

DCAI:Data-Centric AI 以数据为中心的AI
想象当中的数据集: usually fairly clean & well-curated (e.g. dog/cat images) 猫就是猫,狗就是狗实际现实生活中的数据集:非常混乱~ https://labelerrors.com/ 比如这个网站里提供了一些人们常用的开源数据集中的错误标签部分两个大佬的meme,乐呵一下Seasoned data scientist: It's more w
1. 什么是DCAI?
1.1. 当下的研究背景
想象当中的数据集:通常是干净且精选的(例如猫或狗的图片)。 猫就是猫,狗就是狗

实际现实生活中的数据集:非常混乱~ https://labelerrors.com/ 比如这个网站里提供了一些人们常用的开源数据集中的错误标签部分

经验丰富的数据科学家:投资探索和修复数据比修补模型更值得。(即避免“垃圾进,垃圾出”)
因此我们要意识到我们所用到的数据并不是完美无缺的,相反,里面有非常多的陷阱。
而业界也花了很多时间和精力在处理数据,而非模型上。

1.2. 现在就来简易区分:以模型为中心的AI和以数据为中心的AI

以模型为中心的AI:重心在于调整模型;调参侠,掉包侠,fancy modeler
以数据为中心的AI:重心在于调整feed的数据本身,适配你所选的模型
当然两者最终目标都是优化模型训练结果。
其中,以数据为中心的AI需要自动化完成对数据质量的提升,例如
- Coreset selection 自动挑出来数据集中真正能够boosting performance的部分,这主要是在降能增效
- Dataset Augmentation 避免overfit/underfit的常用方法
常用的technique:
- Outlier Detection and Removal (handling abnormal examples in dataset) 异常值检测
- Error Detection and Correction (handling incorrect values/labels in dataset) 错误识别
- Data Augmentation (adding examples to data to encode prior knowledge) 数据增强
- Feature Engineering and Selection (manipulating how data are represented) 特征工程及筛选
- Establishing Consensus Labels (determining true label from crowdsourced annotations) 一致标签
- Active Learning (selecting the most informative data to label next) 主动学习
- Curriculum Learning (ordering the examples in dataset from easiest to hardest) 课程学习
总的来说就是提升喂进模型的数据质量,进一步提升模型表现。
好处是,不仅纠正了错误,而且还事半功倍!

2. 从label error开始探寻DCAI
DCAI一开始主攻的点就在label error上。诚如前所说,实际现实生活中的数据集非常混乱,label部分也是混乱的。
2.1. label error有哪些?

产生这些错误的标签的原因也是多种多样:比如你摁错了(大众点评上给餐馆打星);不小心标错了;测量度搞错了(单位!!);你不认识真实的label所以标错了;用了其他的ML模型的错误输出(比如你做生成模型时);硬件层级的,数据传输或者保存时出的错……
2.2. label error的识别
置信学习(CL)
核心思想还是根据历史训练结果(confidence),辅助判断该label是否有问题。具体我就不展示啦,逻辑还是比较清晰的

通过CL估计发现,这些著名的数据集中居然有这么多label error!
2.3. label error对benchmark的影响

首先我们来看CIFAR-10上的例子。横坐标是在未修改的validation(correctable,意味着能被修正的错误标签)上的top1 acc,纵坐标是在修正了label的validation上的acc。可以看出,随着层数的加深,参数量的进一步扩大,Acc能够占优,但修正label之后反而变差了。因为他overfit了这些noise。当然横坐标之所以低于纵坐标也是因为这里用来测试的validation dataset本身是噪音,本不该学到其中的信息。

然后我们在ImageNet上观察。随着test data(或者validation)中correctable noise(错误标签)占比增加,ResNet50和ResNet18的acc均有下降。

但是神奇的是,当我们在修正了label error的test data上测试时,ResNet18的acc显示出非常强的robustness,超越了ResNet50.
这在一定程度上说明了label error对benchmark的表现有很大影响,因此在此之前的paper 所依据的benchmark很有可能并不准确。
3. DCAI:对数据集的构建和维护应该注意的地方
这个章节主要有三个小问题:选择偏差,数据集容量估计以及一致标签。
3.1. Selection Bias 选择偏差
我们的训练数据和实际的应用场景有很大差异——这也叫做分布迁移(distribution shift)。这种偏差在建模的时候很难发觉。

