
zeppelin on yarn 搭建遇到的问题总结
搭建zeppelin还是非常坎坷的,从最开始git clone源码下来打包,就会等上半天,弹个包下不来之类的报错。。可以说是很扎心了,,切入正题:1、spark 2.0及以上的版本,配置yarn的时候,需要的配置:2、配置interpreter的时候,依赖的添加如spark 需要添加你的机器hadoop版本:hive则需要加上hado...
搭建zeppelin还是非常坎坷的,从最开始git clone源码下来打包,就会等上半天,弹个包下不来之类的报错。。
可以说是很扎心了,,切入正题:
1、spark 2.0及以上的版本,配置yarn的时候,需要的配置:

2、配置interpreter的时候,依赖的添加
如spark 需要添加你的机器hadoop版本:

hive则需要加上hadoop版本和hive-jdbc,hive-service版本:
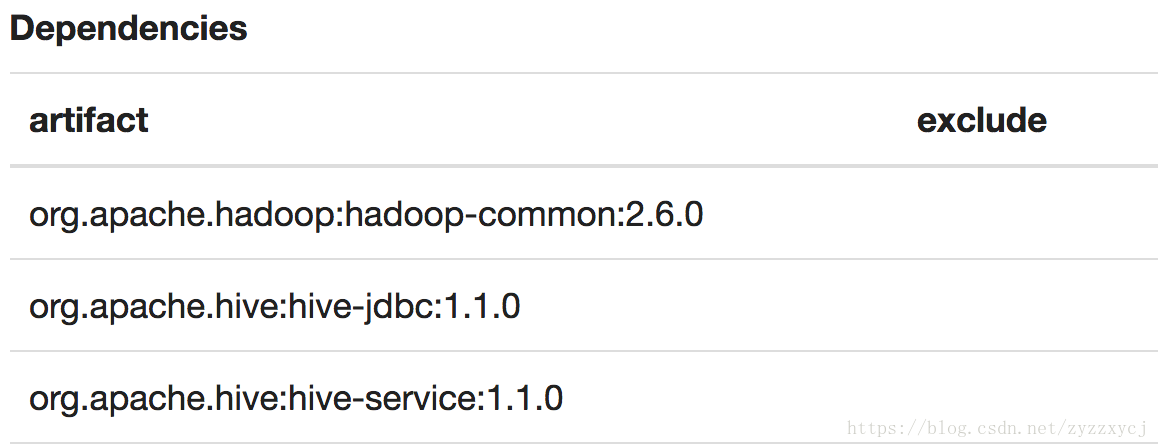
这边的依赖,可以是添加本地路径,也可以像上面这样 自动下载。
3、interpreter中的localRepo

不难发现,每个interpreter中 都有这么一个位置,去对应目录下查看,可能会找不到。
这个文件夹,只有在执行任务,使用了这个interpreter之后,才会自动创建,里面存了 需要用的各种jar,包括添加的依赖:
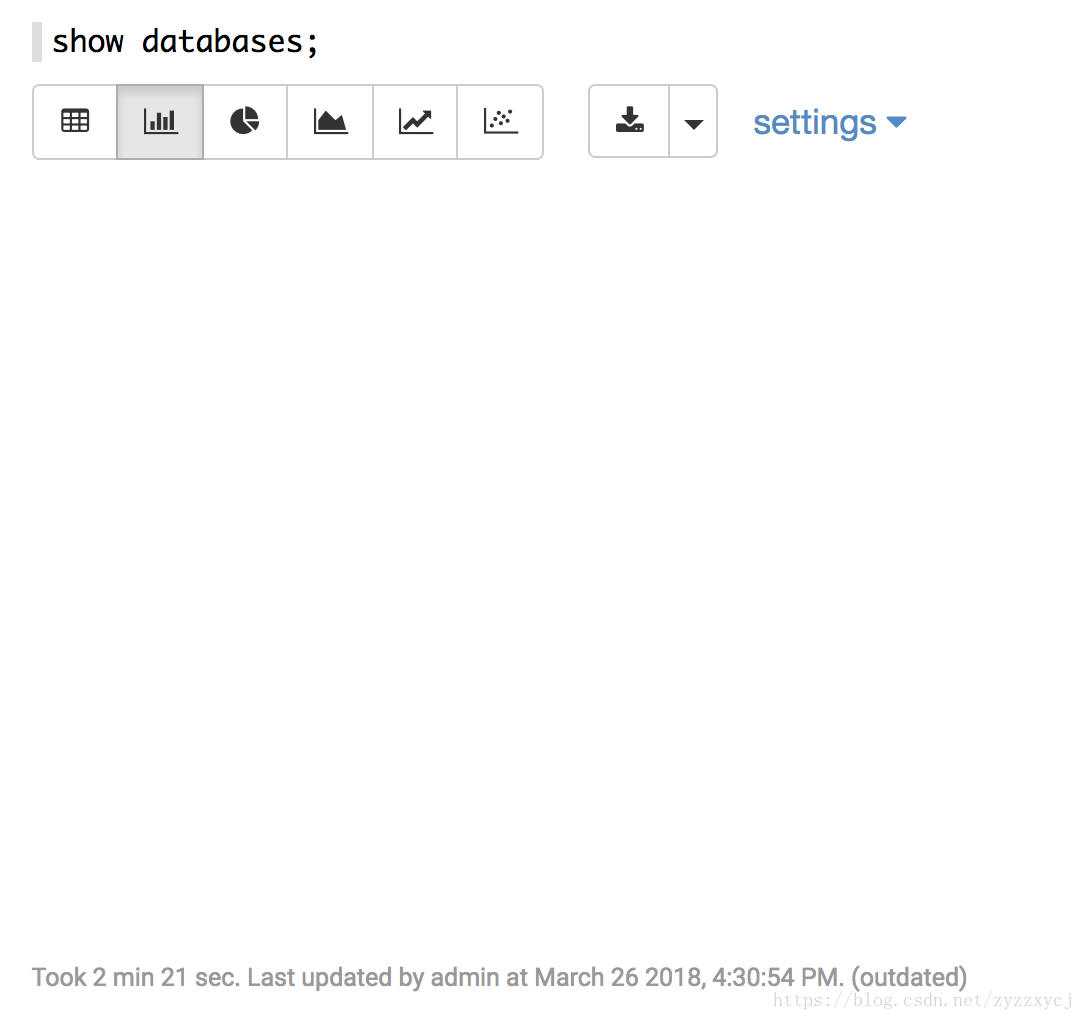
4、hive运行很慢
执行一个简单的show databases,就能用将近3分钟的时间。。
这段时间,花了好多时间研究这个问题,,
首先看了hive和zeppelin的日志,发现zeppelin的日志 提交任务->接收结果 并没有什么异常,
