OpenMLDB: 拓展Spark源码实现高性能Join
简介Spark是目前最流行的分布式大数据批处理框架,使用Spark可以轻易地实现上百G甚至T级别数据的SQL运算,例如单行特征计算或者多表的Join拼接。OpenMLDB是针对AI场景优化的开源数据库项目,实现了数据与计算一致性的离线MPP场景和在线OLTP场景计算引擎。其实MPP引擎可基于Spark实现,并通过拓展Spark源码实现数倍性能提升。Spark本身实现也非常高效,基于Antlr实现的
简介
Spark是目前最流行的分布式大数据批处理框架,使用Spark可以轻易地实现上百G甚至T级别数据的SQL运算,例如单行特征计算或者多表的Join拼接。
OpenMLDB是针对AI场景优化的开源数据库项目,实现了数据与计算一致性的离线MPP场景和在线OLTP场景计算引擎。其实MPP引擎可基于Spark实现,并通过拓展Spark源码实现数倍性能提升。
Spark本身实现也非常高效,基于Antlr实现的了标准ANSI SQL的词法解析、语法分析,还有在Catalyst模块中实现大量SQL静态优化,然后转成分布式RDD计算,底层数据结构是使用了Java Unsafe API来自定义内存分布的UnsafeRow,还依赖Janino JIT编译器为计算方法动态生成优化后的JVM bytecode。但在拓展性上仍有改进空间,尤其针对机器学习计算场景的需求虽能满足但不高效,本文以LastJoin为例介绍OpenMLDB如何通过拓展Spark源码来实现数倍甚至数十倍性能提升。
机器学习场景LastJoin
LastJoin是一种AI场景引入的特殊拼表类型,是LeftJoin的变种,在满足Join条件的前提下,左表的每一行只拼取右表符合一提交的最后一行。LastJoin的语义特性,可以保证拼表后输出结果的行数与输入的左表一致。在机器学习场景中就是维持了输入的样本表数量一致,不会因为拼表等数据操作导致最终的样本数量增加或者减少,这种方式对在线服务支持比较友好也更符合科学家建模需求。

以技术保护的角度考虑,LastJoin的设计和实现均为第四范式(北京)技术有限公司的专利,公开号为111611245A,公开日为2020-09-01。包含LastJoin功能的OpenMLDB项目代码以Apache 2.0协议在Github中开源,所有用户都可放心使用。

基于Spark的LastJoin实现
由于LastJoin类型并非ANSI SQL中的标准,因此在SparkSQL等主流计算平台中都没有实现,为了实现类似功能用户只能通过更底层的DataFrame或RDD等算子来实现。基于Spark算子实现LastJoin的思路是首先对左表添加索引列,然后使用标准LeftOuterJoin,最后对拼接结果进行reduce和去掉索引行,虽然可以实现LastJoin语义但性能还是有很大瓶颈。
相比于兼容SQL功能和语法,Spark的另一个特点是用户可以通过map、reduce、groupby等接口和自定义UDF的方式来实现标准SQL所不支持的数值计算逻辑。但Join功能用户却无法通过DataFrame或者RDD API来拓展实现,因为拼表的实现是在Spark Catalyst物理节点中实现的,涉及了shuffle后多个internal row的拼接,以及生成Java源码字符串进行JIT的过程,而且根据不同的输入表数据量,Spark内部会适时选择BrocastHashJoin、SortMergeJoin或ShuffleHashJoin来实现,普通用户无法用RDD API来拓展这些拼表实现算法。
在OpenMLDB项目中可以查看完整的Spark LastJoin实现,代码地址为 https://github.com/4paradigm/OpenMLDB/blob/main/java/openmldb-batch/src/main/scala/com/_4paradigm/openmldb/batch/nodes/JoinPlan.scala 。
第一步是对输入的左表进行索引列扩充,扩充方式有多种实现,只要添加的索引列每一行有unique id即可,下面是第一步的实现代码。
// Add the index column for Spark DataFrame
def addIndexColumn(spark: SparkSession, df: DataFrame, indexColName: String, method: String): DataFrame = {
logger.info("Add the indexColName(%s) to Spark DataFrame(%s)".format(indexColName, df.toString()))
method.toLowerCase() match {
case "zipwithuniqueid" | "zip_withunique_id" => addColumnByZipWithUniqueId(spark, df, indexColName)
case "zipwithindex" | "zip_with_index" => addColumnByZipWithIndex(spark, df, indexColName)
case "monotonicallyincreasingid" | "monotonically_increasing_id" =>
addColumnByMonotonicallyIncreasingId(spark, df, indexColName)
case _ => throw new HybridSeException("Unsupported add index column method: " + method)
}
}
def addColumnByZipWithUniqueId(spark: SparkSession, df: DataFrame, indexColName: String = null): DataFrame = {
logger.info("Use zipWithUniqueId to generate index column")
val indexedRDD = df.rdd.zipWithUniqueId().map {
case (row, id) => Row.fromSeq(row.toSeq :+ id)
}
spark.createDataFrame(indexedRDD, df.schema.add(indexColName, LongType))
}
