
Kylin(麒麟)安装及简单使用
前置准备Zookeeper单机环境和集群环境搭建视频+图文教程Hadoop单机伪分布式-视频教程Hadoop完全分布式集群环境搭建-视频教程HA(高可用)-Hadoop集群环境搭建视频+图文教程Linux下Hive的安装HBase单机伪分布式集群环境搭建-视频教程HA-HBase集群环境搭建-视频教程一、概述Apache Kylin™是一个开源的、分布式的分析引擎,提供 Ha...
前置准备
一、概述
Apache Kylin™是一个开源的、分布式的分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
(Online Analytical Process),联机分析处理, 或者在线分析
Apache Kylin也是中国人主导的、唯一的Apache顶级开源项目,在开源社区有世界级的影响力。
二、安装
2.1 下载并解压
下载所需版本的 Kylin ,这里我下载的是最新版本的 Kylin-3.0.1 。下载地址为:http://kylin.apache.org/cn/download/
# 下载后进行解压
[xiaokang@hadoop ~]$ tar -zxvf apache-kylin-3.0.1-bin-hbase1x.tar.gz -C /opt/software/
2.2 检查环境变量
需要在/etc/profile文件中配置$HADOOP_HOME、$HIVE_HOME、$HBASE_HOME
[xiaokang@hadoop01 ~]$ echo $HADOOP_HOME
/opt/software/hadoop-2.7.7
[xiaokang@hadoop01 ~]$ echo $HIVE_HOME
/opt/software/hive-2.3.6
[xiaokang@hadoop01 ~]$ echo $HBASE_HOME
/opt/software/hbase-1.4.13
2.3 配置环境变量
[xiaokang@hadoop ~]$ sudo vim /etc/profile
添加环境变量:
export KYLIN_HOME=/opt/software/kylin-3.0.1
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${HIVE_HOME}/bin:${HBASE_HOME}/bin:${KYLIN_HOME}/bin:$PATH
使得配置的环境变量立即生效:
[xiaokang@hadoop ~]$ source /etc/profile
2.4 修改配置
进入安装目录下的 conf 目录,修改keylin.properties中的时区配置
[xiaokang@hadoop01 ~]$ cd /opt/software/kylin-3.0.1/conf/
[xiaokang@hadoop01 conf]$ vim kylin.properties
# 改成东八区, 否则会出现时间显示不准的问题
kylin.web.timezone=GMT+8
由于我们这里不采用Spark作为计算引擎,所以需要将bin目录下的kylin.sh脚本进行修改
if [[ -z $reload_dependency && `ls -1 ${dir}/cached-* 2>/dev/null | wc -l` -eq 5 ]]
then
echo "Using cached dependency..."
source ${dir}/cached-hive-dependency.sh
source ${dir}/cached-hbase-dependency.sh
source ${dir}/cached-hadoop-conf-dir.sh
source ${dir}/cached-kafka-dependency.sh
#source ${dir}/cached-spark-dependency.sh
else
source ${dir}/find-hive-dependency.sh
source ${dir}/find-hbase-dependency.sh
source ${dir}/find-hadoop-conf-dir.sh
source ${dir}/find-kafka-dependency.sh
#source ${dir}/find-spark-dependency.sh
fi
2.5 启动Kylin
启动Kylin之前确保HDFS、YARN、Zookeeper、HBase已经启动
[xiaokang@hadoop01 ~]$ kylin.sh start
2.6 登录Kylin Web
http://hadoop01:7070/kylin/login
登录名:ADMIN,密码:KYLIN 全部都是大写字母
2.7 可能出现的问题
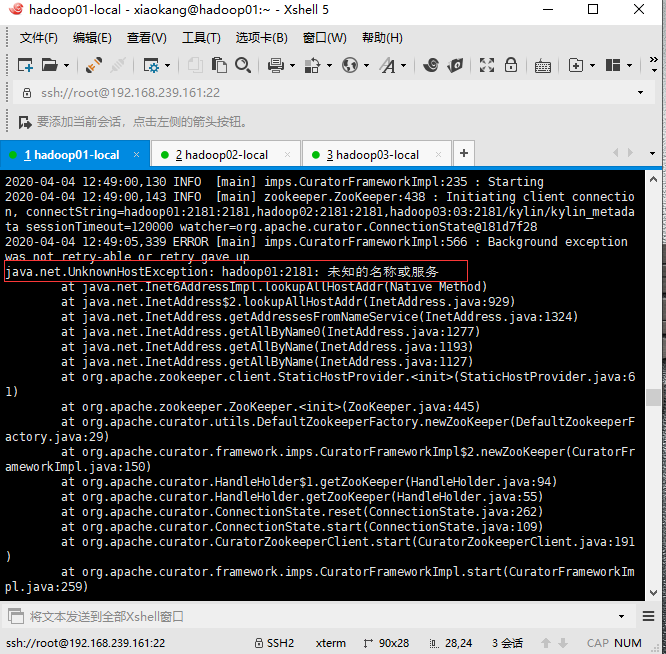
解决方案:
需要把 HBase 的hbase-site.xml 中的关于 Zookeeper 的配置中的端口号2181去掉.