举例:
- Time/location bias 过去现在和未来,不同国家地理位置(比如对金融时序数据,过去和现在,未来的市场环境在随时变换,不同的市场特征也显著不同)
- Demographics bias (少数群体的underrepresent)
- Response bias (主要是对调查问卷中答案设置本身自带bias,)
- Availability bias – using data that happens to be convenient rather than most representative (可以用幸存者偏差来概括)
- Long tail bias – in applications with many different possible rare scenarios, collection mechanisms may prevent some from appearing in the dataset (e.g. autonomous vehicle gets bumped into wrong side of road).(极端情况,比如自动驾驶驶入了错误行道,训练集很少,但实际一定会碰到)
比较好的解决办法: ***让validation数据集更贴近实际应用场景***
- If data are collected over time in a changing environment, one might hold out the most recent data as the validation set. TS数据用最近的数据来做validation
- If data are collected from multiple locations and new locations will be encountered during deployment, one might reserve all data from some locations for validation. 把所有location的数据,inclusive地放进validation
- If data contain important but rare events, one might over-sample these when randomly selecting validation data. oversample偶发事件
这个topic会在后面有更详尽的说明。
3.2. 我们到底需要多少数据?
根据实证得到的error和训练样本集n大概符合以下关系:

你只需要不断增大n,通过在相同测试集上的error便可以拟合得到ab参数值,然后根据你想要的精度,计算出合适大小的训练集。
这篇文章来自于ICLR2020:Rosenfeld, J., Rosenfeld, A., and Belinkov, Y. A constructive prediction of the generalization error across scales. International Conference on Learning Representations, 2020.
3.3. Curating a dataset labeled by multiple annotators 多个标注者共同标注数据集
这里的问题主要来自 crowdsourcing(外包)。外包可能产生两个问题:
- 外包标注不一定准确
- 外包人员有可能互相抄抄(图省事儿就拿其他人的标注交作业)
一般来说应对这种问题的解决办法是掺杂一些quality control,即已知真实label的数据进去,这样就能发现一些端倪。但是事实上,很多时候我们没有这样的样本。
于是我们想解决这样的问题,我们需要三类数据:
- 一致标注(single best label)
- 标注的质量(confidence)
- 标注者的质量
在这里我们有以下方法获得以上的数据。

- Majority Vote + Inter-Annotator Agreement
这很简单,就是取标注者们的 Majority Vote,并把它当作真是label,进一步可以得到标注者的质量(用正确率衡量)。这样问题在于:可能出现tie;并且好坏标注者对标注的贡献是等同的。
- Majority Vote
如果有tie的话,我们可以先根据 Majority Vote 训练一个分类器,然后用它生成的label辅助判断(因为它用到了其他图片的信息)。这对只有一个label的样本也很有用。当然这个分类器也是有噪音的,后期可以根据chapter2提到的CL(confidence learning)进行修正。
- CROWDLAB
把标注者们的标注(前部分)和分类器(后部分)的标注集合起来。其中可以看见有不同的权重,这就是可以调整的地方,你可以下调一个bad annotator的权重,也可以上调分类器的权重。值得注意的是,这其实是一个迭代的过程,回到a步骤,计算标注者的质量,权重能依据标注者质量进行优化,最后能converge到一个比较理想的状态。

CROWDLAB来自 NeurIPS 2022,CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators 具体推证及实施细节可以参考原论文。
4. Data-Centric的模型评估方式
这一章节主要解决这一问题: Investigate shortcomings of the model and the dataset.即怎么检查模型和数据的短板。
主要分为evaluation和inspection.
4.1. 模型评估(a prerequisite for improving)

首先我们不能依据一个metric就判断我们的模型好坏(虽然大家都这么做哈),就好像直接用所有样本的loss平均数。
最好是能够细化到每一类的accuracy,或者直接输出混淆矩阵。 总之要认识到对模型评估方式非常重要。
比如你的模型效果超好,但只是在某一prevailing的子类上表现超好~