def addColumnByZipWithIndex(spark: SparkSession, df: DataFrame, indexColName: String = null): DataFrame = {
logger.info("Use zipWithIndex to generate index column")
val indexedRDD = df.rdd.zipWithIndex().map {
case (row, id) => Row.fromSeq(row.toSeq :+ id)
}
spark.createDataFrame(indexedRDD, df.schema.add(indexColName, LongType))
}
def addColumnByMonotonicallyIncreasingId(spark: SparkSession,
df: DataFrame, indexColName: String = null): DataFrame = {
logger.info("Use monotonicallyIncreasingId to generate index column")
df.withColumn(indexColName, monotonically_increasing_id())
}
第二步是进行标准的LeftOuterJoin,由于OpenMLDB底层是基于C++实现,因此多个join condition的表达式都要转成Spark表达式(封装成Spark Column对象),然后调用Spark DataFrame的join函数即可,拼接类型使用“left”或者“left_outer"。
val joined = leftDf.join(rightDf, joinConditions.reduce(_ && _), "left")
第三步是对拼接后的表进行reduce,因为通过LeftOuterJoin有可能对输入数据进行扩充,也就是1:N的变换,而所有新增的行都拥有第一步进行索引列拓展的unique id,因此针对unique id进行reduce即可,这里使用Spark DataFrame的groupByKey和mapGroups接口(注意Spark 2.0以下不支持此API),同时如果有额外的排序字段还可以取得每个组的最大值或最小值。
val distinct = joined
.groupByKey {
row => row.getLong(indexColIdx)
}
.mapGroups {
case (_, iter) =>
val timeExtractor = SparkRowUtil.createOrderKeyExtractor(
timeIdxInJoined, timeColType, nullable=false)
if (isAsc) {
iter.maxBy(row => {
if (row.isNullAt(timeIdxInJoined)) {
Long.MinValue
} else {
timeExtractor.apply(row)
}
})
} else {
iter.minBy(row => {
if (row.isNullAt(timeIdxInJoined)) {
Long.MaxValue
} else {
timeExtractor.apply(row)
}
})
}
}(RowEncoder(joined.schema))
最后一步只是去掉索引列即可,通过预先指定的索引列名即可实现。
distinct.drop(indexName)
总结一下基于Spark算子实现的LastJoin方案,这是目前基于Spark编程接口最高效的实现了,对于Spark 1.6等低版本还需要使用mapPartition等接口来实现类似mapGroups的功能。由于是基于LeftOuterJoin实现,因此LastJoin的这种实现比LeftOuterJoin还差,实际输出的数据量反而是更少的,对于左表与右表有大量拼接条件能满足的情况下,整体内存消耗量还是也是非常大的。因此下面介绍基于Spark源码修改实现的原生LastJoin,可以避免上述问题。
拓展Spark源码的LastJoin实现
原生LastJoin实现,是指直接在Spark源码上实现的LastJoin功能,而不是基于Spark DataFrame和LeftOuterJoin来实现,在性能和内存消耗上有巨大的优化。OpenMLDB使用了定制优化的Spark distribution,其中依赖的Spark源码也在Github中开源 GitHub - 4paradigm/spark at v3.0.0-openmldb 。
要支持原生的LastJoin,首先在JoinType上就需要加上last语法,由于Spark基于Antlr实现的SQL语法解析也会直接把SQL join类型转成JoinType,因此只需要修改JoinType.scala文件即可。
object JoinType {
def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match {
case "inner" => Inner
case "outer" | "full" | "fullouter" => FullOuter
case "leftouter" | "left" => LeftOuter
// Add by 4Paradigm
case "last" => LastJoinType
case "rightouter" | "right" => RightOuter
case "leftsemi" | "semi" => LeftSemi
case "leftanti" | "anti" => LeftAnti
case "cross" => Cross
case _ =>
val supported = Seq(
"inner",
"outer", "full", "fullouter", "full_outer",
"last", "leftouter", "left", "left_outer",
"rightouter", "right", "right_outer",
"leftsemi", "left_semi", "semi",
"leftanti", "left_anti", "anti",
"cross")
throw new IllegalArgumentException(s"Unsupported join type '$typ'. " +
"Supported join types include: " + supported.mkString("'", "', '", "'") + ".")
