
1 安装和简单使用Transformers
我是NLP或者Transformers纯小白,写文档既是作为记录,也分享给大家共同讨论。本教程所有需下载的文件都会整合到百度网盘,就算你不会git和魔法上网也可以跟着做:
我就是B站up 哈士嗷的个人空间-哈士嗷个人主页-哔哩哔哩视频
0 序言
我是NLP或者Transformers纯小白,写文档既是作为记录,也分享给大家共同讨论。本教程所有需下载的文件都会整合到百度网盘,就算你不会git和魔法上网也可以跟着做:
链接:https://pan.baidu.com/s/1LfApcmkP_p6WEIUkUKyJrw?pwd=g155
提取码:g155
1 检查你的电脑
演示视频电脑软硬件信息:
CPU i7-13700HX 8P8E
GPU RTX4070 laptop 8GB
RAM 32GB
OS Windows11 23H2 家庭版
IDE Anaconda3-2023.03
建议你的电脑有NVIDIA的显卡(至少GTX 900series起),也许CPU或者AMD显卡也能跑,请自行尝试,我也不懂。
2 安装开发环境
2.1 安装anaconda
你可以去官网 Free Download | Anaconda 下载最新版,也可以用我提供的安装包。这个软件下载无需魔法上网,下载后,打开安装包,一直下一步就可以了。
2.2 安装CUDA
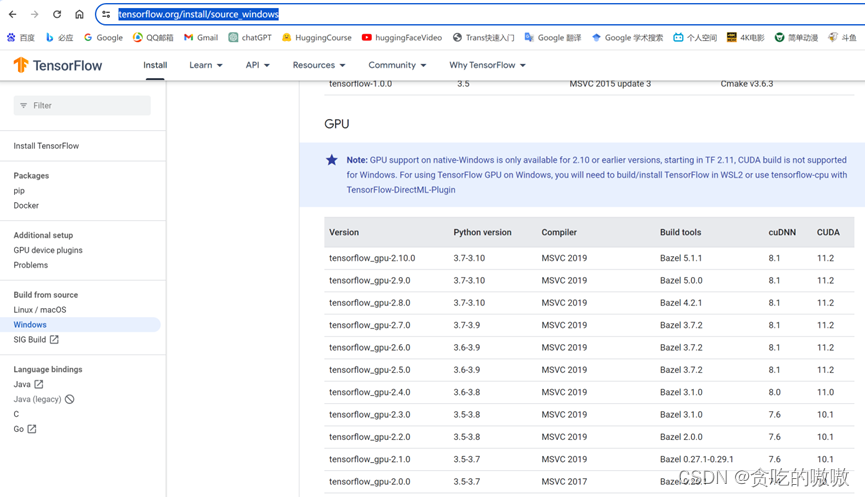
CUDA是NVIDIA公司推出的可利用GPU进行并行计算加速的开发工具。我个人比较习惯使用tensorflow,需要参考tensorflow官网的说明下载安装针对性的CUDA版本。官网链接:https://www.tensorflow.org/install/source_windows
Windows下最多只能用到tensorflow_gpu-2.10.0,对应的CUDA版本是11.2,cuDNN是8.1,可以去NVIDIA开发者官网下载,或通过我提供的百度网盘链接。
下载后,打开CUDA安装包,建议选择默认路径,如果要自定义路径,记住自己的安装位置。
较新版本的CUDA安装后一般无需配置环境变量。
2.3 CUDNN
用于卷积学习网络加速的工具,将我提供的cudnn压缩包里面的文件,复制到CUDA安装路径下。
2.4 为Transformers配置虚拟python开发环境
按照下图,新建一个虚拟python开发环境,我起名为Transformers,python语言版本为3.8。

