
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution阅读笔记
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution可控时空视频超分辨率的时间调制网络论文:https://arxiv.org/pdf/2104.10642v2.pdf代码:https://github.com/CS-GangXu/TMNet研究机构:南开、中科院、腾讯优图本篇笔记主要对整篇论文
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
可控时空视频超分辨率的时间调制网络
论文:https://arxiv.org/pdf/2104.10642v2.pdf
代码:https://github.com/CS-GangXu/TMNet
研究机构:南开、中科院、腾讯优图
本篇笔记主要对整篇论文从头到尾进行阅读分析,本文内容有点多,主要是对不同部分的总结以及图例解释,如果只对模型原理部分有兴趣,可直接观看第四部分。
本文为了详细说明各图、公式在各组件中的情况,所以对原文图片、公式做了切割和拼接,保证该内容是在该组件中生效的。
目录
(1)摘要
时空超分模型(STVSR)目的在于提高低分辨率和低帧率视频,但是目前的方法只能推断在训练中预先定义好的中间帧(也就是说生成固定帧率视频,也就是目前的STVSR方法高帧率不用提高,低帧率会插视频训练时定义的中间帧,帧率固定,本文就不一样了,两帧之间我可以插多个帧),并且没有完全利用相邻帧之间的信息。本文提出TMNet(时间调制网络)进行中间帧插值,并重建高分辨率帧。TMNet可分为两部分:(1)TMB(时间调制块),实现可控的插值。(2)LFC(局部时间特征比较模块)和双向变形的convLSTM模块用于提取短期和长期的运动线索。
(2)引言
当前的设备可以支持高分辨率4K\8K和120FPS\240FPS的视频,通过单图像超分的方法虽然可以提高单个图像的分辨率,但是用户对于视频质量的感官却不行。为了更好的利用视频中空间与时间维度之间的相关性能够同时执行VSR和VFI(video frame interpolation,在这段中这个VFI我感觉他写错了,他写的video frame interpretation)重建。当前方法,仅限于固定帧率视频,无法通过灵活调整中间视频帧获得更好的可视化效果。
TMNet,用于为STVSR插入任意数量的中间帧,如下图

为了TMNet能够在STVSR上插任意数量的中间帧,并进行超分重建,本文提出两个模块
(2.1) TMB
首先在DCN框架下估计两个相邻帧之间的运动,由时间参数定义的任何时刻学习可控插值。
(2.2) 双向变形的convLSTM模块
用于探索短期运动线索的局部特征比较模块,用于融合多帧特征以实现有效的空间对齐和特征扭曲。以及一个用于探索长期运动线索的全局时间特征融合。
(3)相关工作
VFI(video frame interpolation)、VSR(video super-resolution)、STVSR(Space-time video super-resolution)、以及调制网络的相关研究内容。
(4)本文方法介绍

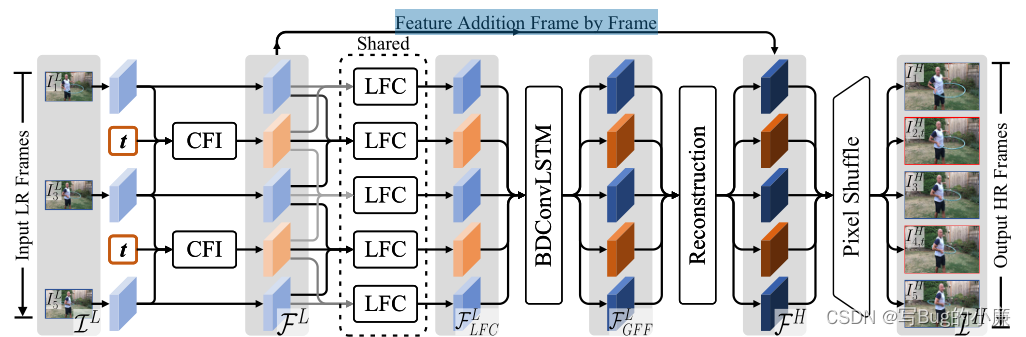
如上图所示,这就是本文的TMNet架构,基本上可以分为四个阶段。(1)CFI可控插值,可控的插入中间帧。(2)LFC,局部特征比较,将短期运动线索信息进行提炼比较,提高每个帧的特征效果。(3)GFF,全局特征融合,将长期运动线索进行提炼融合,提升所有帧的特征。(4)上采样,使用Pixel Shuffle进行高分辨率上采样。
(4.1)CFI
CFI可控的插入中间帧。如下图所示,初始的低分辨率、低帧率的视频帧集合![]() 经过初始化特征提取
经过初始化特征提取![]() ,经过CFI插值之后,生成高帧率低分辨率的视频
,经过CFI插值之后,生成高帧率低分辨率的视频![]() ,送入下个模块。
,送入下个模块。