<!--指定 zookeeper 地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
三、基本使用
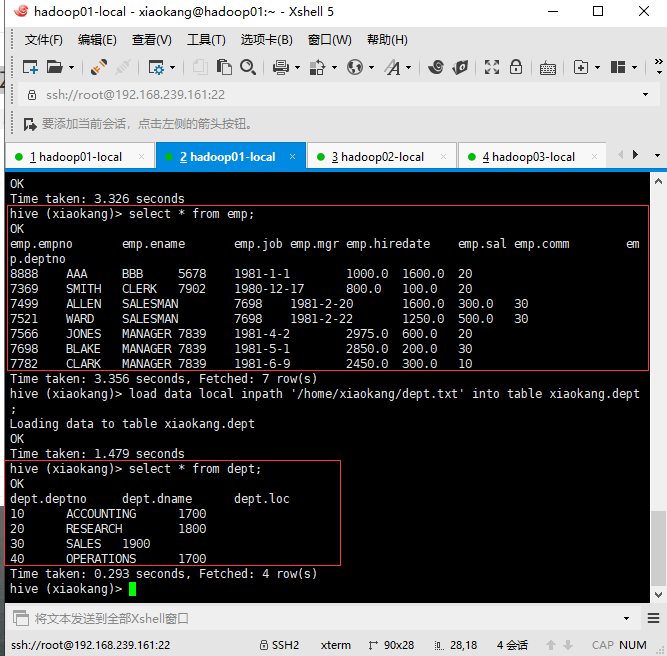
3.1 准备数据
# 建表 dept
create external table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
