
使用Stable Diffusion、ComfyUI和SDXL 从任何文本提示中生成逼真的艺术图像
在本课程中,您将学习如何使用Stable Diffusion、ComfyUI和SDXL,这三个强大的开源工具可以从任何文本提示中生成逼真的艺术图像。您将发现潜在扩散模型背后的原理和技术,这是一种新的生成模型,可以在几秒钟内生成高质量的图像。您还将探索SDXL,这是下一代稳定扩散模型,可以生成比以往任何时候都更详细、分辨率更高、更智能的图像。本课程适合任何对AI图像合成感兴趣的人,无论你是具有稳定扩

你想学习如何使用最新的人工智能技术从文本中创建令人惊叹的图像吗?如果是这样,这个课程就是为你准备的!
在本课程中,您将学习如何使用Stable Diffusion、ComfyUI和SDXL,这三个强大的开源工具可以从任何文本提示中生成逼真的艺术图像。您将发现潜在扩散模型背后的原理和技术,这是一种新的生成模型,可以在几秒钟内生成高质量的图像。您还将学习如何使用ComfyUI,这是一个图形用户界面,让您无需编码即可设计和执行复杂稳定的扩散工作流程。您还将探索SDXL,这是下一代稳定扩散模型,可以生成比以往任何时候都更详细、分辨率更高、更智能的图像。Advanced Stable Diffusion with ComfyUI and SDXL
你会学到什么
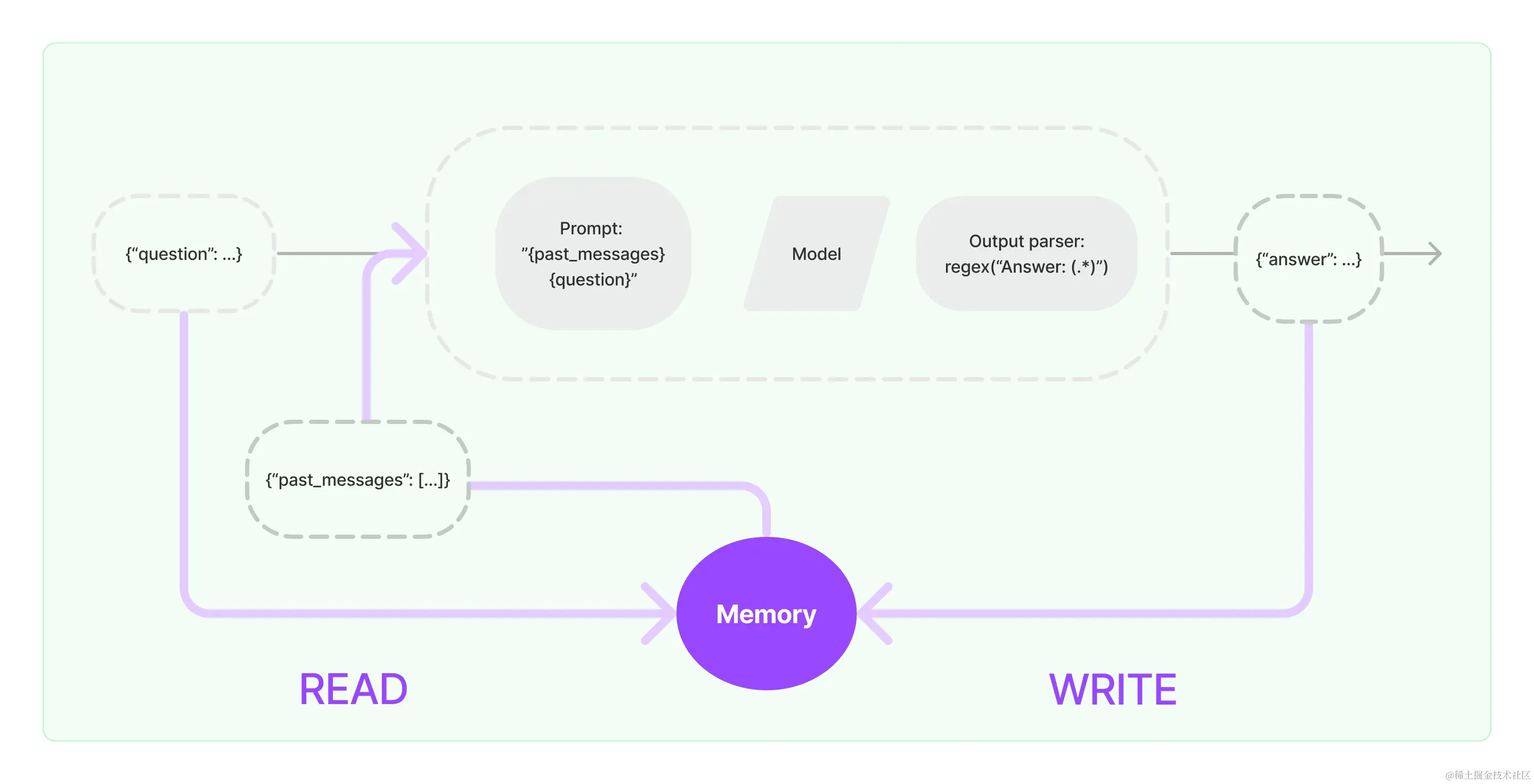
全面了解ComfyUI、SDXL和稳定扩散1.5
了解Control-lora、ControlNets、lora、嵌入和T2I适配器在ComfyUI中的使用
了解如何在稳定扩散工作流程中使用生成式反向串行网络和CLIP神经网络
充分了解如何创建和评估复杂的ComfyUI工作流程
课程时长:4小时23分钟 1280X720 mp4 语言:英语+中英文字幕(云桥网络 谷歌机译)
云桥网络 平台huo取课程

本课程结束时,您将能够:
使用Stable Diffusion 1.5和Stable Diffusion XL–SDXL生成您可以想象的任何图像
使用ComfyUI微调和定制您的图像生成模型
使用SDXL创建逼真的艺术图像
将你的技能运用到各个领域,比如艺术、设计、娱乐、教育等等
本课程适合任何对AI图像合成感兴趣的人,无论你是具有稳定扩散先验知识的人,还是ComfyUI的初学者,或者是希望了解和理解更多内容的ComfyUI中级学习者。你不需要任何编码或机器学习的经验或知识。你所需要的只是一台带GPU和互联网连接的电脑。
该课程将适合拥有至少8 GB VRAM的英伟达RTX GPU的学生。使用较少VRAM的设置可能无法完成讲座中概述的所有步骤
不要错过这个释放你创造力的机会,向这个领域的佼佼者学习。今天就报名参加这个课程,开始制作你自己的令人惊叹的ComfyAI图像吧!
本课程面向谁:
本课程非常适合希望了解ComfyUI和其他版本的稳定扩散(如Automatic1111和Invoke)之间差异的学员
想要了解SDXL最新功能的学生
想要了解可用于ComfyUI、SDXL和Stable Diffusion 1.5的最新型号的学生
有ComfyUI工作经验的创意人员,希望扩大他们的技能范围


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)