制、改进的backbone或网络以及损失函数上。Squeeze-and-Excitation(SENet)[28]块被集成到改进的YOLACT[6]中,用于识别显微图像中的瘤胃原生动物[29]。YOLOMask[30]、PR-YOLO[31]和YOLO-SF[32]增强了YOLOv5[8]和YOLOv7-Tiny[33]的卷积块注意力模块(CBAM)[34]。将有效的特征提取模块添加到改进的主干网络中,使YOLO特征提取过程更加高效[35,36]。YOLO-CORE[37]通过设计的由极坐标距离损失和扇形损失组成的多阶约束,使用显式和直接轮廓回归有效地增强了实例的掩模。此外,混合模型另一个YOLOMask[38]和YUSEG[39]结合了优化的YOLOv4[12]和原始的YOLOv5s与语义分割U-Net网络,以确保实例分割的准确性。
3、提出的ASF-YOLO模型
3.1、整体架构
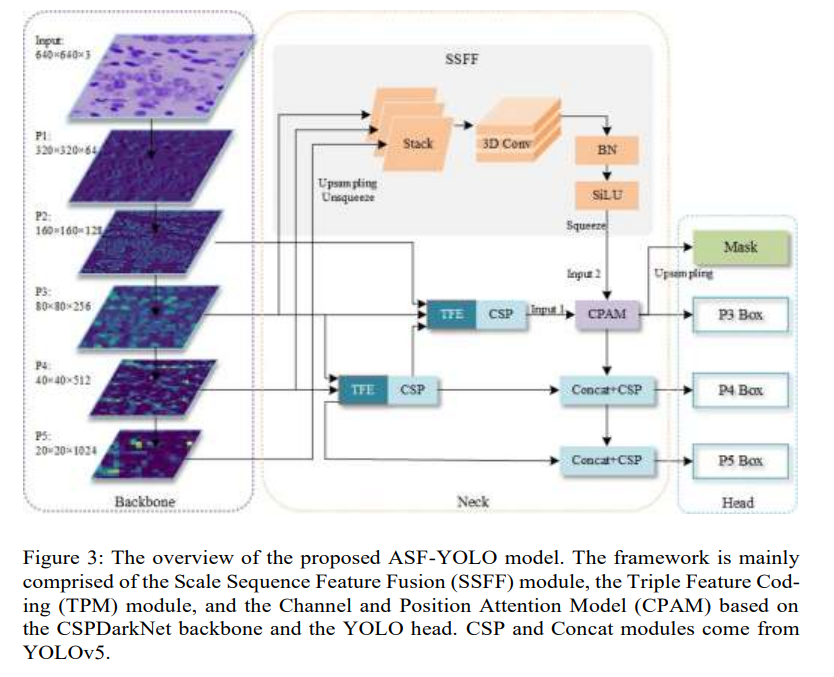
图3显示了提出的ASF-YOLO框架的概述,该框架结合了空间和多尺度特征用于细胞图像实例分割。我们开发了一种新颖的特征融合网络架构,由两个主要组件网络组成,可以为小对象分割提供互补信息:(1) SSFF模块,它结合了来自多个尺度的图像的全局或高级语义信息,以及(2) TFE模块,它可以捕获小目标对象的局部精细细节。局部和全局特征信息的集成可以产生更准确的分割图。我们执行从骨干网络中提取的
P
3
、
P
4
\mathrm{P}_{3}、\mathrm{P}_{4}
P3、P4 和
P
5
\mathrm{P}_{5}
P5 的输出特征的融合。首先,SSFF模块被设计为有效地融合
P
3
、
P
4
\mathrm{P}_{3}、\mathrm{P}_{4}
P3、P4 和
P
5
\mathrm{P}_{5}
P5 的特征图,这些特征图捕获了覆盖不同细胞类型的各种大小和形状的不同空间尺度。在
S
S
F
F
\mathrm{SSFF}
SSFF 中,
P
3
、
P
4
\mathrm{P}_{3}、\mathrm{P}_{4}
P3、P4 和
P
5
\mathrm{P}_{5}
P5 特征图被归一化为相同的大小,进行上采样,然后堆叠在一起作为输入到
3
D
3 \mathrm{D}
3D 卷积以结合多尺度特征。其次,开发TFE模块以增强对密集细胞的小目标检测,通过在空间维度上拼接三种不同大小(大、中、小)的特征来捕获有关小对象的详细信息。TFE模块的详细特征信息然后通过PANet结构集成到每个特征分支中,然后与SSFF模块的多尺度信息结合到
P
3
\mathrm{P}_{3}
P3 分支中。我们在
P
3
\mathrm{P}_{3}
P3 分支中进一步引入了通道和位置注意机制(CPAM),以利用高级多尺度特征和详细特征。CPAM中的通道和位置注意机制可以分别捕获信息通道并细化与小对象(如细胞)相关的空间定位,从而提高其检测和分割精度。

3.2、尺度序列特征融合模块
对于细胞图像的多尺度问题,在现有文献中,特征金字塔结构被用于特征融合,其中仅使用求和或拼接来融合金字塔特征。然而,各种特征金字塔网络的结构不能有效地利用所有金字塔特征图之间的相关性。我们提出了一种新颖的尺度序列特征融合方法,可以更好地将深层特征图的高维信息与浅层特征图的详细信息相结合,其中在图像下采样过程中图像的大小发生变化,但尺度不变特征保持不变。尺度空间是沿着图像的尺度轴构建的,它不仅代表一个尺度,而且代表一个对象可以具有的各种尺度的范围[40]。尺度意味着图像的细节。模糊的图像可能会丢失细节,但可以保留其图像的结构特征。通过