}
}
其中LastJoinType类型的实现如下。
// Add by 4Paradigm
case object LastJoinType extends JoinType {
override def sql: String = "LAST"
}
在Spark源码中,还有一些语法检查类和优化器类都会检查内部支持的join type,因此在Analyzer.scala、Optimizer.scala、basicLogicalOperators.scala、SparkStrategies.scala这几个文件中都需要有简单都修改,scala switch case支持都枚举类型中增加对新join type的支持,这里不一一赘述了,只要解析和运行时缺少对新枚举类型支持就加上即可。
// the output list looks like: join keys, columns from left, columns from right
val projectList = joinType match {
case LeftOuter =>
leftKeys ++ lUniqueOutput ++ rUniqueOutput.map(_.withNullability(true))
// Add by 4Paradigm
case LastJoinType =>
leftKeys ++ lUniqueOutput ++ rUniqueOutput.map(_.withNullability(true))
case LeftExistence(_) =>
leftKeys ++ lUniqueOutput
case RightOuter =>
rightKeys ++ lUniqueOutput.map(_.withNullability(true)) ++ rUniqueOutput
case FullOuter =>
// in full outer join, joinCols should be non-null if there is.
val joinedCols = joinPairs.map { case (l, r) => Alias(Coalesce(Seq(l, r)), l.name)() }
joinedCols ++
lUniqueOutput.map(_.withNullability(true)) ++
rUniqueOutput.map(_.withNullability(true))
case _ : InnerLike =>
leftKeys ++ lUniqueOutput ++ rUniqueOutput
case _ =>
sys.error("Unsupported natural join type " + joinType)
}
前面语法解析和数据结构支持新的join type后,重点就是来修改三种Spark join物理算子的实现代码了。首先是右表比较小时Spark会自动优化成BrocastHashJoin,这时右表通过broadcast拷贝到所有executor的内存里,遍历右表可以找到所有符合join condiction的行,如果右表没有符合条件则保留左表internal row并且右表字段值为null,如果有一行或多行符合条件就合并两个internal row到输出internal row里,代码实现在BroadcastHashJoinExec.scala中。因为新增了join type枚举类型,因此我们修改这两个方法来表示支持这种join type,并且通过参数来区分和之前join type的实现。
override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
joinType match {
case _: InnerLike => codegenInner(ctx, input)
case LeftOuter | RightOuter => codegenOuter(ctx, input)
// Add by 4Paradigm
case LastJoinType => codegenOuter(ctx, input, true)
case LeftSemi => codegenSemi(ctx, input)
case LeftAnti => codegenAnti(ctx, input)
case j: ExistenceJoin => codegenExistence(ctx, input)
case x =>
throw new IllegalArgumentException(
s"BroadcastHashJoin should not take $x as the JoinType")
}
}
BrocastHashJoin的核心实现代码也是使用JIT来实现的,因此我们需要修改codegen成Java代码字符串的逻辑,在codegenOuter函数中,保留原来LeftOuterJoin的实现,并且使用前面的参数来区分是否使用新的join type实现。这里修改的逻辑也非常简单,因为新的join type只要保证右表有一行数据拼到后就返回,因此不需要通过while来遍历右表候选集。
// Add by 4Paradigm
if (isLastJoin) {
s"""
|// generate join key for stream side
|${keyEv.code}
|// find matches from HashRelation
|$iteratorCls $matches = $anyNull ? null : ($iteratorCls)$relationTerm.get(${keyEv.value});
|boolean $found = false;
|// the last iteration of this loop is to emit an empty row if there is no matched rows.
|if ($matches != null && $matches.hasNext() || !$found) {
| UnsafeRow $matched = $matches != null && $matches.hasNext() ?
