
python 使用bs4 解析html页面
python 使用bs4 解析html页面前言前几天要复制一整个html页面的内容到excel表格里,我觉得复制太麻烦所以写一个爬虫自动爬数据简单快捷,页面爬下来以后想获取html标签中的数据结果没有找到比较好的办法所以我就自己研究并整理发上来页面是这个样子的,我们可以看到这个页面大体分为四个部分,而我想要页面上的所有数据,所以我也根据他这四个部分一点点的解析接下来看一下页面的源代码从这个图我们可
·
python 使用bs4 解析html页面
前言
前几天要复制一整个html页面的内容到excel表格里,我觉得复制太麻烦所以写一个爬虫自动爬数据简单快捷,页面爬下来以后想获取html标签中的数据结果没有找到比较好的办法所以我就自己研究并整理发上来
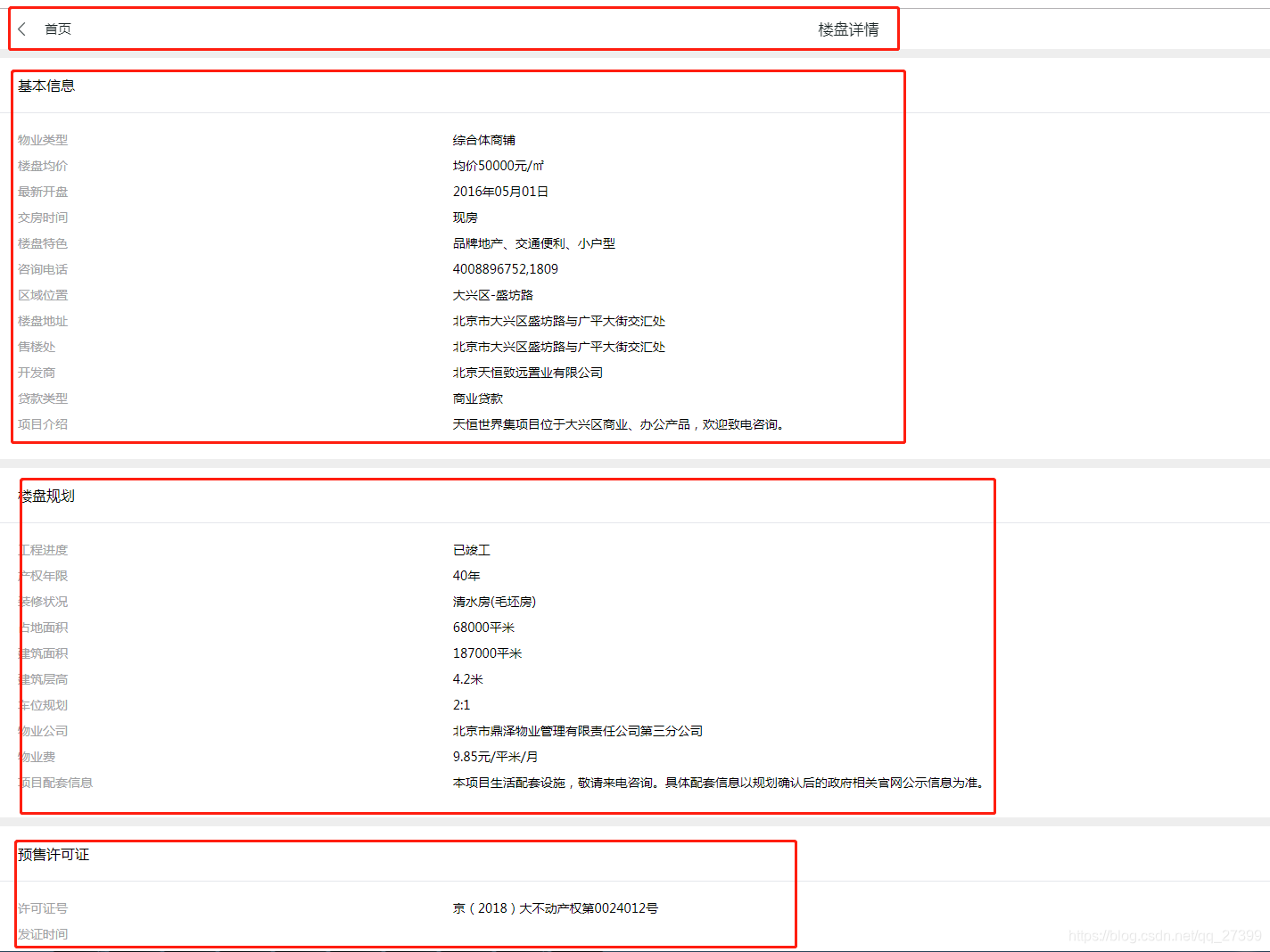
页面是这个样子的,我们可以看到这个页面大体分为四个部分,而我想要页面上的所有数据,所以我也根据他这四个部分一点点的解析
 接下来看一下页面的源代码
接下来看一下页面的源代码
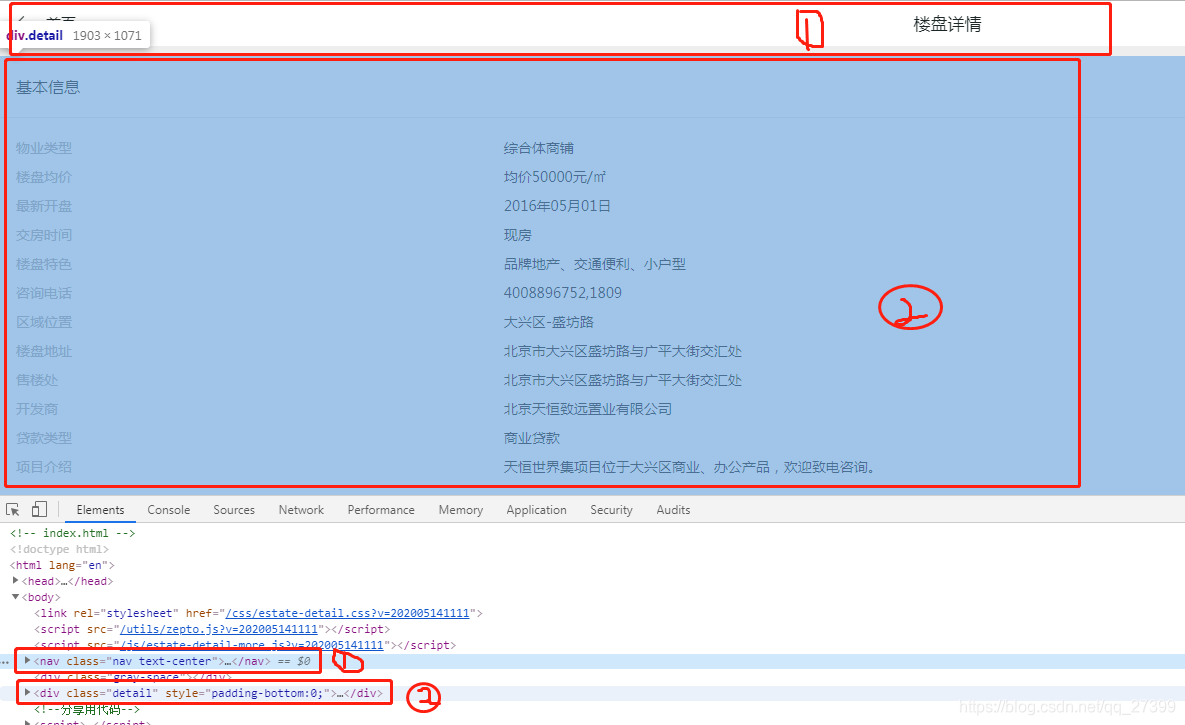
从这个图我们可以看出整个页面分为两部分
