【深度学习经典网络架构—4】:GoogLeNet(Incepetion系列V1、V2、V3)
之前我们说VGG拿到了ImageNet挑战赛(ILSVRC2014)分类项目的亚军,冠军就是谷歌提出的GoogLeNet,而**Inception模型是GoogLeNet的核心**。要想提高网络性能,常用方法就是提高神经网络的深度与宽度,但这也会带来两个问题
✨博客主页:王乐予🎈
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
目录
😺一、模块简介
之前我们说VGG拿到了ImageNet挑战赛(ILSVRC2014)分类项目的亚军,冠军就是谷歌提出的GoogLeNet,而Inception模型是GoogLeNet的核心。
要想提高网络性能,常用方法就是提高神经网络的深度与宽度,但这也会带来两个问题:
- 过于庞大的网络会大大增加网络参数,在训练过程中容易出现过拟合;
- 过于庞大的网络会成倍的增加训练时间,提高时间成本,且会带来很大的内存开销
Inception模型的提出就是为了解决这两个问题!
Inception是GoogLeNet中的核心模块,主要有四个版本,分别是:Inception V1、Inception V2、Inception V3、Inception V4。
论文链接:
- Inception V1:Going deeper with convolutions
- Inception V2:Rethinking the Inception Architecture for Computer Vision
- Inception V3:Rethinking the Inception Architecture for Computer Vision
- Inception V4:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
😺二、网络结构
🐶2.1 Inception V1
🦄2.1.1 Inception V1结构
论文中说:在参考文献2中指出,解决更深、更宽的网络模型带来的过拟合问题的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。如果数据集的概率分布可以用一个大的、非常稀疏的深度神经网络来表示,那么可以通过分析最后一层激活的相关统计数据来逐层构建最优网络拓扑结构。
但是从底层的硬件设备上考虑,非均匀稀疏模型需要更复杂的工程和计算基础设施,也就是说计算机硬件对非均匀的稀疏数据计算效果差。
因此Inception提出的目的就是通过设计一个全新的网络结构,既能保证稀疏性,又能提高计算效率。
Inception结构的主要思想是:卷积视觉网络中的最佳局部稀疏结构如何被现成的密集组件逼近和覆盖。
下面是原始的Inception模型⬇️

原始Inception模型有几点说明:
- 不同尺度的卷积核具有不同大小的感受野,可以提取不同尺度的特征,同尺寸下的特征图融合也具有不同尺度的特征;
- 论文中说:池化操作对于当前最先进的卷积网络的成功至关重要,因此建议在每个阶段添加替代的并行池化路径;
- 随着网络层次的加深,大尺度(5×5)卷积核的比例也会增加。
对于原始Inception结构参数请参考这篇文章:深入解读GoogLeNet网络结构(附代码实现)
🐸总的来说,原始Inception结构存在很严重的问题:
- 所有的卷积层(1×1、3×3、5×5)都是直接和输入对接的,因此卷积过程的参数计算量很大;
- 并行池化层的输出与输入维度相同,在和其他卷积层的输出做连接时,特征图的深度会变得很深,一样会增加很大的计算量。
对此,为了降低计算量,作者将1×1卷积添加至3×3和5×5卷积核之前用于降维,也就诞生了Inception V1结构⬇️

为什么使用1×1卷积核可以减少运算量呢?我们以5×5卷积核举例说明一下:
假定上一层的特征图尺度为:224×224×128,经过256个5×5卷积核输出后,输出尺寸为:224×224×256,卷积层参数为:128×5×5×256
如果上一层先通过一个具有32个尺寸为1×1的卷积核后,再经过256个5×5卷积核输出,输出特征图尺寸仍为:224×224×256,但此时卷积层参数量变为了:128×1×1×32+32×5×5×256,大约减少了4倍!
参考:https://blog.csdn.net/shuzfan/article/details/50738394
🦄2.1.2 GoogLeNet网络
使用Inception V1模块搭建的GoogLeNet如下图所示(受限于版面,高清图见原论文!):

