TiDB 在全球头部物流企业计费管理系统的应用实践
作者: TiDB社区小助手 原文来源:https://tidb.net/blog/5e5e35c5...
作者: TiDB社区小助手 原文来源: https://tidb.net/blog/5e5e35c5
导读
本文介绍了某全球头部物流企业采用 TiDB 解决计费管理系统性能瓶颈的实践。原系统采用的云数据库受限于架构而无法水平扩展,导致高并发性能问题。该企业通过选择 TiDB,成功打破了性能瓶颈,实现了无缝水平扩展,降低了开发和运维负担。TiDB 的 HTAP 特性带来实时轻量级分析汇总的优势,避免了数据同步风险,为计费管理系统提供了高性能、可维护的全面解决方案。
该物流企业是以快递和跨境物流为核心业务的综合物流服务运营商。快递业务在中国和东南亚市场处于领先地位,快递网络覆盖中国、新加坡、印度尼西亚、越南、马来西亚、泰国等 10 多个国家,每年为数百万个家庭和企业提供快递服务。
业务挑战
计费管理系统(财务系统)是快递行业的核心系统,承担了所有快递服务的应收应付管理和合作伙伴的应付管理等重要职责,系统的性能和稳定性对于整个快递行业的运营和管理都至关重要。
计费管理系统最初采用云数据库(PolarDB)作为服务的承载。随着业务迅猛增长,云数据库的性能受到了架构限制,无法进行水平扩展,这对系统在面对高并发请求时的性能产生了负面影响,进而损害了用户体验。系统只能通过纵向升级硬件规格来提高处理能力和存储容量,这种扩展方式不仅需要购买更高规格的硬件设备,导致机器成本大幅上升,升级的过程需要进行停机维护。
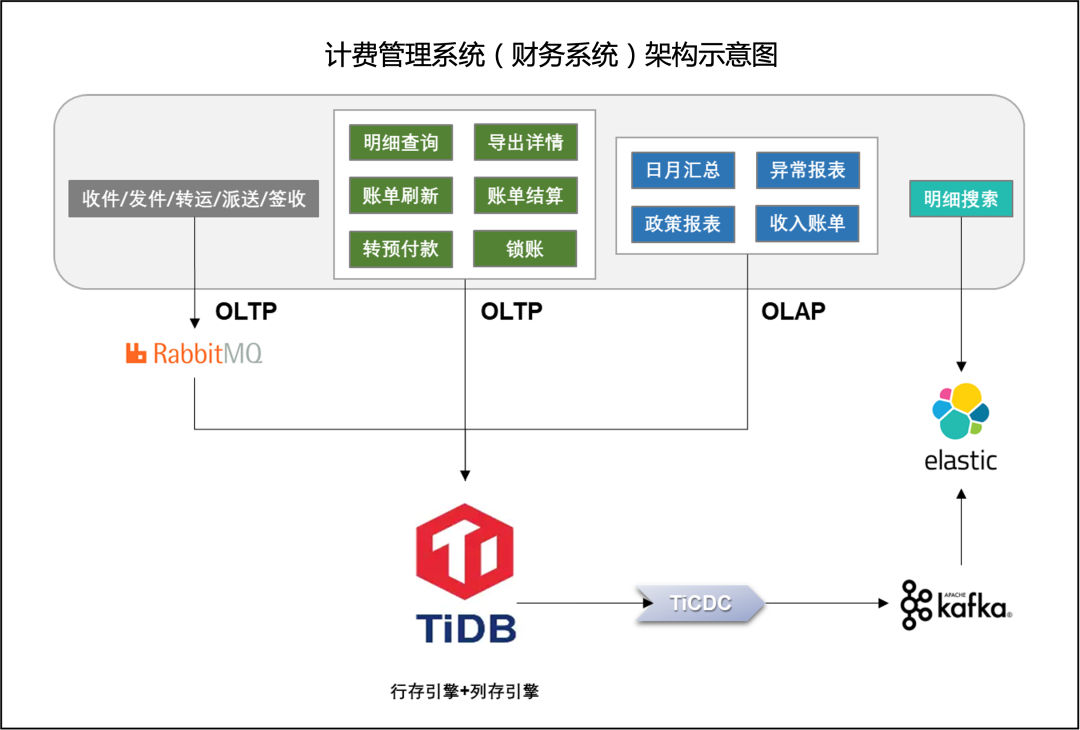
为了解决这个问题,该公司采用了多个数据同步工具来实现数据的计算和流转。系统使用 Kettle 工具将 PolarDB 数据同步至 ElasticSearch,使用 DTS 工具将数据同步到 AnalyticDB,AnalyticDB 中的数据则用于执行计算并支持报表系统的功能。系统中的聚合查询主要由 ElasticSearch 来支持。这种实现方式带来了系统架构的复杂性,使得数据流转周期延长,流程变得更加复杂,数据同步和计算过程容易出现问题,需要系统管理员进行定期的优化和维护,以支持更高的并发量和更复杂的业务场景。
解决方案
经过对比测试与应用兼容验证后,该企业选择 TiDB 分布式数据库拓展数据架构体系的能力版图。TiDB 解决了计费管理系统的性能瓶颈问题,优化了整体架构,提高了系统可维护性和可扩展性,同时保障系统高性能、平稳运行。

TiDB 原生分布式架构支持线性水平扩展,很好地解决了系统的性能瓶颈问题,在业务不断发展的情况下,系统可以随时按需进行扩容和缩容,从而满足更高并发和更复杂的业务需求。TiDB 用一个技术栈替换了原有的 PolarDB、AnalyticDB、DTS、CANAL 等多个数据技术栈,通过 TiDB 的生态工具 TiCDC 将数据同步到 ElasticSearch 为前端应用提供明细搜索,在降低系统复杂度的同时提升了计费管理系统的可维护性。此外,TiDB 具备热点数据打散和负载自动均衡的能力,对热点数据的处理更加高效,保障了系统资源的合理利用,降低系统出现性能问题的风险。
应用价值
无缝水平扩展,无需分库分表
TiDB 原生分布式架构设计具备无缝水平扩展的核心优势。随着数据量的增长,TiDB 可以动态地添加更多的存储和计算资源以适应业务的发展。自动化扩展能力避免了用户进行分库分表的复杂操作,极大地减轻了开发和运维负担。TiDB 强大的事务一致性保证使得开发者可以专注于业务逻辑,而不必担心复杂的数据库操作。
对比之下,尽管 PolarDB 提供了读写分离和自动备份等高级功能,但是当数据量达到一定规模时,它需要手动进行分库分表操作以保证系统的性能和稳定性。这不仅需要投入额外的人力资源,而且在分库分表的过程中可能会引发数据一致性和事务管理的问题。使用 PolarDB 进行分库分表后,如果业务发展需要调整分片策略,就需要进行复杂且耗时的重新分片操作,这可能会带来业务中断的风险。
HTAP 特性带来的优势
- 实时轻量级分析汇总
TiDB 的 HTAP 特性允许它同时处理在线事务处理和在线分析处理,无需进行数据同步和转换。因此,它可以实时地进行轻量级的分析汇总,如生成日报和月报表。这种实时的、快速的数据处理方式,大大提高了企业的决策效率,并简化了数据处理过程。
- 避免数据同步的风险
传统的数据处理方式通常需要建立多个数据同步链路,将事务数据同步到分析数据库中。这种模式不仅增加了数据处理的复杂性,还可能在数据同步过程中引发数据不一致的风险。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)