
【自然语言处理】【实体匹配】CollaborER:使用多特征协作的自监督实体匹配框架
论文地址:https://arxiv.org/pdf/2108.08090.pdf实体匹配的目标是确定两个元组是否指向相同的现实实体。其是异常检测的前提,因为比较两个不同数据集中两个匹配元组的属性值是一种有效的异常检测方法。现有的实体匹配方法,由于特征挖掘不足或者固有特征容易出错,都不能达到稳定的性能。在本文中呈现了CollaborER\text{CollaborER}CollaborER,通过
论文地址:https://arxiv.org/pdf/2108.08090.pdf
相关博客:
【自然语言处理】【实体匹配】CollaborER:使用多特征协作的自监督实体匹配框架
【自然语言处理】【实体匹配】AutoBlock:一个用于实体匹配的自动化Blocking框架
【自然语言处理】【实体匹配】用于实体匹配中blocking环节的深度学习:一个设计空间的探索
【自然语言处理】【实体匹配】PromptEM:用于低资源广义实体匹配的Prompt-tuning
一、简介
实体匹配的目标是确定两个元组是否指向相同的现实实体。其是异常检测的前提,因为比较两个不同数据集中两个匹配元组的属性值是一种有效的异常检测方法。现有的实体匹配方法,由于特征挖掘不足或者固有特征容易出错,都不能达到稳定的性能。在本文中呈现了 CollaborER \text{CollaborER} CollaborER,通过多个特征协作进行自监督实体匹配的框架。该框架能够:(1) 不使用人工的情况下获得可靠的实体匹配结果;(2) 以容错的方式来挖掘足够的元组特征。 CollaborER \text{CollaborER} CollaborER由两个阶段组成:自动标签生成 (ALG) \text{(ALG)} (ALG)和协作实体匹配训练 (CERT) \text{(CERT)} (CERT)。第一阶段, ALG \text{ALG} ALG生成正、负样本集合。 ALG \text{ALG} ALG能够确保生成的元组是高质量的,因此能够确保后续 CERT \text{CERT} CERT的训练质量。第二阶段, CERT \text{CERT} CERT来从图特征和句子特征学习匹配信号。
二、预备知识
1. 问题定义
令 T T T是具有 ∣ T ∣ |T| ∣T∣个元组和 m m m个属性 A = { A [ 1 ] , A [ 2 ] , … , A [ m ] } A=\{A[1],A[2],\dots,A[m]\} A={A[1],A[2],…,A[m]}的关系数据集。每个元组 e ∈ T e\in T e∈T是由属性值集合组成的,表示为 V = { e . A [ 1 ] , e . A [ 2 ] , … , e . A [ m ] } V=\{e.A[1],e.A[2],\dots,e.A[m]\} V={e.A[1],e.A[2],…,e.A[m]}。 e . A [ m ] e.A[m] e.A[m]是元组 e e e的第 m m m个属性值,对应于属性 A [ m ] ∈ A A[m]\in A A[m]∈A。实体匹配 ( Entity Matching ) (\text{Entity Matching}) (Entity Matching),也称为 Entity resolution \text{Entity resolution} Entity resolution或者 Record linkage \text{Record linkage} Record linkage,其目标是从两个关系数据集 T T T和 T ′ T' T′找出指向相同实体的匹配元组对 M \mathcal{M} M。实体匹配被形式化为 M = { ( e , e ′ ) ∈ T × T ′ ∣ e ≡ e ′ } \mathcal{M}=\{(e,e')\in T\times T'|e\equiv e'\} M={(e,e′)∈T×T′∣e≡e′},其中 e ∈ T , e ′ ∈ T ′ e\in T,e'\in T' e∈T,e′∈T′并且 ≡ \equiv ≡表示元组 e e e和 e ′ e' e′之间的匹配关系。
为了减少均方次数的匹配候选对,一个实体匹配程序通常会在匹配阶段之前执行一个blocking阶段。blocking的目标是从 T × T ′ T\times T' T×T′找出一个小的子集,该子集具有较高的匹配概率。此外,blocking机制期望具有0错误率,这是实体匹配技术的常见假设。设计一个有效的blocking策略与 CollaborER \text{CollaborER} CollaborER正交,因此这里使用现有实体匹配方法广泛使用的blocking方法。匹配的目标是预测候选元组对中的匹配元组对,这也是本工作所专注的。
2. 预训练语言模型
像 BERT \text{BERT} BERT和 XLNet \text{XLNet} XLNet这样的预训练语言模型已经展示了强大的语义表达能力。预训练语言模型可以支持许多下游任务。具体来说,可以根据具体的任务将适合的输入和输出插入至预训练语言模型,并端到端的微调所有模型参数。
直觉上,实体匹配问题可以看作是句子对分类任务。给定两个元组
e
i
∈
T
e_i\in T
ei∈T和
e
j
′
∈
T
′
e_j'\in T'
ej′∈T′,预训练语言模型将其转换为两个句子
S
(
e
i
)
\mathcal{S}(e_i)
S(ei)和
S
(
e
j
′
)
\mathcal{S}(e_j')
S(ej′)。一个句子
S
(
e
i
)
\mathcal{S}(e_i)
S(ei)被表示为
S
(
e
i
)
:
:
=
⟨
[
C
O
L
]
A
[
1
]
[
V
A
L
]
e
i
.
A
[
1
]
…
[
C
O
L
]
A
[
m
]
[
V
A
L
]
e
i
.
