
知了堂|Hibernate JPA 快速入门
1、Hibernate JPA简介1.1、认识 hibernateHibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将 POJO与数据库表建立映射关系,是一个全自动的 orm 框架,hibernate 可以自动生成 SQL 语句,自动执行,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。1.2、认识 JPAJPA的全称:Java Pe
1、Hibernate JPA简介
1.1、认识 hibernate
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将 POJO与数据库表建立映射关系,是一个全自动的 orm 框架,hibernate 可以自动生成 SQL 语句,自动执行,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。
1.2、认识 JPA
JPA的全称:Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。
JPA通过JDK 5.0注解描述 对象-关系表 的映射关系,并将运行期的实体对象持久化到数据库中。
劣势:
由于对持久层封装过于完整,导致开发人员无法对SQL进行优化,无法灵活使用JDBC的原生SQL,Hibernate封装了JDBC,所以没有JDBC直接访问数据库效率高。要使用数据库的特定优化机制的时候,不适合用Hibernate
框架中使用ORM原则,导致配置过于复杂,一旦遇到大型项目,比如300张表以上,配置文件和内容是非常庞大的,另外,DTO满天飞,性能和维护问题随之而来
如果项目中各个表中关系复杂,表之间的关系很多,在很多地方把lazy都设置false,会导致数据查询和加载很慢,尤其是级联查询的时候。
优势:
标准化 JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
容器级特性的支持 JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
简单方便 JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity 进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成
查询能力 JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
高级特性 JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
1.3、JPA 与 hibernate 关系
JPA规范本质上就是一种ORM规范,注意不是ORM框架,因为JPA并未提供ORM实现,它只是定义了一些规范,提供了一些编程的API接口,但具体实现则由服务厂商来提供实现
JPA示意图:

JPA 和 Hibernate 的关系就像 JDBC 和 JDBC 驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。
JPA 能取代 Hibernate 吗?正如同问 JDBC规范可以驱动底层数据库吗?答案是否定的,如果使用JPA规范进行数据库操作,底层需要 hibernate 作为其实现类完成数据持久化工作。
2、搭建开发环境(IDEA)
咱们使用Maven方式创建即可
2.1、使用 IDEA 创建 maven 工程(可能会缺少src/test/resources目录,手动创建和设置即可)

2.2、导入pom坐标

2.3、建立 /resources/META-INF/persistence.xml 配置文件
路径:配置到类路径(resources)下的 META-INF 的文件夹下,文件名:persistence.xml
备注:由于主要在 src/test/ 下做测试,所以建议在 src/test/resources/下也建立 META-INF/persistence.xml
IDEA有persistence模板:setting=》file and code Template=》JPA==》Deployment descriptors=》persistenceXX.xml
persistence.xml 内容:
/**
- 客户的实体类
-
配置映射关系 - 1.实体类和表的映射关系
-
@Entity:声明实体类 -
@Table:配置实体类和表的映射关系 -
name : 配置数据库表的名称 - 2.实体类中属性和表中字段的映射关系
/
@Data
@Entity
@Table(name = “tb_customer”)
public class Customer {
/*- @Id:声明主键的配置
- @GeneratedValue:配置主键的生成策略
-
strategy: -
GenerationType.IDENTITY :自增,mysql -
底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增) -
GenerationType.SEQUENCE : 序列,oracle -
底层数据库必须支持序列 -
GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增 -
GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略 - @Column:配置属性和字段的映射关系
-
name:数据库表中字段的名称
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = “customer_id”)
private Long Id; //客户的主键
@Column(name = “customer_name”)
private String name;//客户名称
@Column(name=“customer_age”)
private int age;//客户年龄
@Column(name=“customer_sex”)
private boolean sex;//客户性别
@Column(name=“customer_phone”)
private String phone;//客户的联系方式
@Column(name=“customer_address”)
private String address;//客户地址
}
对应的数据库表信息:

2.5、测试保存操作的执行
/**
* 测试jpa的保存
* 案例:保存一个客户到数据库中
* Jpa的操作步骤
* 1.加载配置文件创建工厂(实体管理器工厂)对象
* 2.通过实体管理器工厂获取实体管理器
* 3.获取事务对象,开启事务
* 4.完成增删改查操作
* 5.提交事务(回滚事务)
* 6.释放资源
*/
@Test
public void testSave() {
//1.加载配置文件创建工厂(实体管理器工厂)对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory(“myJpa”);
//2.通过实体管理器工厂获取实体管理器
EntityManager em = factory.createEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//4.完成增删改查操作:保存一个客户到数据库中
Customer customer = new Customer();
customer.setName(“Sam”);
customer.setAddress(“Beijing”);
//保存操作
em.persist(customer);
//5.提交事务
tx.commit();
//6.释放资源
em.close();
factory.close();
}
2.6、查看日志
Hibernate:
create table tb_customer (
customer_id bigint not null auto_increment,
customer_address varchar(255),
customer_age integer,
customer_name varchar(255),
customer_phone varchar(255),
customer_sex bit,
primary key (customer_id)
) engine=InnoDB
Hibernate:
insert
into
tb_customer
(customer_address, customer_age, customer_name, customer_phone, customer_sex)
values
(?, ?, ?, ?, ?)
2.7、这里可以看到为我们自动生成了SQL语句,因为xml 里这里设置的是 update,所以有表的前提下,不会再生成表
简单测试:

运行结果,会自动生成HQL语句
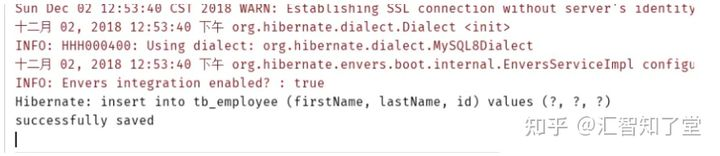
end~

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)