F
o
(
w
,
h
)
=
G
o
(
w
,
h
)
×
f
(
w
,
h
)
(1)
F_{o}(w, h)=G_{o}(w, h) \times f(w, h) \tag{1}
Fo(w,h)=Go(w,h)×f(w,h)(1)
G
o
(
w
,
h
)
=
1
2
π
σ
2
e
−
(
w
2
+
h
2
)
/
2
σ
2
(2)
G_{o}(w, h)=\frac{1}{2 \pi \sigma^{2}} e^{-\left(w^{2}+h^{2}\right) / 2 \sigma^{2}} \tag{2}
Go(w,h)=2πσ21e−(w2+h2)/2σ2(2)
其中 f ( w , h ) f(w,h) f(w,h)表示宽度为w、高度为h的二维输入图像。 F o ( w , h ) F_{o}(w,h) Fo(w,h)是由一系列卷积使用二维高斯滤波器 G 0 ( w , h ) G_{0}(w,h) G0(w,h)进行平滑处理生成的。σ是用于卷积的二维高斯滤波器的标准差缩放参数。
这些生成的图像具有相同的分辨率和不同的尺度。因此,不同大小的特征图可以看作是尺度空间,不同分辨率的有效特征图可以调整到相同的分辨率进行拼接。受二维和三维卷积操作对多个视频帧的启发[41],我们将不同尺度的特征图水平堆叠,并使用三维卷积提取它们的尺度序列特征。由于高分辨率特征图级别 P 3 \mathrm{P}_{3} P3 包含大部分对于小目标检测和分割至关重要的信息,SSFF模块是基于 P 3 \mathrm{P}_{3} P3 级别设计的。如图3所示,提出的SSFF模块由以下组件组成:
- 使用1x卷积改变 P 4 \mathrm{P}_{4} P4 和 P 5 \mathrm{P}_{5} P5 特征级别的通道数为256。
- 使用最近邻插值方法[42]将其大小调整为 P 3 \mathrm{P}_{3} P3 级别的大小。
- 使用unsqueeze方法增加每个特征层的维度,将其从三维张量[高度,宽度,通道]更改为四维张量[深度,高度,宽度,通道]。
- 然后沿深度维度拼接4D特征图,以形成用于后续卷积的3D特征图。
- 最后,使用3D卷积、3D批量归一化和SiLU[43]激活函数完成尺度序列特征提取。
3.3、三重特征编码模块
为了识别密集重叠的小物体,可以通过放大图像来参考和比较不同尺度的形状或外观变化。由于骨干网络的不同特征层具有不同的大小,常规的FPN融合机制仅对小尺寸的特征图进行上采样,然后将其拆分或添加到前一层的特征中,忽略了较大尺寸特征层的丰富详细信息。因此,我们提出了TFE模块,该模块将大、中、小特征进行拆分,添加大尺寸特征图,并进行特征放大以提高详细特征信息。

图4展示了TFE模块的结构。在特征编码之前,首先调整特征通道的数量,使其与主尺度特征一致。在对大尺寸特征图(Large)进行处理后,其通道数调整为 1C ,然后使用最大池化+平均池化的混合结构进行下采样,这有助于保留高分辨率特征和细胞图像的有效性和多样性。对于小尺寸特征图(Small),也使用卷积模块来调整通道数,然后使用最近邻插值方法进行上采样。这有助于保持低分辨率图像的局部特征的丰富性,并防止小目标特征信息的丢失。最后,将三个大小相同的大、中、小尺寸的特征图进行一次卷积,然后在通道维度上进行拼接,如下所示。
F
T
F
E
=
Concat
(
F
l
,
F
m
,
F
s
)
(3)