A
[
m
]
⟩
\mathcal{S}(e_i)::=\langle[COL]A[1][VAL]e_i.A[1]\dots[COL]A[m][VAL]e_i.A[m]\rangle
S(ei)::=⟨[COL]A[1][VAL]ei.A[1]…[COL]A[m][VAL]ei.A[m]⟩
其中
[
C
O
L
]
[COL]
[COL]和
[
V
A
L
]
[VAL]
[VAL]是表明属性名和属性值开始的特殊tokens。注意,这里排除了缺失值和其对应的属性名,因为其并不包含有效的信息。一个元组对
(
e
i
,
e
j
′
)
(e_i,e_j')
(ei,ej′)能够被序列化为一个句子对
S
(
e
i
,
e
j
′
)
:
:
=
⟨
S
(
e
i
)
[
S
E
P
]
S
(
e
j
′
)
⟩
\mathcal{S}(e_i,e_j')::=\langle\mathcal{S}(e_i)[SEP]\mathcal{S}(e_j')\rangle
S(ei,ej′)::=⟨S(ei)[SEP]S(ej′)⟩,其中
[
S
E
P
]
[SEP]
[SEP]是分离两个句子的特殊token。对于句子对分类任务,预训练语言模型将每个句子对
S
(
e
i
,
e
j
′
)
\mathcal{S}(e_i,e_j')
S(ei,ej′)作为输入。特殊token
[
C
L
S
]
[CLS]
[CLS]被添加在每个输入句子之前。
-
目标函数
使用交叉熵损失函数来微调 CollaborER \text{CollaborER} CollaborER中预训练语言模型。交叉熵损失函数用于保持预测标签和真实标签的相似性。
L ( y = k ∣ S ( e i , e j ′ ) ) = − log ( exp ( d k ) ∑ q ∣ k ∣ exp ( d q ) ) ∀ k ∈ { 0 , 1 } (1) \mathcal{L}(y=k|\mathcal{S}(e_i,e_j'))=-\log\Big(\frac{\exp(d_k)}{\sum_{q}^{|k|}\exp(d_q)}\Big)\forall k\in\{0,1\} \tag{1} L(y=k∣S(ei,ej′))=−log(∑q∣k∣exp(dq)exp(dk))∀k∈{0,1}(1)
这里 d ∈ R ∣ k ∣ \textbf{d}\in\mathbb{R}^{|k|} d∈R∣k∣是通过 d = W c ⊤ E [ C L S ] \textbf{d}=\textbf{W}_c^\top\textbf{E}_{[CLS]} d=Wc⊤E[CLS]计算的logits。 W c ∈ R n × ∣ k ∣ \textbf{W}_c\in\mathbb{R}^{n\times|k|} Wc∈Rn×∣k∣可学习线性矩阵,其中 n n n是句子嵌入的维度。 E [ C L S ] \textbf{E}_{[CLS]} E[CLS]是符号 [ C L S ] [CLS] [CLS]的嵌入向量。对于句子对分类任务,分类标签为二进制 { 0 , 1 } \{0,1\} {0,1}。 y = 1 y=1 y=1是匹配样本对,并且 y = 0 y=0 y=0是不匹配对。
3. 图神经网络
图神经网络
(
Graph Neural Networks, GNNs
)
(\text{Graph Neural Networks, GNNs})
(Graph Neural Networks, GNNs)是流行的基于图模型,其通过图中节点的信息传递来捕获图特征。由于下面的两个方面,
GNNs
\text{GNNs}
GNNs特别适合实体匹配任务。首先,
GNNs
\text{GNNs}
GNNs忽略不同属性的顺序关系,但是通过聚合属性名和值中的语义信息来发掘每个元组的特征。这符合关系数据集中真实特征,因为元组不是句子并且实体属性可以按任意顺序组织。因此,
GNNs
\text{GNNs}
GNNs能够有效的捕获每个元组的特征。其中,
GNNs
\text{GNNs}
GNNs通过相关阶段间消息传递来捕获图特征。
GNNs
\text{GNNs}
GNNs具有从相关元组学习丰富语义的能力,因为一个元组的特征可以通过边传递给另一个元组。
GNNs
\text{GNNs}
GNNs的核心想法是通过捕获来自邻居的信息来学习每个节点的表示。一般来说,
GNNs
\text{GNNs}
GNNs遵循下面的等式来学习每个节点
n
i
n_i
ni的嵌入表示:
o
i
l
+
1
=
AGGREGATION
l
(
{
{
(
h
j
l
,
r
i
,
j
:
j
∈
N
(
i
)
}
}
)
(2)
\textbf{o}_{i}^{l+1}=\text{AGGREGATION}^l\Big(\Big\{\Big\{\Big(\textbf{h}_j^l,\textbf{r}_{i,j}:j\in\mathcal{N}(i)\Big\}\Big\}\Big) \tag{2}
oil+1=AGGREGATIONl({{(hjl,ri,j:j∈N(i)}})(2)
h i l + 1 = UPDATE l + 1 ( h i l , o i l + 1 ) (3) \textbf{h}_i^{l+1}=\text{UPDATE}^{l+1}(\textbf{h}_i^l,\textbf{o}_i^{l+1}) \tag{3} hil+1=UPDATEl+1(hil,oil+1)(3)
其中 h i l \textbf{h}_i^l hil节点 n i n_i ni在第 l l l层的嵌入向量, r i , j \textbf{r}_{i,j} ri,j表示链接节点 n i n_i ni和其他节点 n j n_j nj边的嵌入向量,并且 { { … } } \{\{\dots\}\} {{…}}表示多集。 N ( i ) \mathcal{N}(i) N(i)表示节点 e i e_i ei的邻居集合。等式(2)用于聚合邻居节点,等式(3)用于转换实体嵌入向量。为了达到 AGGREGATION \text{AGGREGATION} AGGREGATION的目标,可以使用图卷积网络 ( graph convolutional network,GCN ) (\text{graph convolutional network,GCN}) (graph convolutional network,GCN)或者图注意力网络 (graph attention network,GAT) \text{(graph attention network,GAT)} (graph attention network,GAT)。
三、框架概述
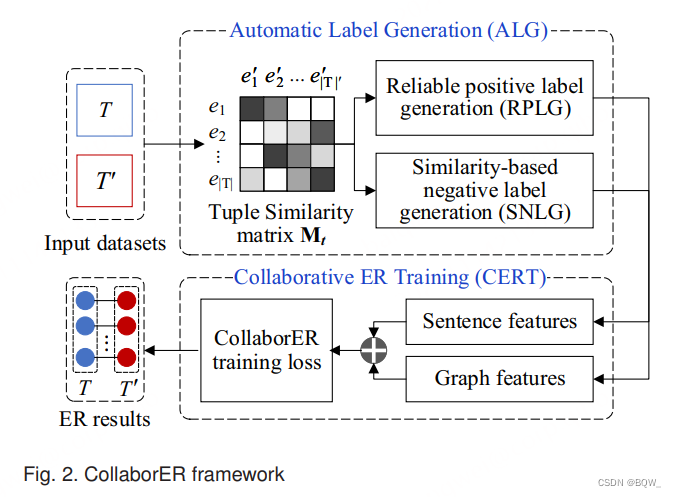
CollaborER \text{CollaborER} CollaborER框架由两个阶段组成:(i) 自动标签生成( ALG \text{ALG} ALG);(ii) 协作实体匹配训练( CERT \text{CERT} CERT)。
1. 自动标签生成 (ALG) \text{(ALG)} (ALG)
