20.BeautifulSoup库的安装及导入
库是Python的一个解析文档库。库提供了一些简单的方法来遍历解析HTML和XML文档,并提供了一些方便的方法来搜索和操作文档中的数据。库可以帮助我们快速而方便地从网页中提取所需的信息,例如标题、链接、段落等。【官方网站】
文章目录
1.BeautifulSoup库简介
BeautifulSoup库是Python的一个解析文档库。
BeautifulSoup库提供了一些简单的方法来遍历解析HTML和XML文档,并提供了一些方便的方法来搜索和操作文档中的数据。
BeautifulSoup库可以帮助我们快速而方便地从网页中提取所需的信息,例如标题、链接、段落等。
【官方网站】
https://www.crummy.com/software/BeautifulSoup/
2.BeautifulSoup库的安装
BeautifulSoup是Python的第三方库,使用前需要先进行安装。
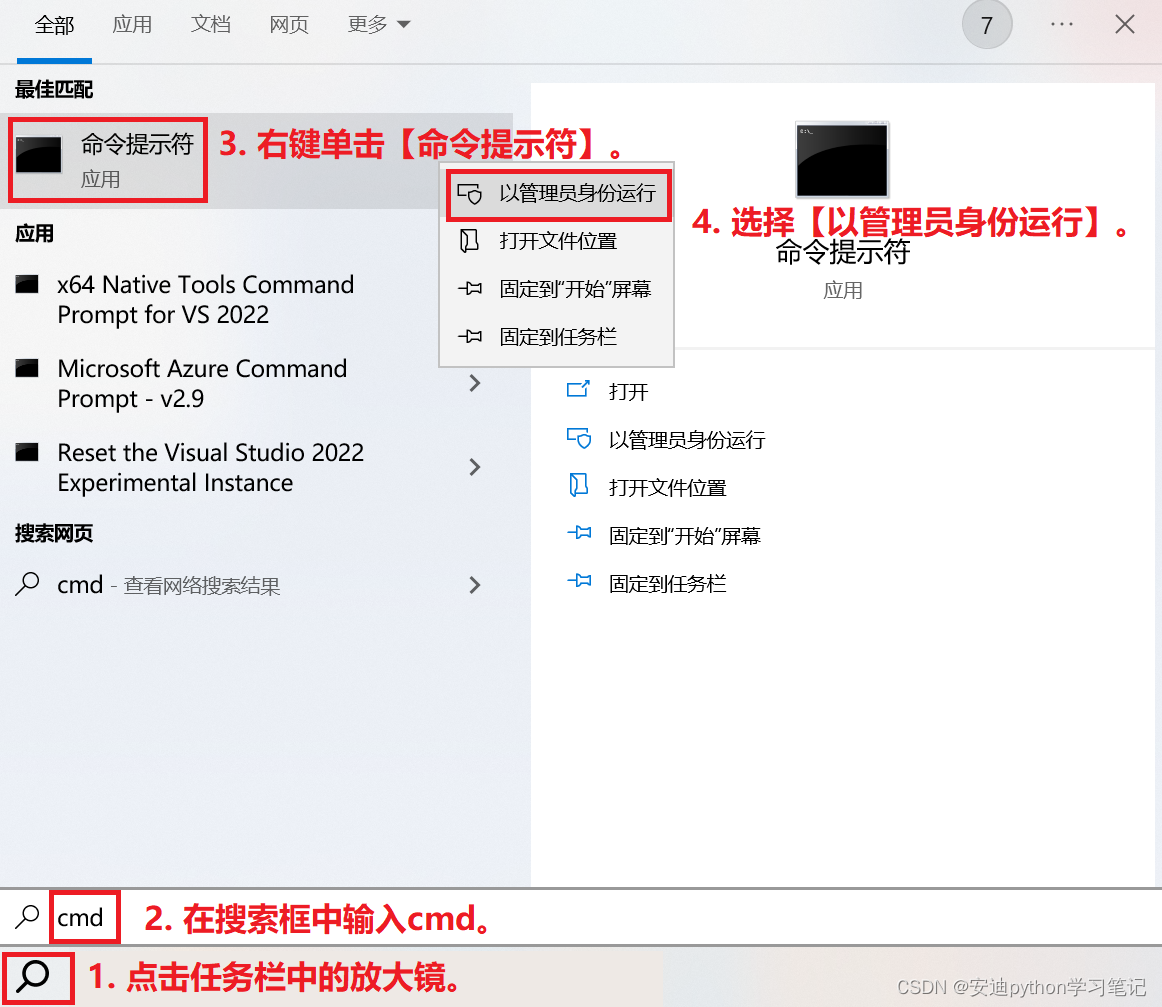
【以win10系统为例】
- 点击任务栏中的
放大镜。 - 在搜索框中输入cmd。
- 右键单击【命令提示符】。
- 选择【以管理员身份运行】。