因此我们要关注一下在评估(evaluation)时的陷阱,主要针对validation dataset来说:
- Failing to use truly held-out data (data leakage)
- Reporting only average loss can under-represent severe failure cases for rare examples/subpopulations (misspecified metric)
- Validation data not representative of deployment setting(selection bias)
- Some labels incorrect(annotation error)
这些包含在前面章节提到的数据泄露,选择偏差和标注错误等,那么解决措施在前面也有提到。
4.2. 关注并处理切片数据的欠拟合情况
中心思想就是:Model predictions should not depend on which slice a datapoint belongs to.
data slice = a subset of the dataset that shares a common characteristic
如种族、性别、社会经济学、年龄或位置。切片也称为:群组、子群体或数据的子组。通常我们不希望模型预测取决于数据点属于哪个切片。
我们能不能从特征中删掉这些切片?显然不能,因为这些切片特征和其他变量也息息相关(比如种族和pay,这两者事实上有很大关联。学线性回归的时候老师强调说相关效应存在时不应该去除主效应)
有以下几种方法减弱这种效应:
- Try a more flexible ML model that has higher fitting capacity.比如用复杂度更高的模型
- Over-sample or up-weight the examples from a minority subgroup that is currently receiving poor predictions
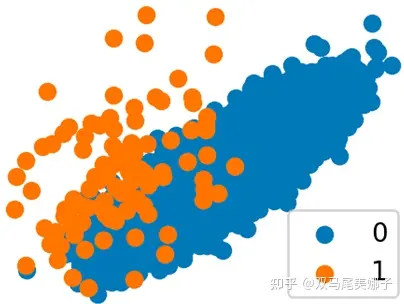
橙色和蓝色子组具有重叠的特征值。如果这两个子组的标签往往不同,那么任何模型都必须在对一个子组和另一个子组产生更差的预测之间进行权衡。如果您为橙色数据点分配更高的权重,那么生成的模型应该以对蓝色子组的潜在更差预测为代价为它们产生更好的预测。
还有一些其他的,不在这里列举。
4.3. 发现部分表现欠佳的样本
这里表现欠佳的不一定是某一个切片,就是一些零散的数据样本点。
首先找到它们:
- Sort examples in the validation data by their loss value, and look at the examples with high loss for which your model is making the worst predictions (Error Analysis) 挑loss最高的样本出来看看
- Apply clustering to these examples with high loss to uncover clusters that share common themes amongst these examples 依据loss把样本分类看看有无明显聚类特征
它们产生的原因也很多。在前面讲我们应该注意的对数据集处理的情况也有重合。
- Given label is incorrect 错误标签
- Example does not belong to any of the K classes 样本根本不在目标分类里
- Outlier 异常值 (遇到这种一般用data augmentation,或者把它调整到和其他样本相似的程度(就是让它看上去不那么out),更具体的在第五章有介绍。)
- 你用的模型就不适用。这时候转去model-centric ai吧。
4.4. 量化单个样本对模型效果的影响
- Leave-one-out (LOO)