# 建表 emp
create external table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
# 分别向两张表导入数据
load data local inpath '/home/xiaokang/dept.txt' into table xiaokang.dept;
load data local inpath '/home/xiaokang/emp.txt' into table xiaokang.emp;
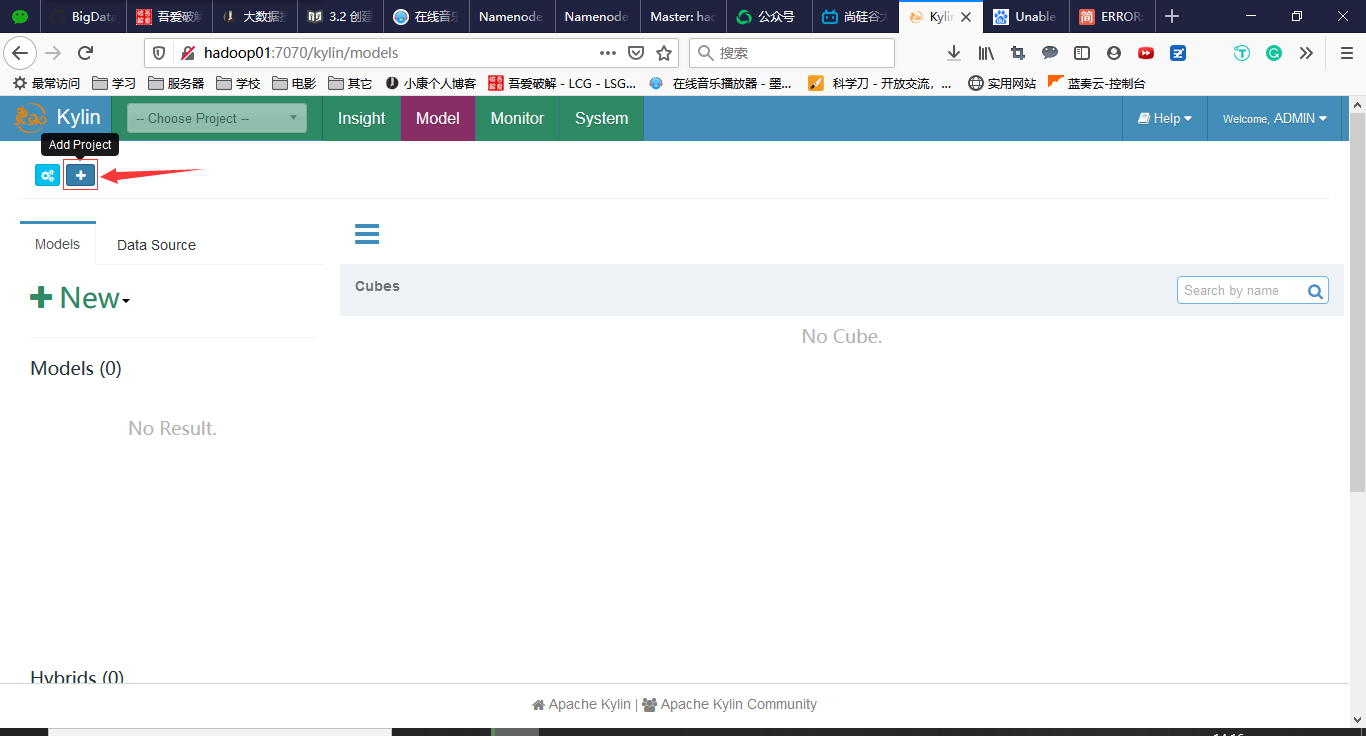
3.2 创建Project
1. 登录系统
账号:ADMIN 密码:KYLIN
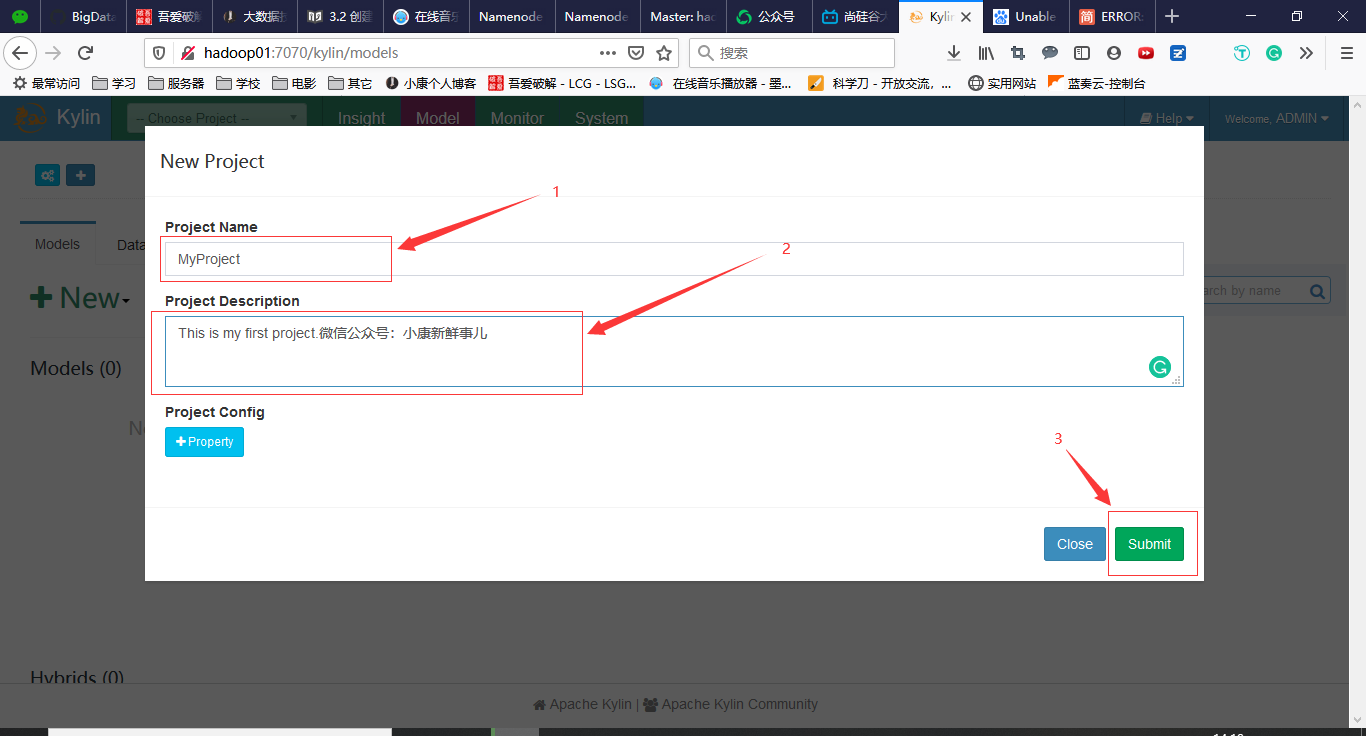