F_{T F E}=\operatorname{Concat}\left(F_{l}, F_{m}, F_{s}\right) \tag{3}
FTFE=Concat(Fl,Fm,Fs)(3)
其中 F T F E F_{T F E} FTFE表示TFE模块输出的特征图。 F l 、 F m F_{l}、F_{m} Fl、Fm和 F s F_{s} Fs分别表示大、中和小尺寸的特征图。 F T F E F_{T F E} FTFE由 F l 、 F m F_{l}、F_{m} Fl、Fm和 F s F_{s} Fs的拼接得到。 F T F E F_{T F E} FTFE具有与 F m F_{m} Fm相同的分辨率,并且通道数是 F m F_{m} Fm的三倍。
3.4、通道和位置注意力机制
为了提取不同通道中包含的代表性特征信息,我们提出了CPAM,以整合详细特征信息和多尺度特征信息。CPAM的架构如图5所示。它由一个通道注意力网络组成,该网络接收来自TFE(输入1)的输入,以及一个位置注意力网络,该网络接收来自通道注意力网络输出和SSFF(输入2)的叠加的输入。

输入1用于通道注意力网络,是经过PANet的特征图,包含TFE的详细特征。SENet[28]通道注意力块首先对每个通道独立地使用全局平均池化,并使用两个全连接层和一个非线性Sigmoid函数来生成通道权重。这两个全连接层旨在捕获非线性跨通道交互,这涉及到降低维度以控制模型的复杂性,但维度降低给通道注意力预测带来了副作用,并且捕获所有通道之间的依赖关系既无效又不需要。我们引入了一种不进行维度降低的注意力机制,以有效地捕获跨通道交互。在不降低维度的通道级全局平均池化之后,通过考虑每个通道及其k个最近邻居来捕获局部跨通道交互,即使用大小为k的1D卷积来实现,其中卷积核大小k表示局部跨通道交互的覆盖范围,即有多少邻居参与一个通道的注意力预测。为了获得最佳覆盖范围,可以在不同的网络结构和不同数量的卷积模块中手动调整k,但这很繁琐。由于卷积核大小k与通道维度C成正比,因此可以看到k和C之间存在映射关系。通道维度通常是2的指数,映射关系如下。
C
=
ψ
(
k
)
=
2
(
γ
×
k
−
b
)
(4)
C=\psi(k)=2^{\left(\gamma^{\times} k-b\right)} \tag{4}
C=ψ(k)=2(γ×k−b)(4)
为了在具有较大通道数的层中实现更多的跨通道交互,可以通过一个函数来调整一维卷积的卷积核大小。卷积核大小k可以通过以下公式计算:
k
=
Ψ
(
C
)
=
∣
log
2
(
C
)
)
+
b
γ
∣
odd
(5)
k=\Psi(C)=\left|\frac{\left.\log _{2}(C)\right)+b}{\gamma}\right|_{\text {odd }} \tag{5}
k=Ψ(C)=
γlog2(C))+b
odd (5)
其中 ∣ \mid ∣. ∣ \mid ∣ odd 表示最近邻居的奇数个。γ 的值设置为2,b 设置为1。根据上述非线性映射关系,高价值通道的交换时间较长,而低价值通道的交换时间较短。因此,通道注意力机制可以对多个通道特征进行更深入的挖掘。
将通道注意力机制的输出与SSFF(输入2)的特征相结合作为位置注意力网络的输入,提供了互补的信息,以从每个单元中提取关键的位置信息。与通道注意力机制相比,位置注意力机制首先根据宽度和高度将输入特征图分为两个部分,然后分别在轴(pw 和 ph)上进行处理以进行特征编码,最后合并以生成输出。