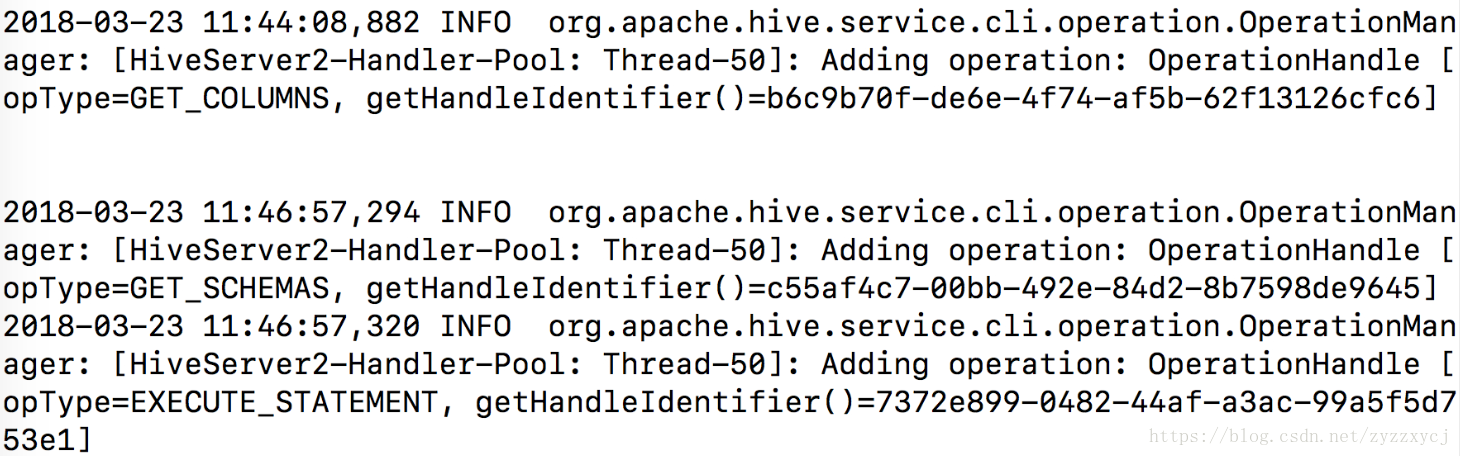
hive日志中,add operation get_Columns和get_Schemas之间占用了相当多的时间。。主要就是这边的问题了:
然后去看了hive的add operation的源码,,自然是看不出有什么不对劲
然后去看zeppelin 调用jdbc interpreter时候的源码,简单的分析一下:
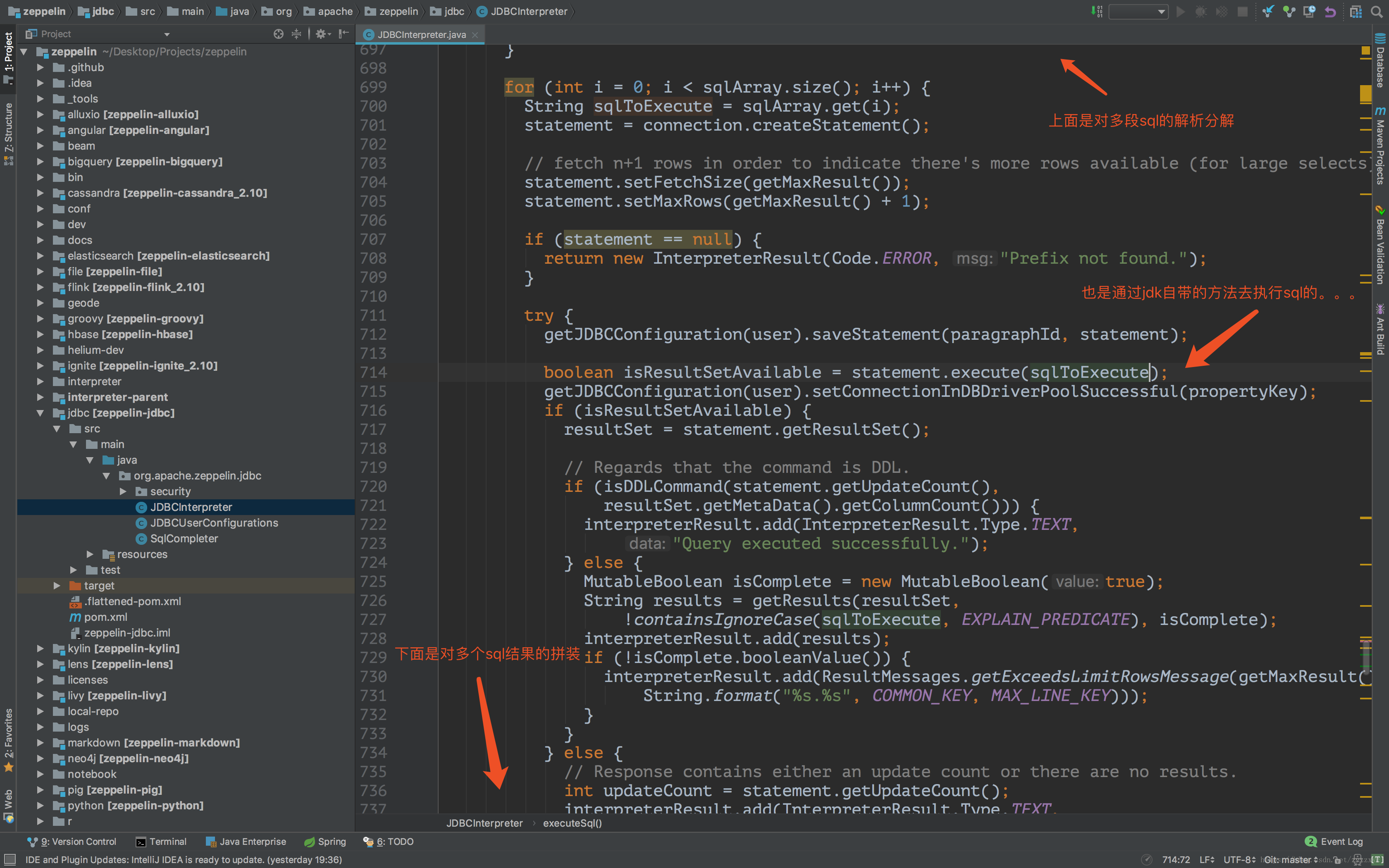
再去搭了新环境 hadoop2.7.3 hive2.1.1 jdk1.8 mysql5.6.39
各种调通之后,在zeppelin上新建了一个interpreter hive2,指向了自己搭的新环境
成功解决。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)