初识FlinkCDC
FlinkCDC (Flink Change Data Capture) 是一个基于 Apache Flink 的开源项目,是flink生态的一部分,利用flink强大的流处理能力,能实时数据变更捕获和同步。它主要用于从数据库中捕获变更数据,并将这些变更数据流式地传输到流处理引擎中,以便进行实时处理、分析和同步。FlinkCDC 可以监控数据库中的表,并实时捕获表中的 INSERT、UPDATE、
目录
1、什么是flinkCDC
FlinkCDC (Flink Change Data Capture) 是一个基于 Apache Flink 的开源项目,是flink生态的一部分,利用flink强大的流处理能力,能实时数据变更捕获和同步。它主要用于从数据库中捕获变更数据,并将这些变更数据流式地传输到流处理引擎中,以便进行实时处理、分析和同步。FlinkCDC 可以监控数据库中的表,并实时捕获表中的 INSERT、UPDATE、DELETE 等数据变更操作,将这些变更以流的形式传输给 Flink 流处理引擎。因此,FlinkCDC 可以帮助用户构建实时数据处理和分析的解决方案,例如实时数据仓库、实时数据分析等。FlinkCDC 针对不同的数据库引擎提供了相应的实现,例如针对 MySQL、PostgreSQL、Oracle 等数据库,均有相应的 FlinkCDC 实现。这使得 FlinkCDC 能够适用于不同类型的数据库,为实时数据变更捕获和处理提供了灵活的选择。
2、centOS安装flink
flink依赖java环境,请预先安装java环境,最好是jdk11版本。
去flink官网下载最新版:Downloads | Apache Flink
我下的是Apache Flink 1.18.0版本。
在linux创建目录,其中checkpoint 、savepoint目录用于存放flinkcdc的检查点,不然会内存不足的错误:
mkdir -p /usr/flink /usr/flink/checkpoint /usr/flink/savepoint
然后把flink上传至liunx。登录liunx,进入
cd /usr/flink解压:
tar -zxvf flink-1.18.0-bin-scala_2.12.tgz修改flink配置文件flink-conf.yaml:
vi /usr/flink/flink-1.18.0/conf/flink-conf.yaml修改以下值,若找不到就新增:
jobmanager.memory.process.size: 3gb #作业管理器进程总内存
taskmanager.numberOfTaskSlots: 5 #任务槽(task slot)数量,每个TaskSlot对应一个CPU核心
taskmanager.memory.managed.size: 64mb #任务管理器托管内存
rest.bind-address: 0.0.0.0 #用于连接flink web UI
rest.address: 0.0.0.0 #用于连接flink web UI
state.checkpoints.dir: file:///usr/flink/checkpoint #用于存放flickcdc检查点
state.savepoints.dir: file:///usr/flink/savepoint #用于存放flickcdc检查点
3、启动flink集群
/usr/flink/flink-1.18.0/bin/start-cluster.sh用jps命令查看是否启动成功:

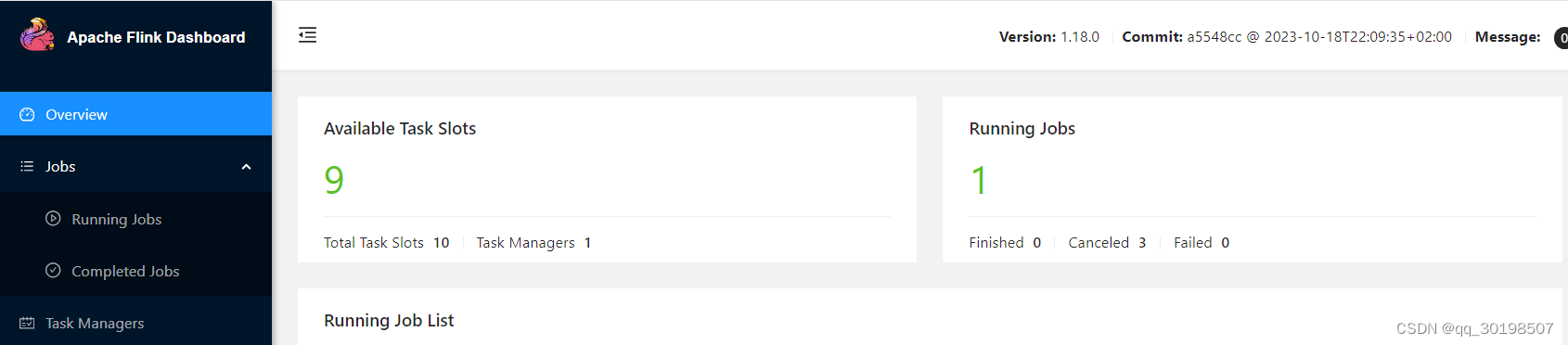
启动完成后再浏览器输入地址:
http://ip:8081/ 把ip替换成你的IP地址,flink默认端口8081,想修改的可以在flink-conf.yaml中修改rest.port: 8081

关闭flink集群
/usr/flink/flink-1.18.0/bin/stop-cluster.sh至此flink安装启动完成。接来下是搞flinkcdc同步oracle至apache doris

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)