在许多真实世界场景中,预先收集实体匹配标签是不可行的。这激励我们通过自动标签生成程序来生成近似的标签。给定两个数据集 T T T和 T ′ T' T′,每个数据集都是一个元组的集合,该阶段是生成高质量的伪标签,包含正标签和负标签,并用于后续的训练过程。
正元组对记为 P \mathbb{P} P。对于每个正元组对 P ( e i , e i ′ ) \mathbb{P}(e_i,e_i') P(ei,ei′),元组 e i ∈ T e_i\in T ei∈T和 e i ′ ∈ T ′ e_i'\in T' ei′∈T′有高概率是匹配的。在 ALG \text{ALG} ALG中,作者引入了 reliable postive label generation(RPLG) \text{reliable postive label generation(RPLG)} reliable postive label generation(RPLG)策略来获得高置信度的正元组对。
负元组对记为 N \mathbb{N} N。对于每个负元组对 N ( e i , e j ′ ) \mathbb{N}(e_i,e_j') N(ei,ej′),元组 e i ∈ T e_i\in T ei∈T和 e j ′ ∈ T ′ − { e i ′ } e'_j\in T'-\{e_i'\} ej′∈T′−{ei′}不太可能匹配。随机采样是一种广泛使用的生成负标签的方法。给定一个正元组对 P ( e i , e i ′ ) \mathbb{P}(e_i,e_i') P(ei,ei′),随机采样任意元组来替换 e i e_i ei或者 e i ′ e_i' ei′。然而,近期的研究表明,随机生成的负元组对可以与正元组对轻易区分。举例来说,若为一个正元组对 ("Apple Inc.","Apple") \text{("Apple Inc.","Apple")} ("Apple Inc.","Apple")生成负元组对 ("Apple Inc.", "Google") \text{("Apple Inc.", "Google")} ("Apple Inc.", "Google"),显然"Google"和"Apple Inc."是不相等的。
2. 协作实体匹配训练 (CERT) \text{(CERT)} (CERT)
单纯基于元组的句子特征或者图特征进行实体匹配会导致特征发现不足或者错误特征。 CERT \text{CERT} CERT的目标是在统一的框架中捕获和集成句子特征和图特征来改善实体匹配的质量。
给定两个数据集 T T T和 T ′ T' T′,以及由 ALG \text{ALG} ALG生成的标签集合, CERT \text{CERT} CERT首先会引入 multi-relational graph construction(MRGC) \text{multi-relational graph construction(MRGC)} multi-relational graph construction(MRGC),其会为数据集 T ( T ′ ) T(T') T(T′)来构建一个多关系图 G ( G ′ ) \mathcal{G}(\mathcal{G'}) G(G′)。由 MRGC \text{MRGC} MRGC生成的图结构要比现有实体匹配方法生成的图更加简单。
CERT \text{CERT} CERT基于图结构学习每个元组的嵌入向量。 CERT \text{CERT} CERT可以视作是黑盒,用户可以灵活的应用其选择的图模型来嵌入节点和边。本文主要是利用 AttrGNN \text{AttrGNN} AttrGNN来实现这个目标。然而,将元组训练好的图特征输入至预训练语言模型中来帮助学习元组的句子特征。更具体来说,元组的图特征被用于补充语义特征。
四、自动标签生成( ALG \text{ALG} ALG)
本小节提出一种自动标签生成策略,其包含两个组件:(i) 可靠的正样本生成 (RPLG) \text{(RPLG)} (RPLG);(ii) 基于相似度的负样本生成 ( SNLG ) (\text{SNLG}) (SNLG)。
无论生成正样本或者负样本,都于元组间的相似度高度相关。受预训练语言模型强大的语义表达能力启发,利用 sentence-BERT \text{sentence-BERT} sentence-BERT来为每个元组分配一个预训练嵌入向量。一般来说,根据数据集的特点,不同的相似度度量函数可以用来量化不同数据集中元组的相似度。在当前的实现中,cosine距离能够有好的表现。因此,选择cosine作为 ALG \text{ALG} ALG的相似函数。元组相似矩阵 M t ∈ [ 0 , 1 ] ∣ T ∣ × ∣ T ′ ∣ \textbf{M}_t\in[0,1]^{|T|\times|T'|} Mt∈[0,1]∣T∣×∣T′∣,其中 ∣ T ∣ |T| ∣T∣和 ∣ T ′ ∣ |T'| ∣T′∣表示 T T T和 T ′ T' T′中的总元组数量。下面将详细描述通过 RPLG \text{RPLG} RPLG和 SNLG \text{SNLG} SNLG来生成正、负标签。
4.1 可靠正标签生成 ( RPLG ) (\text{RPLG}) (RPLG)
RPLG \text{RPLG} RPLG的目标是寻找高概率匹配的正样本对。一种常用的方法是考虑彼此最相似的元组。然而,作者发现彼此最相似的元组都指向相同的实体。考虑到高质量的标签对于基于嵌入向量的实体匹配模型来说至关重要,而错误的标签则会误导实体匹配模型的训练。本文选择通过 IKGC \text{IKGC} IKGC来生成正样本,该方法使用更强的约束来保证正样本的高质量。其生成的正样本元组对需要满足两个要求:(1) 它们彼此之间非常相似;(2) 对于每个元组 e e e,最相似元组和第二相似元组间存在一定的距离。
具体来说,对于每个元组 e i ∈ T e_i\in T ei∈T,假设 e j ′ , e k ′ ∈ T ′ e_j',e_k'\in T' ej′,ek′∈T′分别是 T ′ T' T′中最相似和第二相似的元组。类似地,对于元组 e j ′ ∈ T ′ e_j'\in T' ej′∈T′,则从 T T T中找出最相似和第二相似的元组 e l e_l el和 e u e_u eu。若 e l = e i e_l=e_i el=ei,则元组对 ( e i , e j ′ ) (e_i,e_j') (ei,ej′)才可能被考虑为正样本,即两个实体相互都是最相似。此外,相似度差异 δ 1 = S i m ( e i , e j ′ ) − S i m ( e i , e k ′ ) \delta_1=Sim(e_i,e_j')-Sim(e_i,e_k') δ1=Sim(ei,ej′)−Sim(ei,ek′)且 δ 2 = S i m ( e j ′ , e l ) − S i m ( e j ′ , e u ) \delta_2=Sim(e_j',e_l)-Sim(e_j',e_u) δ2=Sim(ej′,el)−Sim(ej′,eu)都需要大于阈值 θ \theta θ,即满足第(2)个要求。这里, S i m ( e , e ′ ) Sim(e,e') Sim(e,e′)表示两个元组 e ∈ T e\in T e∈T和 e ′ ∈ T ′ e'\in T' e′∈T′的相似度分数。