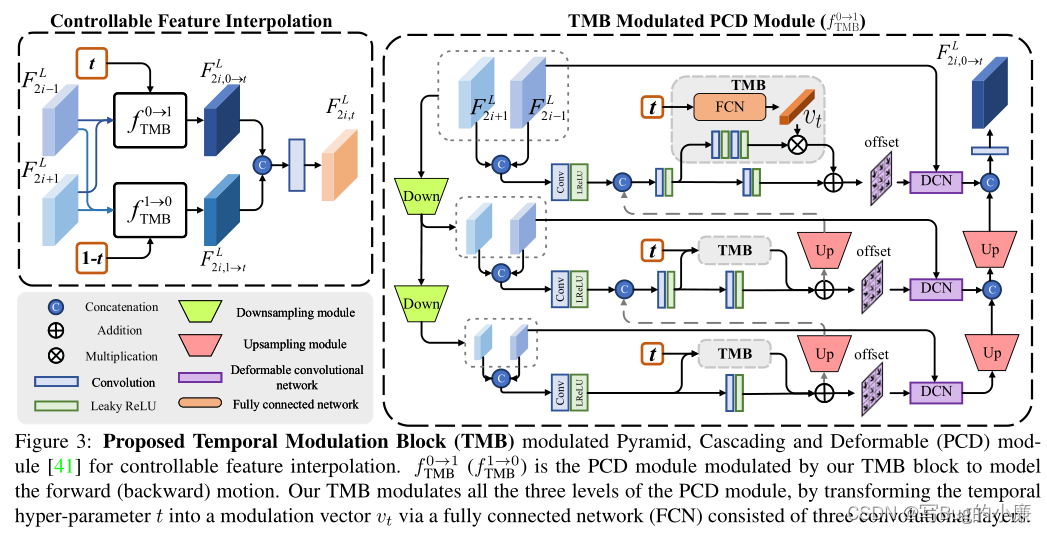
文中PCD(modulated Pyramid, Cascading and Deformable 调制金字塔、级联和可变形) ,下图就是TMB模块实现可控帧插入的结构图,应用在PCD框架上,我们结合图和公式做一下解析。
图左:表示为可控特征插入的结构,
表示正向运动
表示反向运动,在可变参数t的条件下,进行t时刻内的可控的插值,如下方的公式一所示,
表示正向运动生成的插入低分辨率特征,在t时刻根据相邻的低分辨率帧进行生成。
表示反向运动生成的插入低分辨率特征,与正向运动相同。将
。
图右:表示正向运动的TMB在PCD框架中的过程,在金字塔结构中,镁层结构中都通过TMB块获得offset作为DCN的偏移值(DCN的特点就是便宜的多样性,但是难以训练,训练的不稳定性往往会导致补偿溢出),根据offset训练后,与底层训练结果进行逐级级联,获得最终的插入帧。可以在右图中看到TMB模块中的内容,将时间参数t经过FCN(全连接层),输出1*1*64的向量,与每层金字塔中间的卷积进行乘积处理后,在进行相加,输出为偏移值。

![]()
(4.2)时间特征融合
(4.2.1)局部时间特征比较
如下图所示:使用滑动窗口的方式进行特征提取,DCN模块中输入的是两部分内容,一是原始的
特征信息,二是
和
相加之后进行比较,得到提炼后的
信息,最后得到一个特征序列
。

(4.2.2)全局时间特征融合
经过LFC细化后的特征序列保证了短期的一致性,为了保证长期的一致性,本文采用全局特征融合的方式。如下图所示,可以看出LFC序列特征的生成,是通过滑动窗口(生成t时刻的特征帧,前一时刻的特征帧与后一时刻的特征帧),将所有生成的LFC序列特征送入BDConvLSTM(双向可变形的卷积LSTM网络),生成全局保持一致的
序列帧信息。