表中给出了GoogLeNet的网络细节⬇️

注:表中的“#3x3 reduce”,“#5x5 reduce”表示在3x3,5x5卷积操作之前使用了1x1卷积的数量。
仅计算层数时,GoogLeNet具有22层(Inception V1视为网络层,深度为2),如果加上池化层(包括最大池化和平均池化)共有27层。
对GoogLeNet有几点说明:
- GoogLeNet采用模块化的设计,方便修改;
- 网络最后采用平均池化替代全连接层;
- GoogLeNet也是一个深层分类器,也会具有梯度消失的问题,因此作者对其中两个Inception模块的输出执行softmax操作,然后在同样的标签上计算辅助损失,总损失即为辅助损失和真实损失的加权和;
- 1×1卷积具有降维和校正线性激活的作用;
- dropout层采用0.7的失活率;
🦄2.1.3 总结
GoogLeNet是谷歌团队精心设计的,并在ILSVRC 2014比赛中大放异彩。当然,除了采用堆叠Inception式的网络架构,还有大量辅助工作,例如:训练过程中固定学习率(每 8 个 epoch 将学习率降低 4%)、多尺寸图像验证、一定程度的光照失真可以降低过拟合等。
🐶2.2 Inception V2
GoogLeNet凭借在ILSVRC 2014比赛中的优异表现,使得其被众多研究人员使用,但是谷歌团队发现如果一味的堆叠Inception模块虽然对准确率有所提升,但对计算机效率并没有很好提升,反之会有明显下降,因此如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。
🦄2.2.1 小尺度卷积
提升感受野的最直接方法就是增大卷积核尺寸,但这也会带来更多的参数计算:论文中指出一个5×5的卷积核计算成本是使用一个3×3卷积核计算成本的25/9=2.78倍。
为此,作者提出使用两个连续的3×3卷积层(stride=1)代替一个5×5卷积层,这既能减少参数量又可以提高感受野!如图所示:

那作者又在考虑,可不可以把卷积核尺寸分解的更小呢?
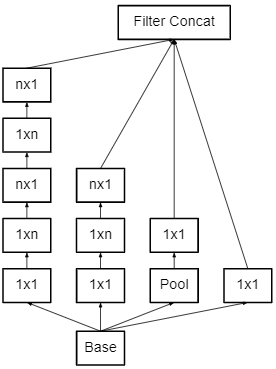
因此,谷歌团队又考虑了n×1卷积核,来取代3×3卷积核,如下图所示:

所以,论文中指出,任意的n×n卷积都可以通过1×n卷积后接n×1卷积来替代,但是谷歌又发现在网络初期使用这种小分解的效果并不好,只有在中度大小的特征图上使用效果才好(On m×m feature maps, where m ranges between 12 and 20)
🦄2.2.2 优化过程
模块优化过程如下,具体优化的成本变化见原论文!
 🐸🐸
🐸🐸 🐸🐸
🐸🐸
下图是用于高维表达的滤波器组,该模块的局部处理比率(1×1卷积)增加了,这是因为在粗网格中生成高维稀疏表示是很关键的。该模块用于粗粒度网格(8×8)!

论文中指出,有两种方式可以降低特征图尺寸,分别是先池化再卷积核先卷积再池化,如下图:

但是:第一种方式会导致特征表达遇到瓶颈(特征丢失),第二种方法虽然表示正常,但计算开销很大。为了既能保证特征表示又能减少计算量,谷歌将网络结构下图所示:

这种结构采用了并行化的方法降低计算量!
以上所有的方式方法的融合就得到了Inception V2!
🦄2.2.3 GoogLeNet网络
改进版的GoogLeNet使用Inception V2结构,网络结构图如下:

注:表格中的figure5、6、7见论文(均为上述结构)。
除此之外,Inception V2提出了BN,也就是我们常说的BN层(加速网络训练、防止梯度消失)!
🐶2.3 Inception V3
Inception V3结构较V2并没有太多改进,主要有一下几点:
- 对7×7卷积层分解为两个一维卷积(1×7,7×1);
- 对损失函数添加正则项,避免在分类网络中,神经网络对某一类别具有高度拟合性;
- 辅助分类器中也使用了BN。
🐶2.4 Inception V4
谷歌将Inception结构与残差网络相结合,构建出了Inception V4和Inception-ResNet等版本,通过实验,证明了具有残差结构的Inception的训练速度得到显著提升。
具体内容不详细介绍了,见原始论文!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)