-
讨论
RPLG \text{RPLG} RPLG是通用的方法,其能够轻易的集成至实体匹配模型中。 RPLG \text{RPLG} RPLG不仅能够生成高质量的正标签,而且在不需要耗时的情况下就能实现高质量的实体匹配效果。
4.2 基于相似度的负标签生成 (SNLG) \text{(SNLG)} (SNLG)
基于随机负样本生成方法对于基于嵌入向量的实体匹配训练,生成更加挑战的负样本是有必要的。为了实现这个目标,这里提出了基于相似度的负标签生成策略 ( SNLG ) (\text{SNLG}) (SNLG)。给定一个正元组对 P ( e i , e i ′ ) \mathbb{P}(e_i,e_i') P(ei,ei′),其中 e i ∈ T e_i\in T ei∈T和 e i ′ ∈ T ′ e_i'\in T' ei′∈T′, SNLG \text{SNLG} SNLG会在语义嵌入空间上使用 ϵ \epsilon ϵ最近邻来替换 e i e_i ei或者 e i ′ e_i' ei′来生成负样本集合 N ( e i , e i ′ ) \mathbb{N}(e_i,e_i') N(ei,ei′)。使用cosine相似度度量来搜索 e i e_i ei和 e i ′ e_i' ei′的 ϵ \epsilon ϵ最近邻。
-
讨论
尽管这是一种非常直观且简单的方法,但是有效的改善了 CollaborER \text{CollaborER} CollaborER的表现。
五、协作实体匹配训练 (CERT) \text{(CERT)} (CERT)
1. 多关系图特征学习 (MRGFL) \text{(MRGFL)} (MRGFL)
受图形结构强大的语义捕获能力启发,本文提出多关系图特征学习方法 ( MRGFL ) (\text{MRGFL}) (MRGFL)来根据图特征表示元组。首先提出了多关系图构建方法 ( multi-relational graph construction,MRGC ) (\text{multi-relational graph construction,MRGC}) (multi-relational graph construction,MRGC)来将关系形式的数据集转换为图结构,然后通过 GNN-based \text{GNN-based} GNN-based模型来学习元组表示,本文的 GNN \text{GNN} GNN使用 AttrGNN \text{AttrGNN} AttrGNN。
- 多关系图构建 ( MRGC ) (\text{MRGC}) (MRGC)
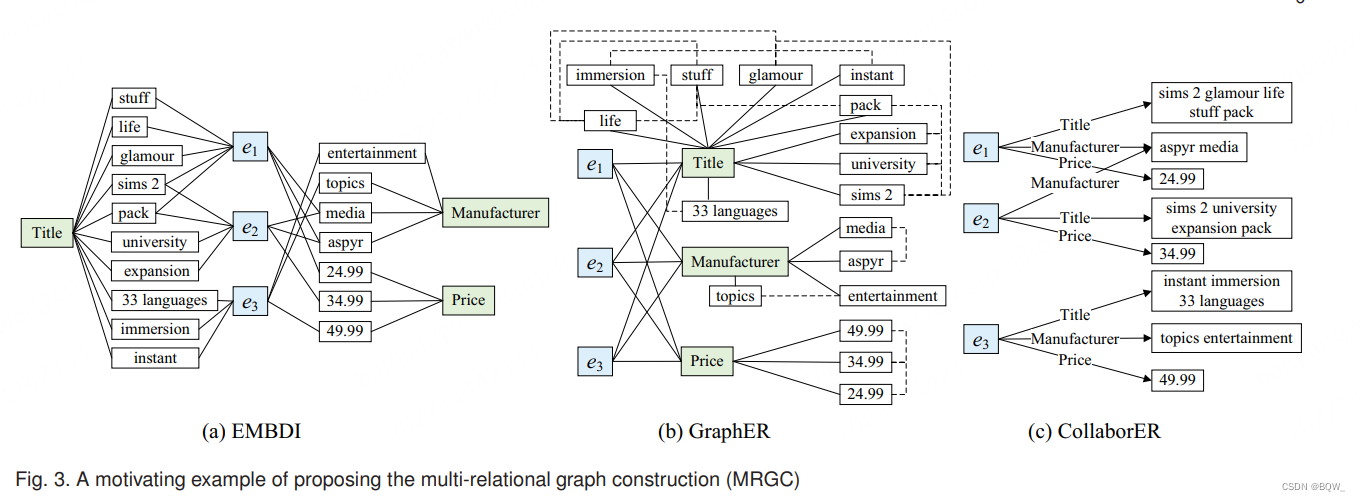
像 EMBDI \text{EMBDI} EMBDI和 GraphER \text{GraphER} GraphER这样现有工作中已经提出了图构造方法。这些技术将元组、属性值和属性名称当做是三种类型的节点。若这些节点间存在关系,则连接边。然而,一些缺点限制了使用这些图构造方法来执行实体匹配的范围。
首先,这些图构造方法可能会产生保留大量节点和边的大规模图。存储大规模节点和边是耗费内存的,并且在大图上训练图嵌入模型是具有挑战的。
其次,这些图构造方法缺乏对边本身含义的考虑。举例,假设这里有两种类型的编码,即attribute-value edges和tuple-attribute edges。前者表示连接属性级别节点和值节点;后者表示连接元组级节点和属性级节点的边。显然,这两种类型的边具有不同的语义信息,当在实体匹配任务中学习元组特征时,需要不同的考虑。
上面的限制促使作者设置一个相对小规模并高效的
MRGC
\text{MRGC}
MRGC来为每个数据集构造多关系图。先定义多关系图
G
=
{
N
,
E
,
A
}
\mathcal{G}=\{N,E,A\}
G={N,E,A}。这里,
N
N
N和
E
E
E是指节点集合和边集合,
A
A
A表示对应于节点和边的属性集合。
G
\mathcal{G}
G中有两种类型的节点:tuple-level nodes和value-level nodes。tuple-level node表示一个元组
e
e
e,而value-level node对应关系数据集中的属性值
v
v
v。每个属性
a
∈
A
a\in A
a∈A表示关系数据集中的属性名称。
E
=
{
(
e
,
a
,
v
)
∣
e
,
v
∈
N
,
a
∈
A
}
E=\{(e,a,v)|e,v\in N,a\in A\}
E={(e,a,v)∣e,v∈N,a∈A}表示边的集合。每个边通过属性
a
a
a链接一个tuple-level节点
e
e
e和value-level节点
v
v
v,意味着
e
e
e在属性
a
a
a的取值是
v
v
v。
算法1:多关系图构建
输入:一个关系数据集 T T T
输出:多关系图 G \mathcal{G} G
G ← ∅ \mathcal{G}\leftarrow\empty G←∅
foreach e i ∈ T e_i\in T ei∈T do
G . addNode ( e i ) \mathcal{G}.\text{addNode}(e_i) G.addNode(ei)
foreach v j ∈ { e i . A [ 1 ] , e i . A [ 2 ] , … , e i . A [ m ] } v_j\in\{e_i.A[1],e_i.A[2],\dots,e_i.A[m]\} vj∈{ei.A[1],ei.A[2],…,ei.A[m]} do
if v j v_j vj不在图 G \mathcal{G} G中 then
G . addNode ( v j ) \mathcal{G}.\text{addNode}(v_j) G.addNode(vj)
a i , j ← a_{i,j}\leftarrow ai,j← v j v_j vj的属性名
G . addEdge ( e i , a i , j , v j ) \mathcal{G}.\text{addEdge}(e_i,a_{i,j},v_j) G.addEdge(ei,ai,j,vj)
return G \mathcal{G} G
算法1的伪代码描述
MRGC
\text{MRGC}
MRGC过程。给定一个关系数据集
T
T
T,
MRGC
\text{MRGC}
MRGC初始化一个空多关系图
G
\mathcal{G}
G。然后,
MRGC
\text{MRGC}
MRGC迭代添加节点和边至
G
\mathcal{G}
G。具体来说,对于每个元组
e
i
∈
T
e_i\in T
ei∈T,
MRGC
\text{MRGC}
MRGC先选择元组的Id作为tuple-level节点,然后将对应于这个tuple的value-level节点添加至图中。由于不同的元组共享相同的属性名,
MRGC
\text{MRGC}
MRGC为
e
i
e_i
ei生成边集合,其会连接tuple-level节点
e
i
e_i
ei和value-level节点
v
j
∈
{
e
i
.
A
[
1
]
,
e
i
.
A
[
2
]
,
…
,
e
i
.