- 在【命令提示符】界面输入下面的安装命令。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ beautifulsoup4
注意这里安装的库名为beautifulsoup4,而不是BeautifulSoup。
beautifulsoup4中最后面的数字4表示库的版本。
【命令解析】
install [ɪnˈstɔːl]:安装。
pip: 是Python的包管理工具,用于安装、升级和卸载Python包。install: 是pip的一个子命令,用于安装Python包。-i: 是pip install的一个选项,用于指定包的索引地址。https://pypi.tuna.tsinghua.edu.cn/simple/: 是一个包的索引地址,指定了从该地址下载包,可以替换成其它地址。beautifulsoup4是库名,这里替换成你要安装的任何库名。- 库名和前面的索引地址之间有1个空格。
- 出现【Successfully installed beautifulsoup4…】表示安装成功。

3.BeautifulSoup和beautifulsoup4的区别
BeautifulSoup和beautifulsoup4实际上是同一个库的不同版本。
BeautifulSoup是一个用于解析HTML和XML文档的Python库,它提供了一种简单的方式来遍历文档树、搜索特定的元素以及对文档进行修改。
BeautifulSoup最初由Leonard Richardson开发,目前最新的版本是3.2.2。
beautifulsoup4是BeautifulSoup的第四个主要版本,也是目前最新的版本。
它在功能上与之前的版本相似,但有一些改进和新增的功能。
beautifulsoup4支持更多的解析器,包括Python标准库中的html.parser、lxml、html5lib等。
此外,beautifulsoup4还提供了一些新的方法和属性,使得解析和处理文档更加方便。
因此,如果你要使用BeautifulSoup库,建议使用最新的beautifulsoup4版本,以获得更好的功能和性能。
4.获取网页源代码知识回顾
【要访问的网页】
http://python123.io/ws/demo.html
4.1 手动获取网页的源代码
- 打开浏览器,在网页中输入上面的网址。
- 鼠标右键点击【查看网页源代码】。

得到的网页源代码如下所示:

4.2 requests库获取网页的源代码
【代码示例】
import requests
url = 'http://python123.io/ws/demo.html'
# r是变量名,数据类型为Response对象
r = requests.get(url)
# 查看对象的属性语法:对象.属性
# r是对象名
# text是Response对象的属性,作用是输出网页源代码,类型为字符串数据
html = r.text
print(type(html))
print(html)
<class 'str'>
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
输出的html数据类型为字符串。
html存储的就是网页的源代码。
5. 利用bs4库输出网页源代码
【beautifulsoup4的安装命令】
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ beautifulsoup4
【温馨提示】
我们在安装的时候使用的库名为beautifulsoup4,但在编写程序时我们通常简写为bs4。
通过bs4我们也可以输出网页的源代码。
【代码示例】
import requests
url = 'http://python123.io/ws/demo.html'
# r是变量名,数据类型为Response对象
r = requests.get(url)
# 查看对象的属性语法:对象.属性
# r是对象名
# text是Response对象的属性,作用是输出网页源代码,类型为字符串数据
html = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(html , "html.parser")
print(soup)
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
利用bs4库我们也同样得到了网页的源代码。
6.bs4库的导入语法
from bs4 import BeautifulSoup
bs4是库名。BeautifulSoup是bs4库的类。- 上述代码表示导入
bs4库的`BeautifulSoup类。
soup = BeautifulSoup(html , "html.parser")
soup是变量名,数据类型为字符串。BeautifulSoup是类名。html是要解析的对象,html存储的是网页的源代码。html.parser是解析器。解析器的知识在后面章节有讲解。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)