更准确地说,输入特征图在水平轴(pw)和垂直轴(ph)上进行池化,以保留特征图的空间结构信息,其计算方法如下:

其中 w 和 h 分别是输入特征图的宽度和高度。 E ( w , j ) E(w, j) E(w,j) 和 E ( i , h ) E(i, h) E(i,h) 是位置 ( i , j ) (i, j) (i,j) 在输入特征图中的值。
在生成位置注意力坐标时,对水平和垂直轴应用连接和卷积操作:
P
(
a
w
,
a
h
)
=
Conv
[
Concat
(
p
w
,
p
h
)
]
(8)
P\left(a_{w}, a_{h}\right)=\operatorname{Conv}\left[\operatorname{Concat}\left(p_{w}, p_{h}\right)\right] \tag{8}
P(aw,ah)=Conv[Concat(pw,ph)](8)
其中 P ( a w , a h ) P(a_w, a_h) P(aw,ah) 表示位置注意力坐标的输出,Conv 表示 1 × 1 1 \times 1 1×1 卷积,Concat 表示连接。
在分割注意力特征时,会产生位置依赖性特征映射的配对,如下所示:
s
w
=
Split
(
a
w
)
(9)
s_{w} = \text{Split}(a_{w}) \tag{9}
sw=Split(aw)(9)
s
h
=
Split
(
a
h
)
s_{h} = \text{Split}(a_{h})
sh=Split(ah)
其中
s
w
s_{w}
sw 和
s
h
s_{h}
sh 分别是分割输出的宽度和高度。
CPAM的最终输出由以下公式定义:
F
C
P
A
M
=
E
×
s
w
×
s
h
(10)
F_{CPAM} = E \times s_{w} \times s_{h} \tag{10}
FCPAM=E×sw×sh(10)
其中 E 代表通道注意力和位置注意力的权重。
3.5、锚框优化
通过优化损失函数和非极大值抑制(NMS),三个检测头的锚框得到改进,以准确完成不同大小细胞图像的实例分割任务。
交并比(IoU)通常用作锚框损失函数,通过计算标记边界框和预测框的重叠程度来确定收敛。然而,传统的IoU损失无法反映目标框和锚框之间的距离和重叠。为了解决这些问题,提出了GIoU [44]、DIoU和CIoU [45]。CIoU引入了基于DIoU Loss的影响因子,被YOLOv5和YOLOv8使用。在考虑重叠面积和中心点距离对损失函数的影响的同时,还考虑了标记框和预测框的宽度与高度(即纵横比)对损失函数的影响。然而,它只反映了纵横比的不同,而不是标记框和预测框宽度与高度之间的真实关系。EIoU [14]最小化了目标框和锚框在宽度和高度的差异,这可以改善小物体的定位效果。EIoU损失可以分为3部分:IoU损失函数L_{I 0 U}、距离损失函数L_{d i s}和纵横比损失函数L_{a s p},其公式如下:
L
E
I
o
U
=
L
I
o
U
+
L
d
i
s
+
L
a
s
p
=
1
−
I
o
U
+
ρ
2
(
b
,
b
g
t
)
w
c
2
+
h
c
2
+
ρ
2
(
w
,
w
g
t
)
w
c
2
+
ρ
2
(
h
,
h
g
t
)
h
c
2
(12)