A
[
m
]
}
v_j\in\{e_i.A[1],e_i.A[2],\dots,e_i.A[m]\}
vj∈{ei.A[1],ei.A[2],…,ei.A[m]},记为
(
e
i
,
a
i
,
j
,
v
j
)
(e_i,a_{i,j},v_{j})
(ei,ai,j,vj)。
-
讨论:相较于现有的图构造方法, MRGC \text{MRGC} MRGC构造的图虽小但很好的保留了元组的语义。以 Amazon \text{Amazon} Amazon数据集为例。上图展示了 EMBDI \text{EMBDI} EMBDI、 GraphER \text{GraphER} GraphER和 MRGC \text{MRGC} MRGC三种不同图构造方法构造的图结构。显然, MRGC \text{MRGC} MRGC构造的图最小,包含更少的节点和边。 MRGC \text{MRGC} MRGC不仅保留了每个元组和其对应的属性值的语义关系,也通过共享
value-level节点保留了不同元组的语义链接。具体来说, e 1 e_1 e1和 e 2 e_2 e2由于在相同的value-level节点"aspyr media"有边连接,所以其具有语义连接。 -
多关系图特征学习 ( MRGFL ) (\text{MRGFL}) (MRGFL)
给定两个多关系图 G \mathcal{G} G(对应 T T T)和 G ′ \mathcal{G}' G′(对应 T ′ T' T′), MRGFL \text{MRGFL} MRGFL的目标是通过考虑图结构将不同源的元组嵌入至统一的向量空间。在该向量空间,匹配元组被期望彼此之间更接近。一般来说,可以将 MRGFL \text{MRGFL} MRGFL看作是一个基于图的实体匹配问题,其与实体对齐 ( entity alignment ) (\text{entity alignment}) (entity alignment)高度相关。为了这个目的, MRGFL \text{MRGFL} MRGFL被看作是黑盒。用户可以灵活的应用各种entity alignment模型来学习元组的嵌入向量。在本文的实现中,采用
state-of-the-art实体对齐模型 AttrGNN \text{AttrGNN} AttrGNN来聚合每个元组的图特征。下面将描述使用entity alignment模型来学习元组图特征的主要想法。首先,通过应用 GNN \text{GNN} GNN模型来获得每个元组的图特征。其输出一组元组的嵌入向量。将每个元组 e i ∈ T e_i\in T ei∈T的嵌入向量表示为 h e i \textbf{h}_{e_i} hei。训练目标函数用于将两个数据集的元组统一至同一向量空间。
L g = ∑ e i , e i ′ ∈ P ∑ ( e j , e k ) ∈ N [ d ( e i , e i ′ ) + γ − d ( e j , e k ) ] + (4) \mathcal{L}_g=\sum_{e_i,e_i'\in\mathbb{P}}\sum_{(e_j,e_k)\in\mathbb{N}}[d(e_i,e_i')+\gamma-d(e_j,e_k)]_+ \tag{4} Lg=ei,ei′∈P∑(ej,ek)∈N∑[d(ei,ei′)+γ−d(ej,ek)]+(4)
这里, ( e i , e i ′ ) ∈ P (e_i,e_i')\in\mathbb{P} (ei,ei′)∈P表示一个正样本; ( e j , e k ) ∈ M (e_j,e_k)\in\mathbb{M} (ej,ek)∈M表示负样本; [ b ] + = max { 0 , b } [b]_+=\max\{0,b\} [b]+=max{0,b}; d ( e i , e i ′ ) d(e_i,e_i') d(ei,ei′)表示 h e i \textbf{h}_{e_i} hei和 h e i ′ \textbf{h}_{e_i'} hei′的cosine距离,其中 h e i \textbf{h}_{e_i} hei和 h e i ′ \textbf{h}_{e_i'} hei′是 e i e_i ei和 e i ′ e_i' ei′的最终嵌入向量;类似地, d ( e j , e k ) d(e_j,e_k) d(ej,ek)表示 h e j \textbf{h}_{e_j} hej和 h e k \textbf{h}_{e_k} hek的cosine距离; γ \gamma γ是超参数。
2. 协作句子特征学习 (CSFL) \text{(CSFL)} (CSFL)
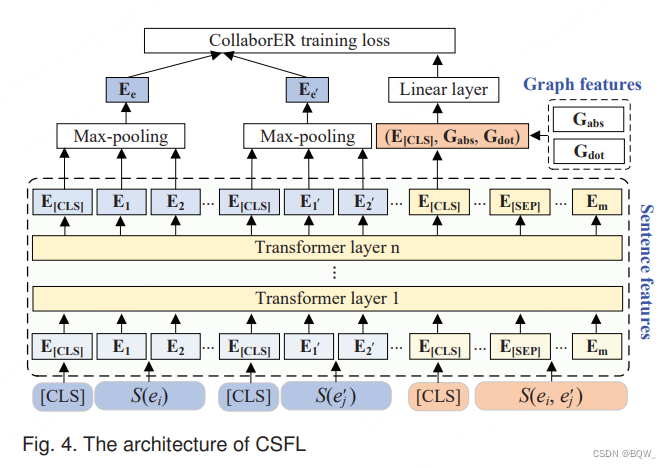
近期研究表明捕获元组的句子特征有助于实体匹配任务。然而,将元组作为句子会导致特征挖掘不充分。为此,作者提出了协作句子特征学习 ( CSFL ) (\text{CSFL}) (CSFL)模型,其在良好训练的元组图特征帮助下挖掘出充分的元组句子特征。 CSFL \text{CSFL} CSFL的训练目标是:(1) 确定两个元组是否指向相同的实体;(2) 最小化匹配元组的语义距离。 CSFL \text{CSFL} CSFL的架构如上图所示。
首先,介绍如何在
CSFL
\text{CSFL}
CSFL中识别匹配的元组。使用句子对分类任务来微调预训练语言模型。将句子对
S
(
e
i
,
e
i
′
)
\mathcal{S}(e_i,e_i')
S(ei,ei′)作为输入,其对应于
ALG
\text{ALG}
ALG生成的正、负标签。然而,通过将输入送入至多层
Transformer
\text{Transformer}
Transformer编码器来学习分类信号
E
[
C
L
S
]
\textbf{E}_{[CLS]}
E[CLS]。在当前的实现中,
Transformer
\text{Transformer}
Transformer的层数被设置为12。使用交叉熵变体
L
1
\mathcal{L}_1
L1作为目标函数。
L
1
(
y
=
k
∣
S
(
e
i
,
e
j
′
)
)
=
−
log
(
exp
(
d
k
∗
)
∑
q
∣
k
∣
exp
(
d
q
∗
)
)
∀
k
∈
{
0
,
1
}
(5)