| (UnsafeRow) $matches.next() : null;
| ${checkCondition.trim}
| if ($conditionPassed) {
| $found = true;
| $numOutput.add(1);
| ${consume(ctx, resultVars)}
| }
|}
""".stripMargin
}
然后是修改SortMergeJoin的实现来支持新的join type,如果右表比较大不能直接broacast那么大概率会使用SortMergeJoin实现,实现原理和前面的修改类似,不一样的是这里不是通过JIT实现的,因此直接修改拼表的逻辑即可,保证只要有一行符合条件即可拼接并返回。
private def bufferMatchingRows(): Unit = {
assert(streamedRowKey != null)
assert(!streamedRowKey.anyNull)
assert(bufferedRowKey != null)
assert(!bufferedRowKey.anyNull)
assert(keyOrdering.compare(streamedRowKey, bufferedRowKey) == 0)
// This join key may have been produced by a mutable projection, so we need to make a copy:
matchJoinKey = streamedRowKey.copy()
bufferedMatches.clear()
// Add by 4Paradigm
if (isLastJoin) {
bufferedMatches.add(bufferedRow.asInstanceOf[UnsafeRow])
advancedBufferedToRowWithNullFreeJoinKey()
} else {
do {
bufferedMatches.add(bufferedRow.asInstanceOf[UnsafeRow])
advancedBufferedToRowWithNullFreeJoinKey()
} while (bufferedRow != null && keyOrdering.compare(streamedRowKey, bufferedRowKey) == 0)
}
}
最后是ShuffleHashJoin的实现,对应的实现在子类HashJoin.scala中,原理与前面也类似,调用outerJoin函数遍历stream table的时候,修改核心的遍历逻辑,保证左表在拼不到时保留并添加null,在拼到一行时立即返回即可。
private def outerJoin(
streamedIter: Iterator[InternalRow],
hashedRelation: HashedRelation,
isLastJoin: Boolean = false): Iterator[InternalRow] = {
val joinedRow = new JoinedRow()
val keyGenerator = streamSideKeyGenerator()
val nullRow = new GenericInternalRow(buildPlan.output.length)
streamedIter.flatMap { currentRow =>
val rowKey = keyGenerator(currentRow)
joinedRow.withLeft(currentRow)
val buildIter = hashedRelation.get(rowKey)
new RowIterator {
private var found = false
override def advanceNext(): Boolean = {
// Add by 4Paradigm to support last join
if (isLastJoin && found) {
return false
}
// Add by 4Paradigm to support last join
if (isLastJoin) {
if (buildIter != null && buildIter.hasNext) {