- Data Shapely
从包含这个点的任意子集中计算LOO,然后平均。计算量太大,可以用蒙特卡罗模拟。
- 对于特殊的模型族,我们可以有效地计算出准确的影响函数。
在我们使用线性回归模型和均方误差损失,训练模型的拟合参数是数据集的封闭形式函数。因此对于线性回归,LOO也被叫做库克距离(学过线性回归的同学都很熟悉)。在分类中,对embedding进行KNN聚类,可以以O(Nlog(N))的时间复杂度下完成LOO的计算。
以上的这些方法所指向的数据都叫做influencial data sample,他们并不一定是异常值,只是对模型有较大影响的独立样本,其实翻译过来是高杠杆点。学过线性回归的同学也知道这两者的定义和检验方式不同。
5. 类别不均衡,异常值和分布迁移
5.1. 类别不均衡
在以下阶段都需要额外关注。
- 在划分训练测试集的时候:If you're splitting a dataset into train/test splits, make sure to use stratified data splitting to ensure that the train distribution matches the test distribution (otherwise, you’re creating a distribution shift) problem.
- 在评估模型的时候:There is no one-size-fits-all solution for choosing an evaluation metric: the choice should depend on the problem. For example, an evaluation metric for credit card fraud detection might be a weighted average of the precision and recall scores (the F-beta score), with the weights determined by weighing the relative costs of failing to block a fraudulent transaction and incorrectly blocking a genuine transaction
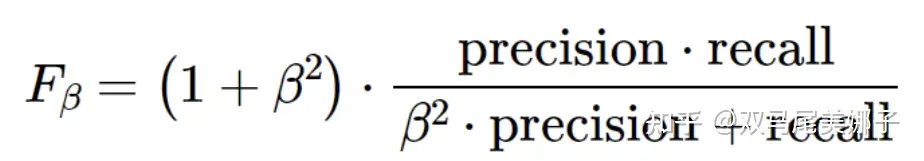
- 在实际训练的时候,可以采用下面一些方式。
样本权重:实践中通常效果不佳。对于使用 mini batch 训练的分类器,使用样本权重会导致不同 mini batch 之间学习率发生变化,这会使学习变得不稳定。
过采样:简单地复制少数类中的数据点以使数据集更加平衡。通常比样本权重表现更好。该解决方案通常不稳定,并且可能导致过度拟合。
欠采样:在多数类中删除数据点。这种方法在实践中的效果出奇地好。在某些情况下,当数据集高度不平衡时,它可能会导致丢弃大量数据,从而导致性能不佳。
SMOTE:可以使用数据集扩充通过组合或扰乱少数样本来创建少数类的新样本,而不是通过复制数据点进行过度采样。SMOTE 算法中特征空间的插值是有意义的,但对某些其他数据类型没有意义:将一张狗的图片与另一张狗的图片的像素值平均不太可能产生一只狗的照片。根据应用程序的不同,其他数据增强方法可能效果更好。
平衡的小批量训练( Balanced Mini-Batch Training ):对于使用 mini batch 训练的模型(如神经网络),让每个mini batch更高概率地抽取少数类的数据点。
这些技术可以结合使用。例如,SMOTE 作者指出,SMOTE 和欠采样的组合比普通欠采样表现更好。
5.2. 异常值
异常值:异常值是与其他数据点明显不同的数据点。原因包括测量错误(例如,损坏的空气质量传感器)、错误的数据收集(例如,表格数据集中缺少字段)、恶意输入(例如,对抗性示例)和罕见事件(统计异常值,例如,白化动物在图像分类数据集中)。
异常值检测又被细分为以下两类:
Outlier detection:在无标签的数据集中监测异常点——清洗数据集(预处理中)
Anomaly detection. 在无标签的数据集基础上判断新数据样本是否和原训练集为相同分布——在查看inference dataset和training dataset是否一致的时候。
检测异常值的方法很多
- 孤立森林
该技术与决策树相关。直观地说,该方法创建一个“随机决策树”,并根据隔离数据点所需的节点数量对数据点进行评分。该算法通过随机选择一个特征和一个分割值来递归地划分数据集(的子集),直到该子集只有一个实例。这个想法是,离群数据点需要更少的分割才能变得孤立。
- KNN距离
分布内的数据可能更接近其邻居。您可以使用到数据点的 k 个最近邻居的平均距离(选择适当的距离度量,例如余弦距离)作为分数。对于图像等高维数据,您可以使用经过训练的模型的嵌入,并在嵌入空间中执行 KNN。
- 基于重建的方法
自动编码器是生成模型,经过训练将高维数据压缩为低维表示,然后重建原始数据。如果自动编码器学习数据分布,那么它应该能够将分布内数据点编码然后解码回接近原始输入数据的数据点。然而,对于分布外的数据,重建会更差,因此可以使用重建损失作为检测异常值的分数。
许多离群值检测涉及计算每个数据点的分数,然后根据阈值判断是不是异常值。这里可以用ROC,或者AUC.
5.3. 分布迁移
在这里的分布迁移专指的是在train 和 test之间的差异。在这里又可以分为三类:
- Covariate shift / data shift 协变量迁移/数据自身迁移
p(y|x)没变,p(x)变了. 这个最好理解了,就是训练集和测试集的自变量数据差别太大。
- 概念迁移Concept shift
p(x)没变,p(y|x)变了;即输入分布未改变,但输入和输出之间的关系变了。比如粉色还是粉色,蓝色还是蓝色,但是随着时间变化,喜欢这些颜色的人群却不一样了(好像中世纪男性更崇尚粉色,因为是血液稀释的颜色,女性更偏爱蓝色,是圣母玛利亚的颜色??我自己补充的例子哈哈)。
- Prior probability shift / label shift 先验概率迁移/标签迁移
p(x|y)没变,p(y)变了,这里需要注意有一条潜在的因果链:y导致x。例如训练分类器预测给定症状的诊断, y是疾病,x是症状,因为疾病的相对流行率p(y)会随着时间而变化。但是疾病对症状的显式体现的概率没有发生变化。
5.4. 检测和解决分布迁移
检测分布迁移:
- 监控模型的性能。监控准确度、精确度、统计量度或其他评估指标。如果这些随着时间的推移发生变化,则可能是由于分布迁移。
- 监控数据。可以通过比较训练数据和部署中看到的数据的统计属性来检测分布迁移中的协变量迁移。
怎么解决呢?
在高层次上,可以通过修复数据和重新训练模型来解决分布迁移问题。在某些情况下,最好的解决方案是收集更好的训练集。
如果训练时未标记的test data可用,那么解决协变量迁移的一种方法是,将单个样本权重分配给train data以权衡它们的特征分布,使得加权分布类似于test data的特征分布。即使test data的标签未知,标签的迁移也可以通过对具有相同类别标签的所有train data使用共享样本权重来类似地解决,以使train data中的加权特征分布类似于test data中的特征分布。但是这无法解决概念迁移,因为无法从未标记的test data中对其进行量化。

参考文献

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)