\mathcal{L}_1(y=k|\mathcal{S}(e_i,e_j'))=-\log\Big(\frac{\exp(d_k^*)}{\sum_q^{|k|}\exp(d_q^*)}\Big)\forall k\in\{0,1\} \tag{5}
L1(y=k∣S(ei,ej′))=−log(∑q∣k∣exp(dq∗)exp(dk∗))∀k∈{0,1}(5)
d ∗ = W c ∗ ⊤ ( E [ C L S ] ; G a b s ; G d o t ) (6) \textbf{d}^*=\textbf{W}_c^{*\top}(\textbf{E}_{[CLS]};\textbf{G}_{abs};\textbf{G}_{dot}) \tag{6} d∗=Wc∗⊤(E[CLS];Gabs;Gdot)(6)
logits d ∗ \textbf{d}^* d∗是通过元组的句子特征 ( E [ C L S ] ) (\textbf{E}_{[CLS]}) (E[CLS])和图特征 ( G a b s ∈ R c 和 G d o t ∈ R c ) (\textbf{G}_{abs}\in\mathbb{R}^c和\textbf{G}_{dot}\in\mathbb{R}^c) (Gabs∈Rc和Gdot∈Rc)产生的,其中 c c c是元组图特征的维度。 W c ∗ ∈ R ( n + 2 c ) × ∣ k ∣ \textbf{W}_c^*\in\mathbb{R}^{(n+2c)\times|k|} Wc∗∈R(n+2c)×∣k∣。 G a b s = ∣ h e i − h e i ′ ∣ \textbf{G}_{abs}=|\textbf{h}_{e_i}-\textbf{h}_{e_i'}| Gabs=∣hei−hei′∣表示嵌入向量 h e i \textbf{h}_{e_i} hei和 h e i ′ \textbf{h}_{e_i'} hei′的差值。 G d o t = h e i ⊗ h e i ′ \textbf{G}_{dot}=\textbf{h}_{e_i}\otimes\textbf{h}_{e_i'} Gdot=hei⊗hei′表示 h e i \textbf{h}_{e_i} hei和 h e i ′ \textbf{h}_{e_i'} hei′的相似度。
第二,展示如何最小化匹配元组对的语义距离。在输入端,预训练语言模型为句子
S
e
i
\mathcal{S}_{e_i}
Sei的每个token分配一个初始化的嵌入,记为
E
i
\textbf{E}_i
Ei。注意,特殊符号
[
C
L
S
]
[CLS]
[CLS]位于每个句子的开头,也会分配初始化嵌入向量,记为
E
[
C
L
S
]
\textbf{E}_{[CLS]}
E[CLS]。应用max-pooling来获得固定长度的嵌入向量
E
e
i
\textbf{E}_{e_i}
Eei(
E
e
i
′
\textbf{E}_{e_i'}
Eei′)来表示元组
e
e
e。使用CosineEmbedding损失函数
L
2
\mathcal{L}_2
L2作为训练目标。其被设计用来最小化匹配元组的语义距离,并最大化不匹配元组的语义距离。
L
2
(
y
∣
S
(
e
i
)
,
S
(
e
j
′
)
)
=
{
1
−
cos
(
E
e
i
,
E
e
j
′
)
,
if y=1
max
(
0
,
cos
(
E
e
i
,
E
e
j
′
)
−
λ
)
,
if y=0
(7)
\mathcal{L}_2(y|\mathcal{S}(e_i),\mathcal{S}(e_j'))= \begin{cases} 1-\cos(\textbf{E}_{e_i},\textbf{E}_{e_j'}),\text{if y=1} \\ \max(0,\cos(\textbf{E}_{e_i},\textbf{E}_{e_j'})-\lambda),\text{if y=0} \end{cases} \tag{7}
L2(y∣S(ei),S(ej′))={1−cos(Eei,Eej′),if y=1max(0,cos(Eei,Eej′)−λ),if y=0(7)
其中,
λ
\lambda
λ是从不匹配元组对中分离匹配元组对的边界超参数。
最后,
CSFL
\text{CSFL}
CSFL的整体训练函数。
L
c
=
L
1
+
μ
L
2
(8)
\mathcal{L}_c=\mathcal{L}_1+\mu\mathcal{L}_2\tag{8}
Lc=L1+μL2(8)
其中超参数
u
∈
[
0
,
1
]
u\in[0,1]
u∈[0,1]是控制损失函数相对权重的超参数。
六、实验
1. Benchmark数据集
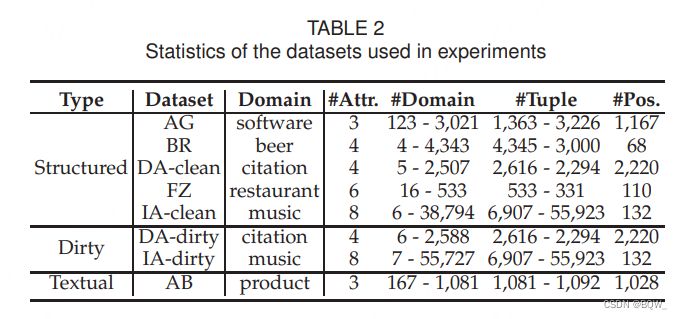
在具有不同尺寸和领域的8个广泛使用的实体匹配数据集上进行实验。上表列出了详细的统计信息。对于结构化实体匹配,使用5个benchmarks,包括
Amazon-Google(AG)
\text{Amazon-Google(AG)}
Amazon-Google(AG)、
BeerAdvo-RateBeer(BR)
\text{BeerAdvo-RateBeer(BR)}
BeerAdvo-RateBeer(BR)、干净版本的
DBLP-ACM(DA-clean)
\text{DBLP-ACM(DA-clean)}
DBLP-ACM(DA-clean)、
Fodors-Zagats(FZ)
\text{Fodors-Zagats(FZ)}
Fodors-Zagats(FZ)和干净版本的
iTunes-Amazon(IA-clean)
\text{iTunes-Amazon(IA-clean)}
iTunes-Amazon(IA-clean)。元组的属性值是原子的,而不是多值组合。对于dirty实体匹配,使用dirty版本的
DBLP-ACM
\text{DBLP-ACM}
DBLP-ACM和
iTunes-Amazon
\text{iTunes-Amazon}
iTunes-Amazon benchmark来衡量
CollaborER
\text{CollaborER}
CollaborER对噪音的鲁棒性。对于textual实体匹配,使用
Abt-Buy(AB)
\text{Abt-Buy(AB)}
Abt-Buy(AB) benchmark。
2. 实现和实验设置
2.1 评估指标