耐心等待其创建完毕后,点击我们刚创建的虚拟开发环境,点击虚拟开发环境右边的箭头,点击Open Terminal

依次输入以下命令,实测中国电信宽带不需要任何魔法上网工具。
pip install tensorflow_gpu==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pytorch安装需要去PyTorch 官网,根据你的系统、cuda版本找到合适的安装pytorch命令
我的电脑 是cuda11.8 安装命令为
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=11.8 -c pytorch -c nvidia -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
以上命令的意义是依次在我们选择的虚拟环境里面安装tensorflow-gpu、和transformers库。
后续开发必定用到python,如果没有一个便利的IDE(集成开发环境),单纯用命令行或txt写代码对于稍微复杂一点的项目来说无异于作茧自缚。因此我们还需要为虚拟开发环境配置一款IDE,可以选择spyder(像maltab,新手友好)或Pycharm(专业的python开发IDE)。这里用spyder为例进行说明:
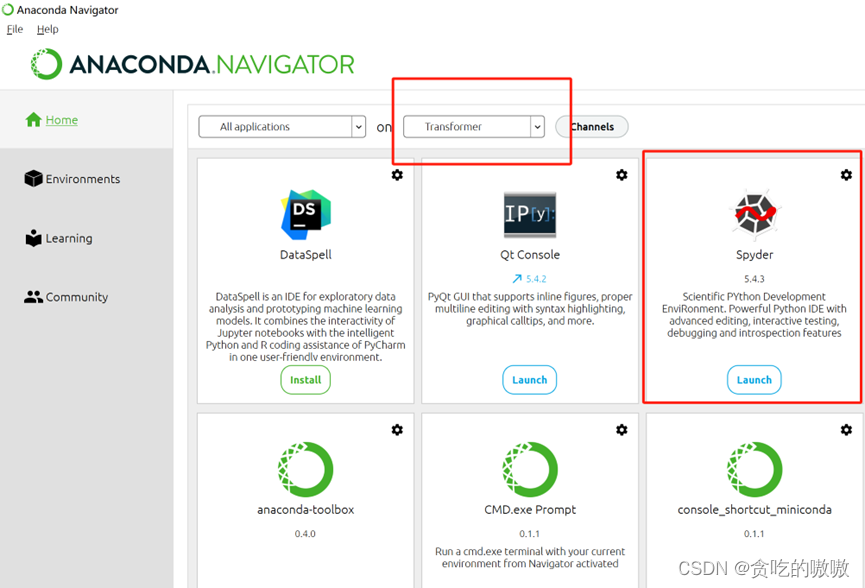
在anaconda navigator,点击左侧的Home,然后检查红框内是否是我们刚配置好的虚拟环境,如果不是,则需要去Environments切换。然后点击spyder下面的install,稍等几分钟即可完成安装。
安装好后,你的开始菜单应该出现这个图标

这表示此Spyder是Transformer虚拟开发环境的IDE,你可以将其固定到开始菜单,或右键找到它的位置然后发送到桌面快捷方式。
启动Spyder,简单输入以下代码并运行,以测试tensorflow-gpu是否安装正确:
import tensorflow as tf
tf.test.is_gpu_available()

输入这两行代码后,点击上方的绿色按钮,即可运行代码。右下角是运行结果,表示撰写文档的电脑的GPU是RTX4080super。
我的百度网盘链接还提供了varify_torch.py,用于检查pytorch是否安装正确。这里不再赘述。
2.5 下载、配置NLP模型
我们一开始肯定没有办法从零训练一个模型,因此我们需要站在巨人的肩膀,先学会使用其他人训练好的语言模型。
这个网址需要魔法上网才能访问,包含huggingface提供的海量模型。此官网也有大量可供训练的数据、项目等。
如果你有魔法上网和使用git的能力,那么自行在此网站下载你需要的模型、数据即可。如果没有,可暂时使用我提供的百度链接的hugging-face-models路径下的模型。
3 简单使用训练好的模型进行语言分析
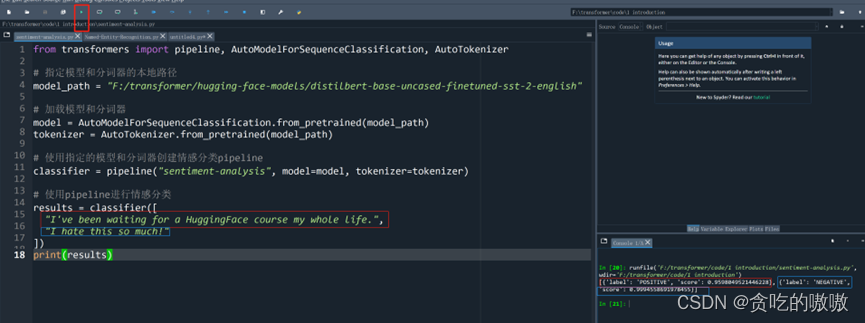
打开Spyder(虚拟开发环境名),然后输入以下代码:
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
# 指定模型和分词器的本地路径
model_path = "F:/transformer/hugging-face-models/distilbert-base-uncased-finetuned-sst-2-english"
# 加载模型和分词器
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 使用指定的模型和分词器创建情感分类pipeline
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 使用pipeline进行情感分类
results = classifier([
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!"
])
print(results)
需要特别注意,加红标粗的变量是你的本地模型路径,需要修改为你保存的路径,需要使用’/’或者‘\\’,而不可以使用’\’作为路径分隔符(windows默认从资源管理器复制的路径分隔符可能需要替换),如果你有随时访问https://huggingface.co/models 的能力,那么可以参考第4节的课程,直接运行里面的代码即可。
写好代码后运行,可以看到我们输入两句话,意思分别是我等huggingface等了一辈子;我很讨厌这个东西。我们的代码分别分析这两句话的意思,并判断出其感情是积极POSITIVE还是消极NEGATIVE。很显然,第一个是积极,第二个是消极。Score表示置信度,看来模型对这两句话的判断是斩钉截铁的(0.95+)
4 推荐课程和资源网站
以下是本文档用到的课程和资源,很可能需要魔法上网
Huggingface的NLP课程:
https://huggingface.co/learn/nlp-course/
Huggingface的模型网站:
Huggingface的数据集:
https://huggingface.co/datasets
中文的transformer入门教程:
5 特别鸣谢chatGPT
如果没有你,如果我只能在CSDN这样无脑复制粘贴AI洗稿还要积分的聪明网站苦苦搜寻。有了你,我只需要2个小时就可以完成安装和开发文档步骤说明。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)