val nextBuildRow = buildIter.next()
if (boundCondition(joinedRow.withRight(nextBuildRow))) {
found = true
return true
}
}
} else {
while (buildIter != null && buildIter.hasNext) {
val nextBuildRow = buildIter.next()
if (boundCondition(joinedRow.withRight(nextBuildRow))) {
found = true
return true
}
}
}
if (!found) {
joinedRow.withRight(nullRow)
found = true
return true
}
false
}
override def getRow: InternalRow = joinedRow
}.toScala
}
}
通过对前面JoinType和三种Join物理节点的修改,用户就可以像其他内置join type一样,使用SQL或者DataFrame接口来做新的拼表逻辑了,拼表后保证输出行数与左表一致,结果和最前面基于LeftOuterJoin + dropDuplicated的方案也是一样的。
LastJoin实现性能对比
那么既然实现的新的Join算法,我们就对比前面两种方案的性能吧,前面直接基于最新的Spark 3.0开源版,不修改Spark优化器的情况下对于小数据会使用broadcast join进行性能优化,后者直接使用修改Spark源码编译后的版本,在小数据下Spark也会优化成broadcast join实现。
首先是测试join condiction能拼接多行的情况,对于LeftOuterJoin由于能拼接多行,因此第一个阶段使用LeftOuterJoin输出的表会大很多,第二阶段dropDuplication也会更耗时,而LastJoin因为在shuffle时拼接到单行就返回了,因此不会因为拼接多行导致性能下降。

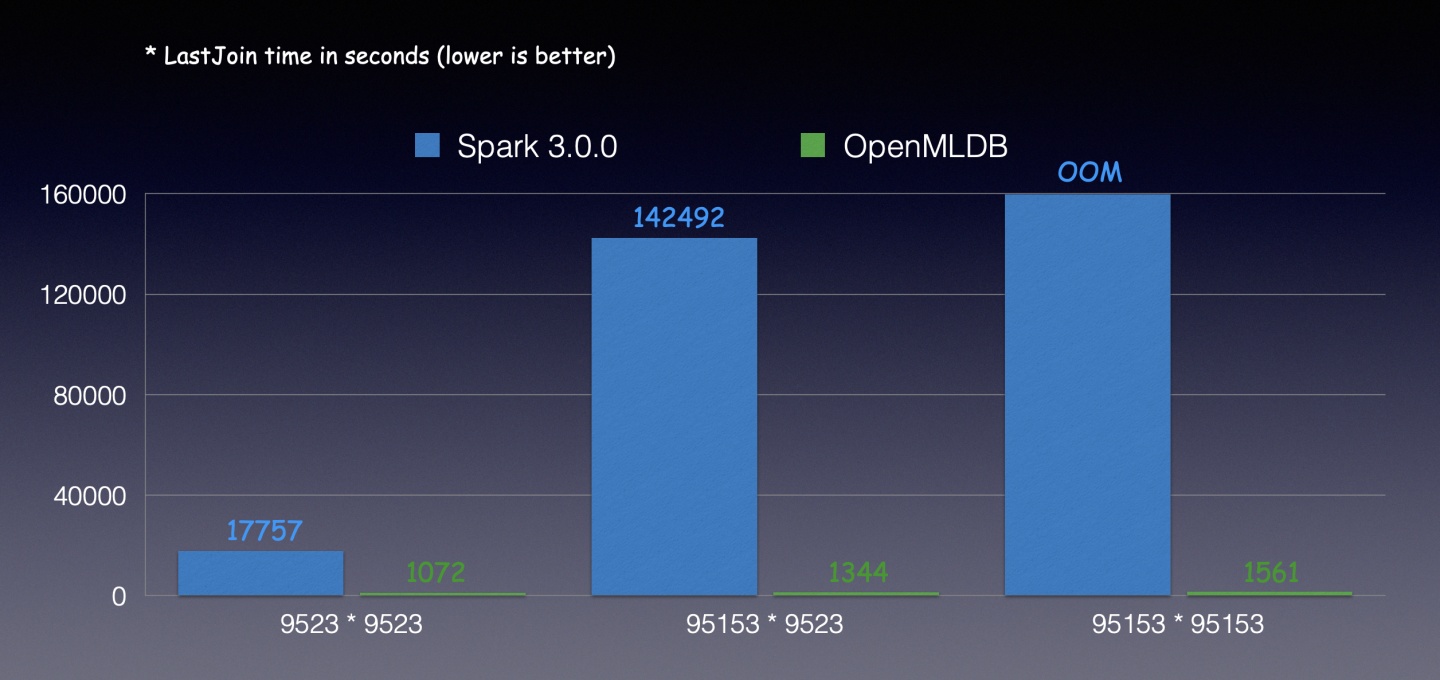
从结果上看性能差异也很明显,由于右表数据量都比较小,因此这三组数据Spark都会优化成broadcast join的实现,由于LeftOuterJoin会拼接多行,因此性能就比新的LastJoin慢很多,当数据量增大时LeftOuterJoin拼接的结果表数据量更加爆炸,性能成指数级下降,与LastJoin有数十倍到数百倍的差异,最后还可能因为OOM导致失败,而LastJoin不会因为数据量增大有明显的性能下降。
右表能拼接多行对LeftOuterJoin + dropDupilicated方案多少有些不公平,因此我们新增一个测试场景,拼接时保证左表只可能与右表的一行拼接成功,这样无论是LeftOuterJoin还是LastJoin结果都是一模一样的,这种场景下性能对比更有意义。

从结果上看性能差异已经没有那么明显了,但LastJoin还是会比前者方案快接近一倍,前面两组右表数据量比较小被Spark优化成broadcast join实现,最后一组没有优化会使用sorge merge join实现。从BroadcastHashJoin和SortMergeJoin最终生成的代码可以看到,如果右表只有一行拼接成功的话,LeftOuterJoin和LastJoin的实现逻辑基本是一模一样的,那么性能差异主要在于前者方案还需要进行一次dropDuplicated计算,这个stage虽然计算复杂度不高但在小数据规模下耗时占比还是比较大,无论是哪种测试方案在这种特殊的拼表场景下修改Spark源码还是性能最优的实现方案。
技术总结
最后简单总结下,OpenMLDB项目通过理解和修改Spark源码,可以根据业务场景来实现新的拼表算法逻辑,从性能上看比使用原生Spark接口实现性能可以有巨大的提升。Spark源码涉及SQL语法解析、Catalyst逻辑计划优化、JIT代码动态编译等,拥有这些基础后可以对Spark功能和性能进行更底层的拓展,后续OpenMLDB也会继续在分享更多Spark优化相关技术细节,欢迎大家持续交流。
也欢迎更多开发者关注和参与OpenMLDB开源项目。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)