(4.3)高分辨率重建
这一部分可以重新看这个图,我们获得了
(4.4)模型细节与补充
作者对TMNet网络的结构给出了详细的设计方案,包括残差模块和上采样模块的结构。
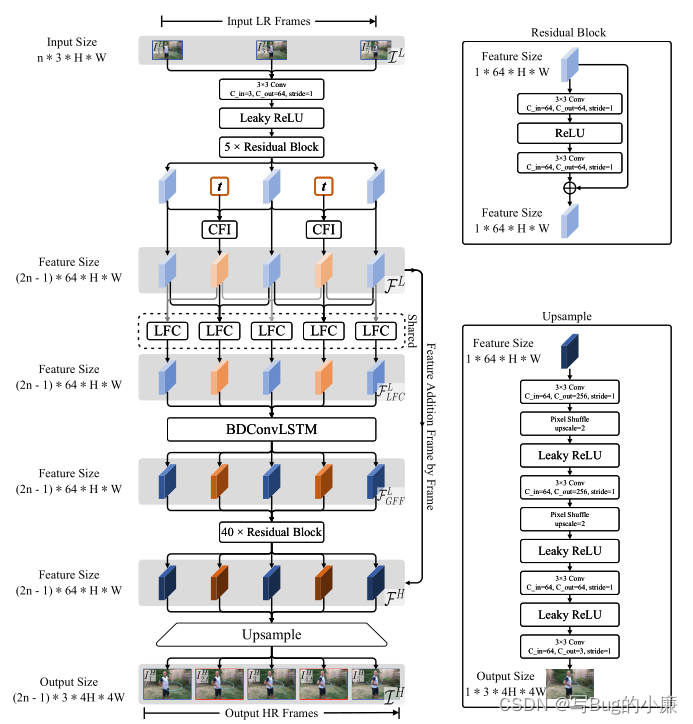
这是TMB和LFC模块的内部实现细节:

(5)实验
训练数据集:Vimeo-90K
TMB模块单独训练:Adobe240fps
测试数据集:Vid4、Vimeo-90K
下采样方法:Bicubic (BI)
迭代优化器:Adam optimizer
学习率:4*10^-4,余弦退火的学习率衰减,每150000次,衰变为1*10^-7
输入LR尺寸:32*32,并进行90\180\270翻转。
损失函数:Charbonnier loss
(5.1)相比较其他模型的实验结果:
与当前的STVSR方法进行比较,对比两阶段超分和一阶段超分的模型进行对比PNSR和SSIM对比,两阶段超分就是一个用来执行VFI、一个用来执行VSR。一阶段就是全部都有。对比结果如下,红色最好,蓝色次优。


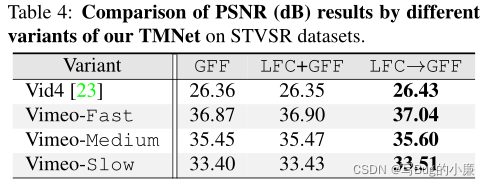
(5.2)消融实验实验结果:
作者将TMB模块应用在PCD框架上的不同阶层,以及在本文的TMNet网络的PSNR。

TMB模块的设计是为了将超参数t转换成与PCD模块适应的矢量结构,一种设计是线性卷积,另一种就是非线性卷积。如下PSNR的结果。

作者将LFC与GFF做不同的结合,一种不用LFC,一种将LFC和GFF的特征结果做融合,本文方法将LFC的结果作为GFF的输入,PSNR结果最好。
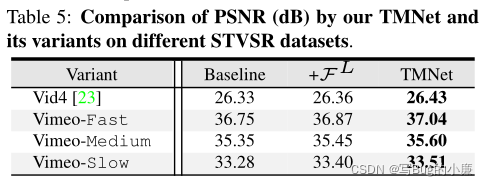
作者将本文的总体结构中去除在最后的![]() 中加入
中加入![]() 得到一个baseline,然后将
得到一个baseline,然后将![]() 加在TMNet过程中得到另一个变体,与正规TMNet比较,在不同数据集上还是TMNet的PSNR更高。
加在TMNet过程中得到另一个变体,与正规TMNet比较,在不同数据集上还是TMNet的PSNR更高。
总结:
本文的主要目的就是在STVSR模型上,使得可以进行各种帧率的调整,并且根据短期线索融合长期线索,使得本文模型恢复出来的图像更具备细节特征。不过本文没有对参数量做出实验结果,所以后续的参数量需要细究,以便研究在实时性上的可操作性。
jiji

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)