上面(1)部分为导航栏在<nav>标签中,(2)部分为详情,包括基本信息,楼盘规划和预售许可证在class="detail"的div标签中
 那我们先看导航栏
那我们先看导航栏
导航栏被放在
#首先获取整个页面,这里我使用的是urllib,
import urllib.request as request
req = request.urlopen(url) #url为你想获取的页面的url
index = req.read() #index为你获取的整个页面
#接下来使用bs4解析这个页面
soup = BeautifulSoup(index, 'html.parser')
#接下来是获取html页面的标签的几个方法
#1.通过标签名获取标签
#soup.div
#这里需要注意的是通过这种方式获取的是整个soup中从上到下数的第一个div标签
#2.通过select选择器获取
#soup.select('.类名')
#soup.select('#id名')
#soup.select('标签名')
#选择器中可以用类名,标签名,id名,这时候我们获得的是一个数组
#接下来我们来获取nav标签中的“首页”
nav=soup.nav
#因为“首页”的位置我们刚才已经分析过了他在nav标签中,所以我们先获取nav标签
#有的可能会问“首页”所在的a标签有类名,我们为什么不通过类名加标签名的方式获取,因为类名可能会有重复的
a_span=nav.select('.switch')[0].span.string
#输出a_span 得到 “首页”
接下来我们获取第二部分详情部分的内容
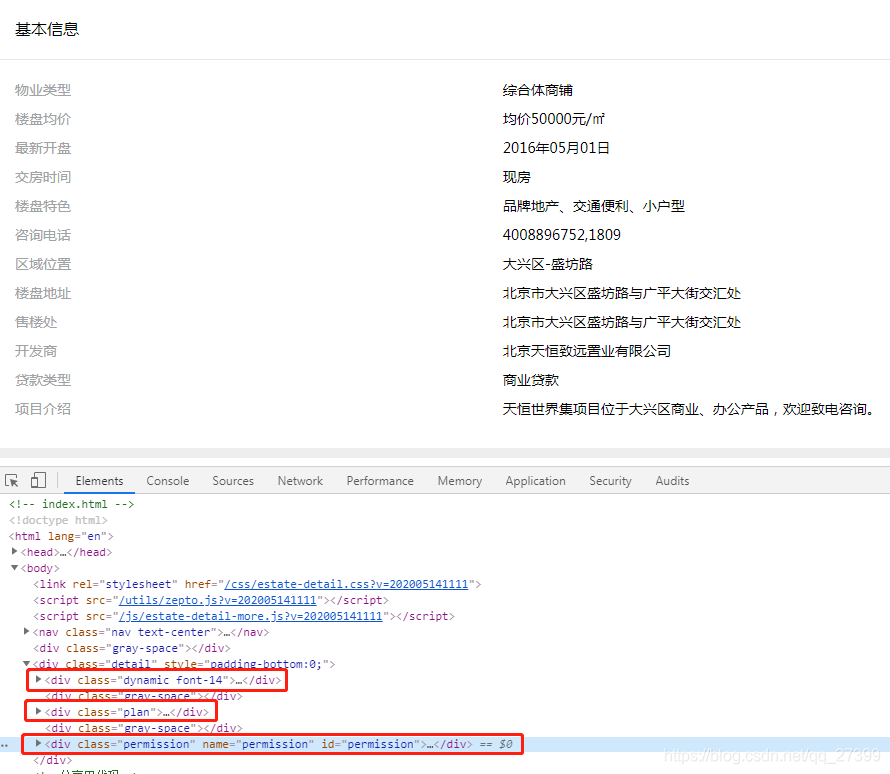
从下图我们可以看出整个详情部分又被三个div分为三个部分,我们可以分别去解析他们,这里我只解析第一部分
 首先根据类名获取整个详情部分部分
首先根据类名获取整个详情部分部分
det = soup.select('.detail')[0]
#接下来根据类名获取详情部分的第一部分
dynamic = det.select('.dynamic')[0]
接下来我们可以看到第一部分的每一行都是一个div,而左边的“物业类型”等标题都放在class="col-25 label" 的<div>中,而标题对应的内容都放在class="col-75 padding-left的<div>中
所以我们可以通过类名一次性获取所有的标题或内容
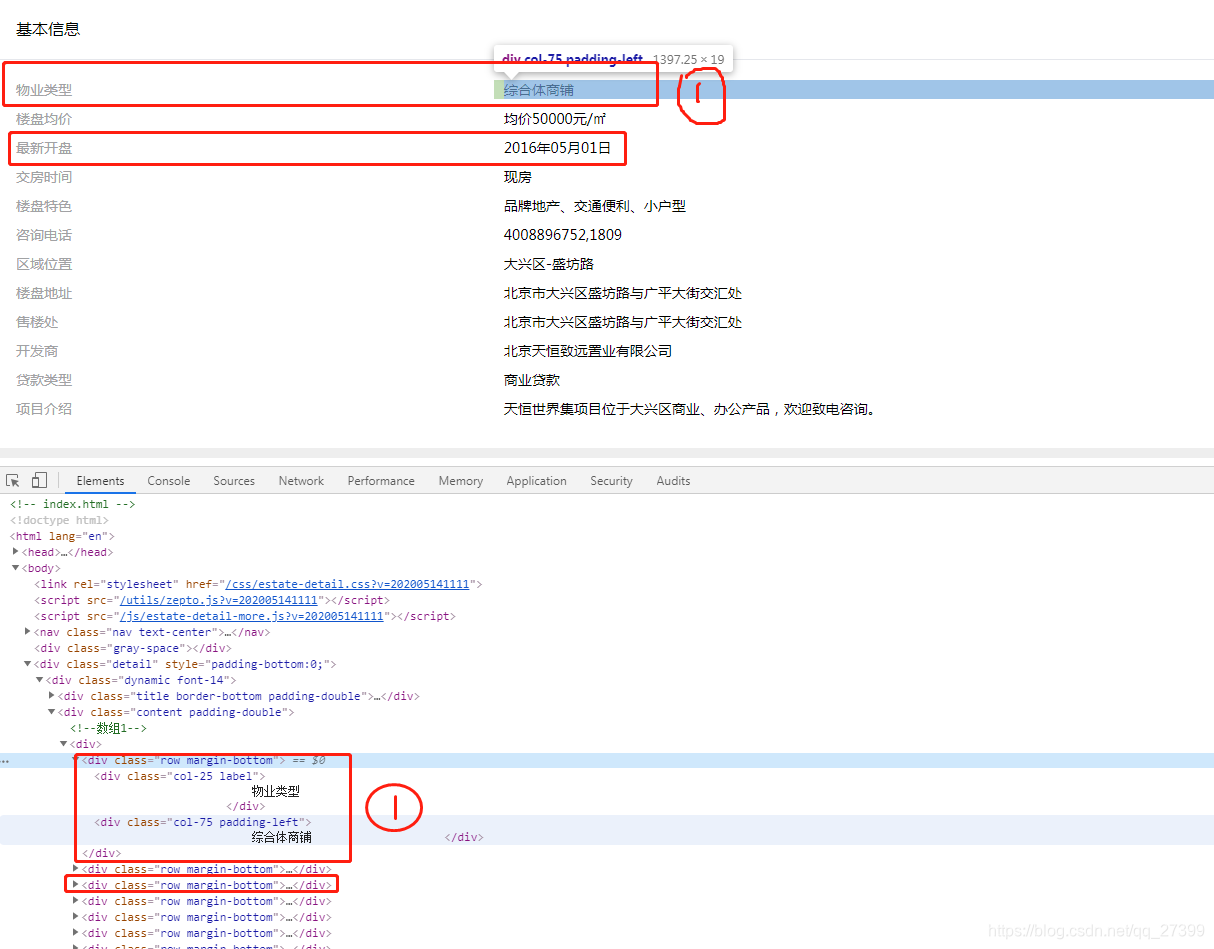
dynamic_content = dynamic.select('.content')[0]
#获取左面标题