L_{E I o U}=L_{I o U}+L_{d i s}+L_{a s p}=1-I o U+\frac{\rho^{2}\left(b, b_{g t}\right)}{w_{c}^{2}+h_{c}^{2}}+\frac{\rho^{2}\left(w, w_{g t}\right)}{w_{c}^{2}}+\frac{\rho^{2}\left(h, h_{g t}\right)}{h_{c}^{2}} \tag{12}
LEIoU=LIoU+Ldis+Lasp=1−IoU+wc2+hc2ρ2(b,bgt)+wc2ρ2(w,wgt)+hc2ρ2(h,hgt)(12)
其中 ρ ( ⋅ ) = ∥ b − b g t ∥ 2 \rho(\cdot)=\left\|b-b_{g t}\right\|_{2} ρ(⋅)=∥b−bgt∥2 表示欧几里得距离, b b b 和 b g t b_{g t} bgt 分别表示 B 和 B g t B_{g t} Bgt 的中心点; b g t b_{g} t bgt, w g t w_{g} t wgt, 和 h g t h_{g} t hgt 是真实框的中心点 b、宽度和高度; w c w_{c} wc 和 h c h_{c} hc 表示覆盖两个框的最小包围盒的宽度和高度。与 CIoU 相比,EIoU 不仅加快了预测框的收敛速度,而且提高了回归精度。因此,我们在头部部分选择 EIoU 来代替 CIoU。
为了消除重复的锚框,检测模型会同时输出多个检测边界,特别是当真实物体周围存在许多高置信度的检测边界时。经典 NMS [46] 算法的原理是获取局部最大值。如果当前边界框与得分最高的检测框之间的差异大于阈值,则直接将边界框的分数设置为零。为了克服由经典 NMS 引起的错误,我们采用 Soft-NMS [15],它使用高斯函数作为权重函数来降低预测边界的分数,以替换原始分数而不是直接将其设置为零,从而修改了边界框的错误规则。
4、实验
4.1、数据集
我们评估了所提出的ASF-YOLO模型在两个细胞图像数据集上的性能:DSB2018和BCC数据集。2018年数据科学碗(DSB2018)数据集[47]包含670张带有分割遮罩的细胞核图像,旨在评估算法在细胞类型、放大倍数和成像方式(明场与荧光)变化方面的通用性。每个遮罩包含一个核,遮罩之间没有重叠(没有像素属于两个遮罩)。该数据集按8:2的比例随机分为训练集和测试集。训练集和测试集的样本大小分别为536和134张图像。
乳腺癌细胞(BCC)数据集[48]是从加州大学圣塔芭芭拉分校生物图像信息中心收集的。它包括160张用于乳腺癌细胞检测的苏木素-伊红染色组织病理学图像,并附有相关联的地面真实数据。该数据集被随机分为128张图像(80%)作为训练集,32张图像(20%)作为测试集。
4.2、实现细节
实验是在NVIDIA GeForce 3090(24G)GPU和PyTorch 1.10、Python 3.7、CUDA 11.3依赖项上实现的。我们使用了预训练的COCO数据集的初始权重。输入图像大小为640640。训练数据的批量大小为16。训练过程持续100个epoch。我们使用随机梯度下降(SGD)作为优化函数来训练模型。SGD的超参数设置为动量0.9、初始学习率0.001和权重衰减0.0005。
4.3、定量结果
表1显示了与Mask R-CNN [2]、Cascade Mask R-CNN [3]、SOLO [4]、SOLOv2 [5]、YOLACT [6]、Mask R-CNN with Swin Transformer backbone (Mask RCNN Swin T)、YOLOv5l-seg v7.o [8]和YOLOv8l-seg [9]等其他经典和最先进的方法相比,所提出的ASF-YOLO在DSB2018数据集上的性能比较。

