自学大数据:用以生产环境的Hadoop版本比较
一、背景介绍生产环境中,hadoop的版本选择是一个公司架构之时,很重要的一个考虑因素。这篇文章根据就谈谈现在主流的hadoop版本的比较。如果有不同意见,或者指正,希望大家能交流。Apache Hadoop:Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是
一、背景介绍
生产环境中,hadoop的版本选择是一个公司架构之时,很重要的一个考虑因素。这篇文章根据就谈谈现在主流的hadoop版本的比较。如果有不同意见,或者指正,希望大家能交流。
Apache Hadoop:Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成。称为社区版Hadoop。
第三方发行版Hadoop:Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本。其中有很多厂家在Apache Hadoop的基础上开发自己的Hadoop产品,比如Cloudera的CDH,Hortonworks的HDP,MapR的MapR产品等。
二、社区版本与第三方发行版本的比较
Apache社区版本
优点:
- 完全开源免费。
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
- 复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
- 复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
- 复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。(可以通过技术解决)
三、第三方发行版本的比较
Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。
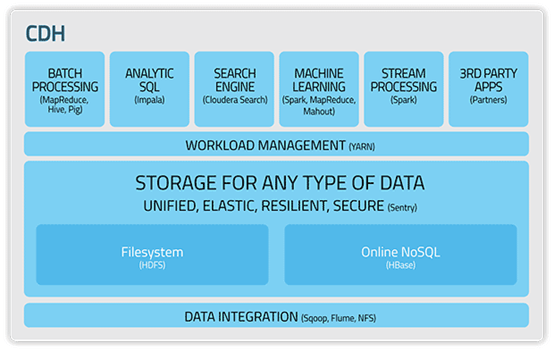
Hortonworks:不拥有任何私有(非开源)修改地使用了100%开源Apache Hadoop的唯一提供商。Hortonworks是第一家使用了Apache HCatalog的元数据服务特性的提供商。并且,它们的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内的Microsft Windows平台上本地运行。
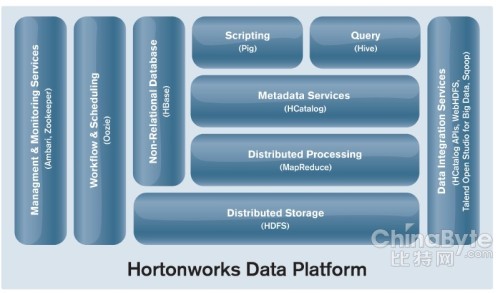
MapR:与竞争者相比,它使用了一些不同的概念,特别是为了获取更好的性能和易用性而支持本地Unix文件系统而不是HDFS(使用非开源的组件)。可以使用本地Unix命令来代替Hadoop命令。除此之外,MapR还凭借诸如快照、镜像或有状态的故障恢复之类的高可用性特性来与其他竞争者相区别。该公司也领导着Apache Drill项目,本项目是Google的Dremel的开源项目的重新实现,目的是在Hadoop数据上执行类似SQL的查询以提供实时处理。
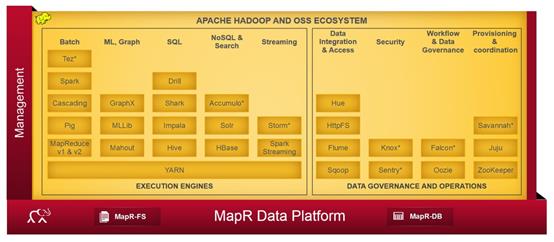
Amazon Elastic Map Reduce(EMR):区别于其他提供商的是,这是一个托管的解决方案,其运行在由Amazon Elastic Compute Cloud(Amazon EC2)和Amzon Simple Strorage Service(Amzon S3)组成的网络规模的基础设施之上。除了Amazon的发行版本之外,你也可以在EMR上使用MapR。临时集群是主要的使用情形。如果你需要一次性的或不常见的大数据处理,EMR可能会为你节省大笔开支。然而,这也存在不利之处。其只包含了Hadoop生态系统中Pig和Hive项目,在默认情况下不包含其他很多项目。并且,EMR是高度优化成与S3中的数据一起工作的,这种方式会有较高的延时并且不会定位位于你的计算节点上的数据。所以处于EMR上的文件IO相比于你自己的Hadoop集群或你的私有EC2集群来说会慢很多,并有更大的延时。
四、选择决定
当我们决定是否采用某个软件用于开源环境时,通常需要考虑以下几个因素:
(1)是否为开源软件,即是否免费。
(2) 是否有稳定版,这个一般软件官方网站会给出说明。
(3) 是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4) 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
综上所述,考虑到大数据平台高效的部署和安装,中心化的配置管理,使用过程中的稳定性、兼容性、扩展性,以及未来较为简单、高效的运维,遇到问题低廉的解决成本。
个人建议使用第三方发行版本。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)