为了衡量实体匹配结果的质量,使用 F1-score \text{F1-score} F1-score,其是 precision \text{precision} precision和 recall \text{recall} recall的调和平均数,计算方式为 2 × ( P r e c . × R e c . ) ( P r e c . + R e c . ) \frac{2\times(Prec.\times Rec.)}{(Prec.+Rec.)} (Prec.+Rec.)2×(Prec.×Rec.)。这里, precison \text{precison} precison定义为匹配预测中正确的百分比; recall \text{recall} recall定义为真实匹配被预测出来的百分比。
2.2 baselines
CollaborER \text{CollaborER} CollaborER与6个 SOTA \text{SOTA} SOTA实体匹配方法相比。baselines方案被分为2种类型:无监督实体匹配和有监督实体匹配。
前者的方法不需要任何标签就可以执行实体匹配,包括:(1) ZeroER \text{ZeroER} ZeroER,基于高斯混合模型来学习匹配和不匹配分布的强力生成式实体匹配方法;(2) EMBDI \text{EMBDI} EMBDI,基于属性为中心的图来自动学习元组的嵌入向量,用于实体匹配。该组的方法与 CollaborER \text{CollaborER} CollaborER最相关。
后者需要预定义的标签来匹配元组,包括:(1) DeepMatcher+(DM+) \text{DeepMatcher+(DM+)} DeepMatcher+(DM+),其实现了多个实体匹配方法,并报告了最好的表现,包括: DeepER \text{DeepER} DeepER、 Magellan \text{Magellan} Magellan、 DeepMatcher \text{DeepMatcher} DeepMatcher以及 DeepMatcher \text{DeepMatcher} DeepMatcher的后续工作;(2) GraphER \text{GraphER} GraphER,其使用 GNN \text{GNN} GNN模型在token的表示中集成了语义和结构信息;(3) MCA \text{MCA} MCA,其合并注意力机制至基于序列的模型来从元组中学习用于实体匹配的特征;(4) ERGAN \text{ERGAN} ERGAN:其使用生成对抗网络来增强标签,并预测两个实体是否匹配;(5) DITTO \text{DITTO} DITTO,其利用预训练 Transformers \text{Transformers} Transformers语言模型来微调,并将实体匹配任务转换为句子对分类问题。本组中的方法表明, CollaborER \text{CollaborER} CollaborER在不需要任何人工标签的情况下,能够与有监督实体匹配的 SOTA \text{SOTA} SOTA相媲美。
注意,在评估有监督实体匹配方法时,使用 3 : 1 : 1 3:1:1 3:1:1来将每个数据集划分为训练、验证和测试。为了与有监督的方法进行公平的比较,报告 CollaborER \text{CollaborER} CollaborER在测试集上的效果,表示为 CollaborER-S \text{CollaborER-S} CollaborER-S。为了与无监督的方法进行公开的比较,报告 CollaborER \text{CollaborER} CollaborER在整个数据集上的结果,表示为 CollaborER-U \text{CollaborER-U} CollaborER-U。
2.3 实现细节
略
3. 整体表现
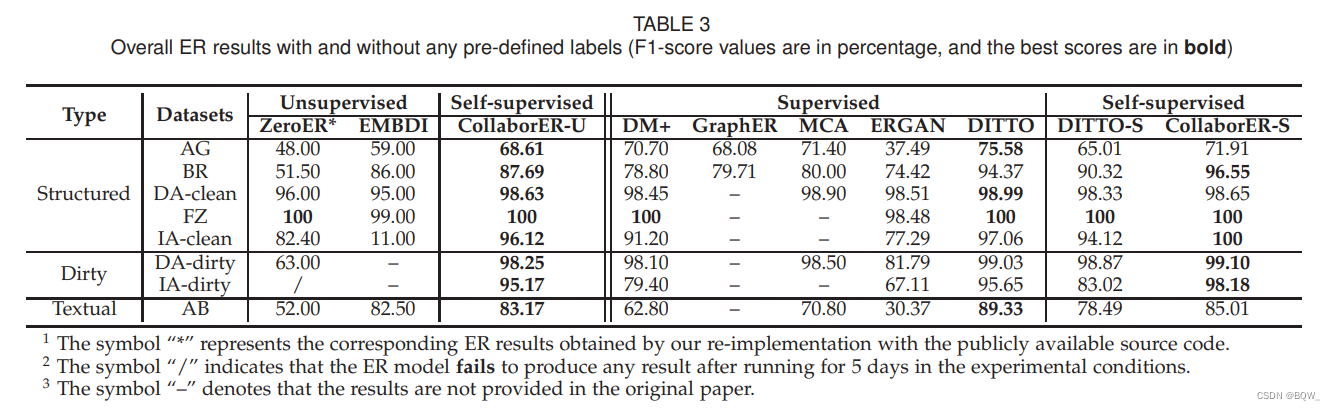
上面展示了所有的实验结果。
3.1 CollaborER \text{CollaborER} CollaborER与无监督方法
显然,
CollaborER
\text{CollaborER}
CollaborER能够显著超越所有的无监督方法。特别地,
CollaborER
\text{CollaborER}
CollaborER能够在最优baseline的基础上带来1%-85%的绝对改善。结果显示
CollaborER
\text{CollaborER}
CollaborER要比
ZeroER
\text{ZeroER}
ZeroER对噪音数据更具有鲁棒性。在dirty数据集上,
CollaborER
\text{CollaborER}
CollaborER的表现仅平均下降
0.67
%
0.67\%
0.67%。然而,
ZeroER
\text{ZeroER}
ZeroER则会下降
33
%
33\%
33%。相反,
CollaborER
\text{CollaborER}
CollaborER会通过
ALG
\text{ALG}
ALG策略生成的可靠标签作为监督信号。此外,
CERT
\text{CERT}
CERT吸收了元组的图特征和句子特征,具有了处理元组噪音特征的容错能力。优秀的实体匹配表现和鲁棒性使得
CollaborER
\text{CollaborER}
CollaborER更加适合真实的实体匹配场景。
3.2 CollaborER \text{CollaborER} CollaborER与有监督方法
CollaborER \text{CollaborER} CollaborER能够与 SOTA \text{SOTA} SOTA的监督方法相媲美。具体来说, CollaborER \text{CollaborER} CollaborER在5个数据集上甚至比最好的有监督方法高平均 1.54 % 1.54\% 1.54%。虽然 CollaborER \text{CollaborER} CollaborER在另外三个数据集上的表现差于 DITTO \text{DITTO} DITTO,但 F 1 F1 F1值差距不会超过4%。这真的非常有效,因为 CollaborER \text{CollaborER} CollaborER不需要人工参与。相反, DITTO \text{DITTO} DITTO需要充分数量的标注,这代价昂贵且耗时。为了进一步的比较 CollaborER \text{CollaborER} CollaborER和 DITTO \text{DITTO} DITTO,评估了使用 ALG \text{ALG} ALG生成伪标签训练的 DITTO \text{DITTO} DITTO,记为 DITTO-S \text{DITTO-S} DITTO-S。可以观察到, DITTO-S \text{DITTO-S} DITTO-S的表现要差于 CollaborER \text{CollaborER} CollaborER。原因是 DITTO-S \text{DITTO-S} DITTO-S将实体看作是句子,不能够考虑实体丰富的语言信息。相反, CollaborER \text{CollaborER} CollaborER通过挖掘句子特征和图特征来捕获实体丰富语义的能力。