我们的模型参数数量为46.18M,达到了最高的准确性,Box m A P 50 mAP_{50} mAP50 为0.91,Mask m A P 50 mAP_{50} mAP50 为0.887,推理速度达到了47.3帧每秒(FPS),这是最佳性能。由于图像输入大小为800×1200,使用Swin Transformer骨干网络的Mask R-CNN的准确性和速度都不高。我们的模型还超过了经典的单阶段算法SOLO和YOLACT。
我们提出的模型在BCC数据集上也实现了最佳的实例分割性能,如表2所示。实验验证表明,ASF-YOLO具有对不同数据集的通用性,并可用于检测不同类型的细胞。

4.4、定性结果
图6提供了对不同方法在DSB2018数据集样本图像上进行细胞分割的视觉比较。通过使用TFC模块提高小目标检测性能,ASF-YOLO在单通道中对于密集和小对象的细胞图像具有良好的召回值。通过使用SSFF模块增强多尺度特征提取性能,ASF-YOLO在复杂背景下对于大尺寸的细胞图像也具有很好的分割准确性。这表明我们的方法对于不同细胞类型具有良好的通用性。从图6(a)和(b)可以看出,每个模型都取得了很好的结果,因为细胞图像相对简单。从图6©和(d)可以看出,由于两阶段算法的设计原理,Mask R-CNN具有较高的误检率。SOLO存在许多漏检,而YOLOv5l-seg无法分割边界模糊的细胞。

4.5、消融实验
我们对所提出的ASF-YOLO模型进行了一系列广泛的消融实验。
4.5.1、提出方法的效果
表3显示了每个提出模块在提高分割性能方面的贡献。使用YOLOv5l-seg中的Soft-NMS可以克服由于密集小对象的相互遮挡而导致的错误抑制问题,并提供性能改进。EIoU损失函数提高了小目标边界框的效果,提高了1.8%的
m
A
P
50
:
95
mAP_{50:95}
mAP50:95。SSFF、TFC和CPAM模块通过解决细胞图像的小目标实例分割问题,有效地提高了模型性能。

4.5.2、注意力机制的效果
与通道注意力SENet、通道和空间注意力CBAM以及空间注意力CA[49]相比,所提出的CPAM注意力机制提供了更好的性能,尽管计算量和参数略有增加。

图7显示了在不同注意力模块中使用的ASF-YOLO模型的分割结果的视觉化。所提出的CPAM具有更好的通道和位置特征信息,并从原始图像中挖掘了更丰富的特征。
4.5.3、后主干中的卷积模块效果
表5显示,当在所提出模型的骨干中用YOLOv8的C2f模块替换YOLOv5的C3模块时,后主干中C2f模块的性能在两个数据集上均有所下降。

5、结论
我们开发了一种用于细胞图像分析的准确且快速的实例分割模型ASF-YOLO,它融合了空间和尺度特征来进行细胞图像的检测和分割。我们在YOLO框架中引入了几个新颖的模块。SSFF和TFE模块增强了多尺度和小目标实例分割性能。通道和位置注意力机制进一步挖掘了这两个模块的特征信息。广泛的实验结果表明,我们提出的方法能够处理各种细胞图像的实例分割任务,并显著提高了原始YOLO模型在处理小而密集物体时的细胞分割准确性。我们的方法在细胞实例分割方面在准确性和推理速度方面都大大超过了当前最先进的方法。由于本文中的数据集规模较小,模型的泛化性能需要进一步改进。此外,在消融实验中讨论了ASF-YOLO中每个模块的有效性,这为进一步改进提供了研究依据。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)