dynamic_label = dynamic_content.select('.label')
#获取右面内容
dynamic_left = dynamic_content.select('.padding-left')
#把标题和内容交替存到数组中
left = 0
detali_list=[]
#clernNorR():是我自己写的一个函数用来去除字符串的空格和换行
def clernNorR(str):
return str.replace(" ", "").replace("\n", "").replace("\r", "")
for i in dynamic_label:
detali_list.append(clernNorR(i.string))
detali_list.append(clernNorR(dynamic_left[left].string))
left = left + 1
#输出一下我们的数组看一下结果
for i in detali_list:
print(i)
没问题就是我们想要的内容
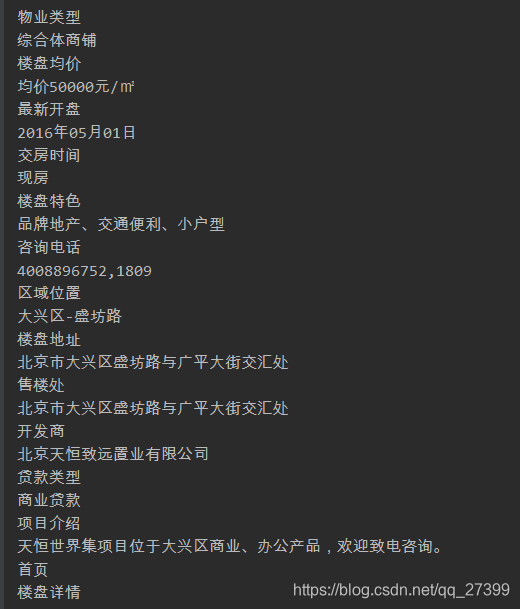 好了那就到这里吧
好了那就到这里吧

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)