此外, CollaborER \text{CollaborER} CollaborER和 ERGAN \text{ERGAN} ERGAN都是生成伪标签来改善实体匹配的目标。然而,可以观察到 CollaborER \text{CollaborER} CollaborER的结果优于 ERGAN \text{ERGAN} ERGAN。具体来说, CollaborER \text{CollaborER} CollaborER能够在 F 1 F1 F1上带来平均23%的改善,相较于 ERGAN \text{ERGAN} ERGAN。 ERGAN \text{ERGAN} ERGAN的性能较长是因为 GAN \text{GAN} GAN本身。更具体的来说, GAN \text{GAN} GAN的训练过程是不稳定的,从而导致生成的伪标签质量较差,训练效果不理想。通过分析发现, ERGAN \text{ERGAN} ERGAN生成的正样本和负样本的平均准确率为88%和89%。然而, CollaborER \text{CollaborER} CollaborER生成的正负标签准确率为99%和97%。
4. 消融实验
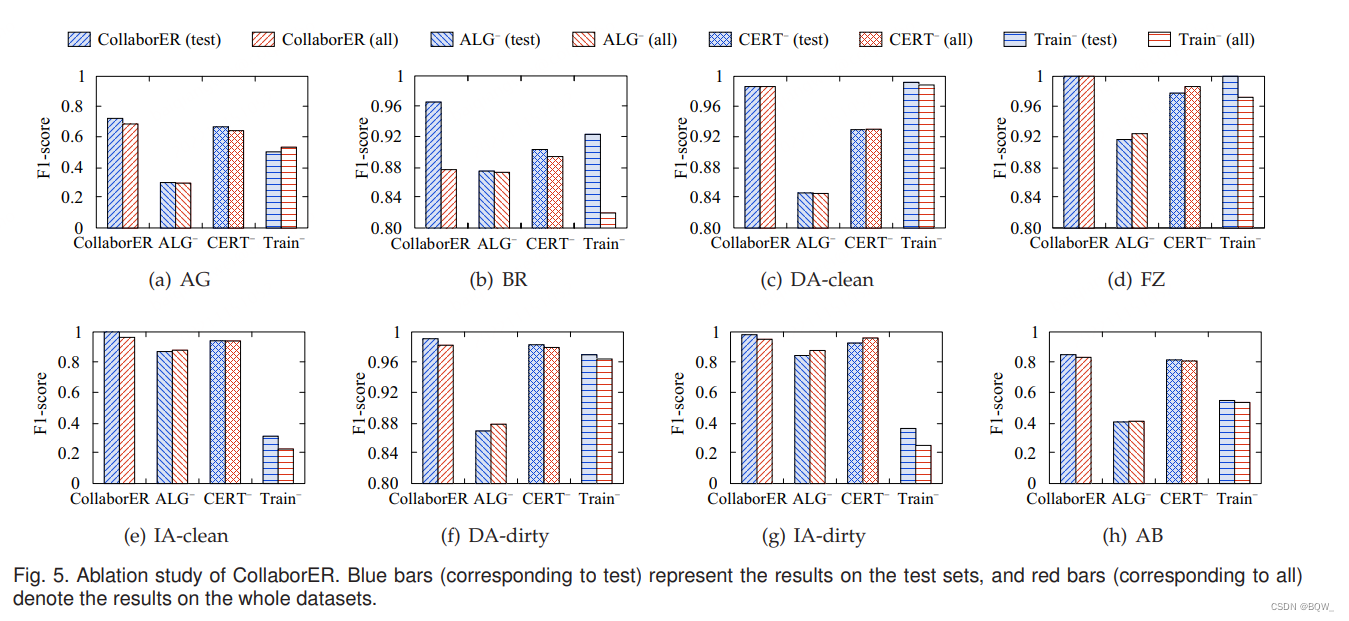
结果如上图所示,横坐标列出的标签有如下含义:(1) CollaborER表示所有的优化均已使用的效果;(2)
ALG-
\text{ALG-}
ALG-表示不使用
ALG
\text{ALG}
ALG的
CollaborER
\text{CollaborER}
CollaborER效果;(3)
CERT-
\text{CERT-}
CERT-表示不使用
CERT
\text{CERT}
CERT的
CollaborER
\text{CollaborER}
CollaborER效果;(4)
Train-
\text{Train-}
Train-表示不进行训练的
CollaborER
\text{CollaborER}
CollaborER。
4.1 CollaborER vs CollaborER w/o ALG \text{CollaborER vs CollaborER w/o ALG} CollaborER vs CollaborER w/o ALG
ALG \text{ALG} ALG包含两个组件: RPLG \text{RPLG} RPLG和 SNLG \text{SNLG} SNLG。因为 CollaborER \text{CollaborER} CollaborER不能够在没有 RPLG \text{RPLG} RPLG下工作,所以专注在研究 SNLG \text{SNLG} SNLG的有效性,通过将其替换为随机负样本生成方法。可以发现 F1 \text{F1} F1值平均掉17.87%。这也证明了基于语义相似度生成具有"挑战"的负样本非常有助于实体匹配模型。实验也发现 SNLG \text{SNLG} SNLG在 FZ \text{FZ} FZ数据集上带来不超过8.33%的改进,这是因为该数据集相对容易。
4.2 CollaborER vs CollaborER w/o CERT \text{CollaborER vs CollaborER w/o CERT} CollaborER vs CollaborER w/o CERT
本文提出的 CERT \text{CERT} CERT和现有微调预训练语言模型的差别是使用图特征来辅助微调过程。通过将 CERT \text{CERT} CERT中的 MRGFL \text{MRGFL} MRGFL移除, CollaborER \text{CollaborER} CollaborER在8个实验数据集上F1值平均掉3%个点。特别地,在 DA-clean \text{DA-clean} DA-clean数据集上 F 1 F1 F1值下降5%。这也说明了学习元组的图特征对于提高实体匹配的表现必不可少。
4.3 CollaborER vs CollaborER w/o Train \text{CollaborER vs CollaborER w/o Train} CollaborER vs CollaborER w/o Train
这里探索了不使用任何训练过程的 CollaborER \text{CollaborER} CollaborER。在这种场景中, CollaborER \text{CollaborER} CollaborER只能纯基于 RPLG \text{RPLG} RPLG来执行实体匹配,不能基于语义相似度来自动发现匹配的元组对。值得注意的是,单独的 RPLG \text{RPLG} RPLG就能实现可观的结果。由于 RPLG \text{RPLG} RPLG主要的通用对于各种数据集上的实体匹配,在不需要任何训练时间消耗的情况下用于执行实体匹配。
5. 进一步实验
5.1 图尺度分析
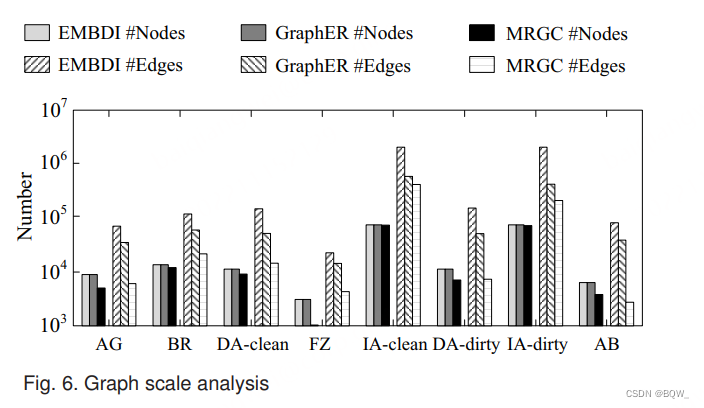
第一组实验是比较由 MRGC \text{MRGC} MRGC和其他实体匹配方法 ( EMBDI , GraphER ) (\text{EMBDI},\text{GraphER}) (EMBDI,GraphER)中的图构建方法生成图的尺寸。上图描述了每个数据集生成图的节点和边数量。显然, MRGC \text{MRGC} MRGC相较于其他方法生成更小的图。图的尺寸极大减少能够节约存储和训练的内存,并降低训练代价。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)