2. 创建Project
点击+号,输入项目名称和描述,然后点击submit
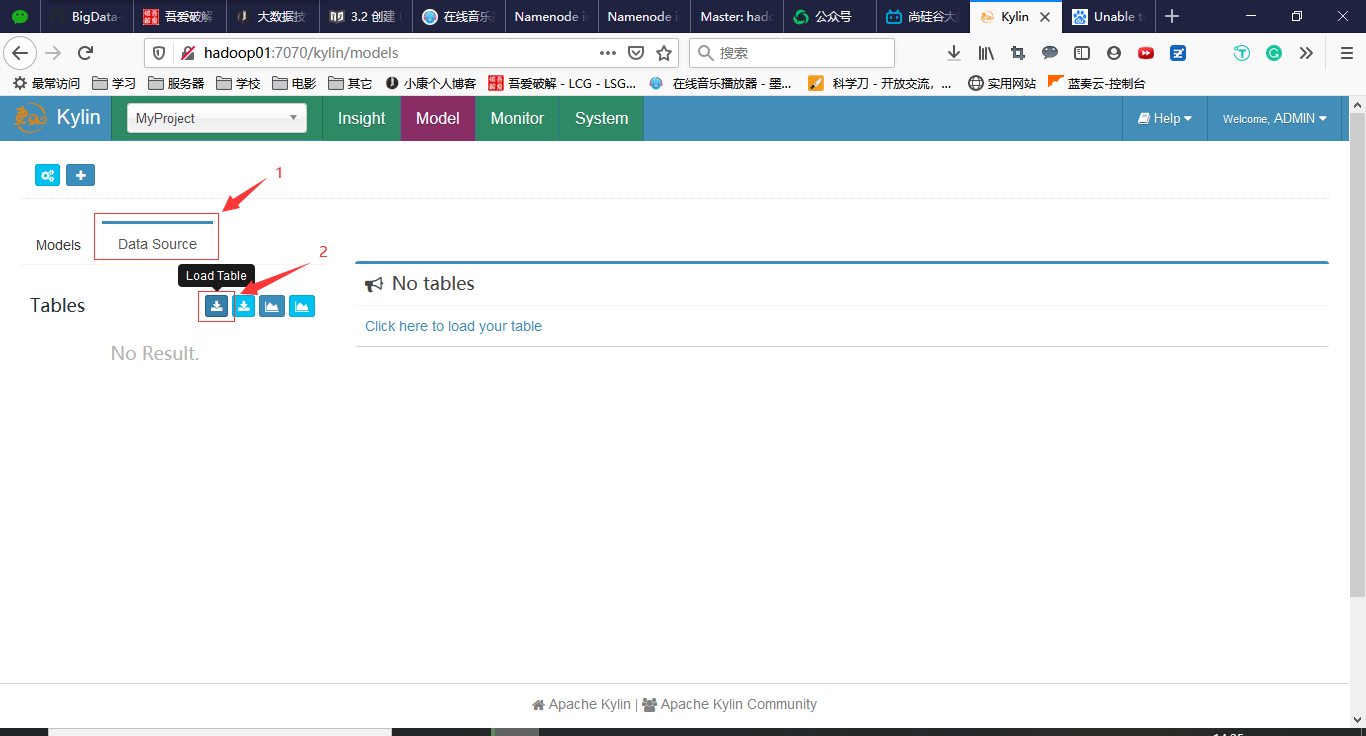
3. 选择数据源
点击Data Source,然后点击Load Table
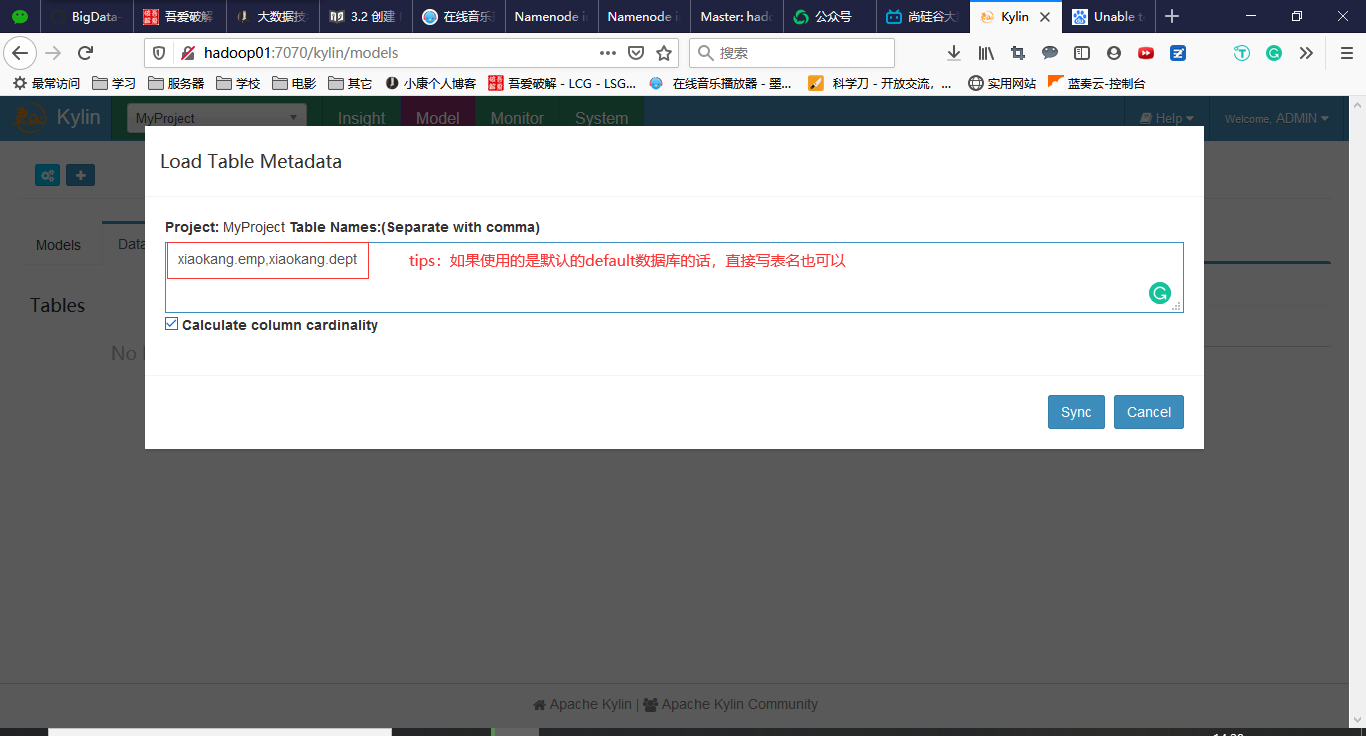
输入需要加载的Hive中的表
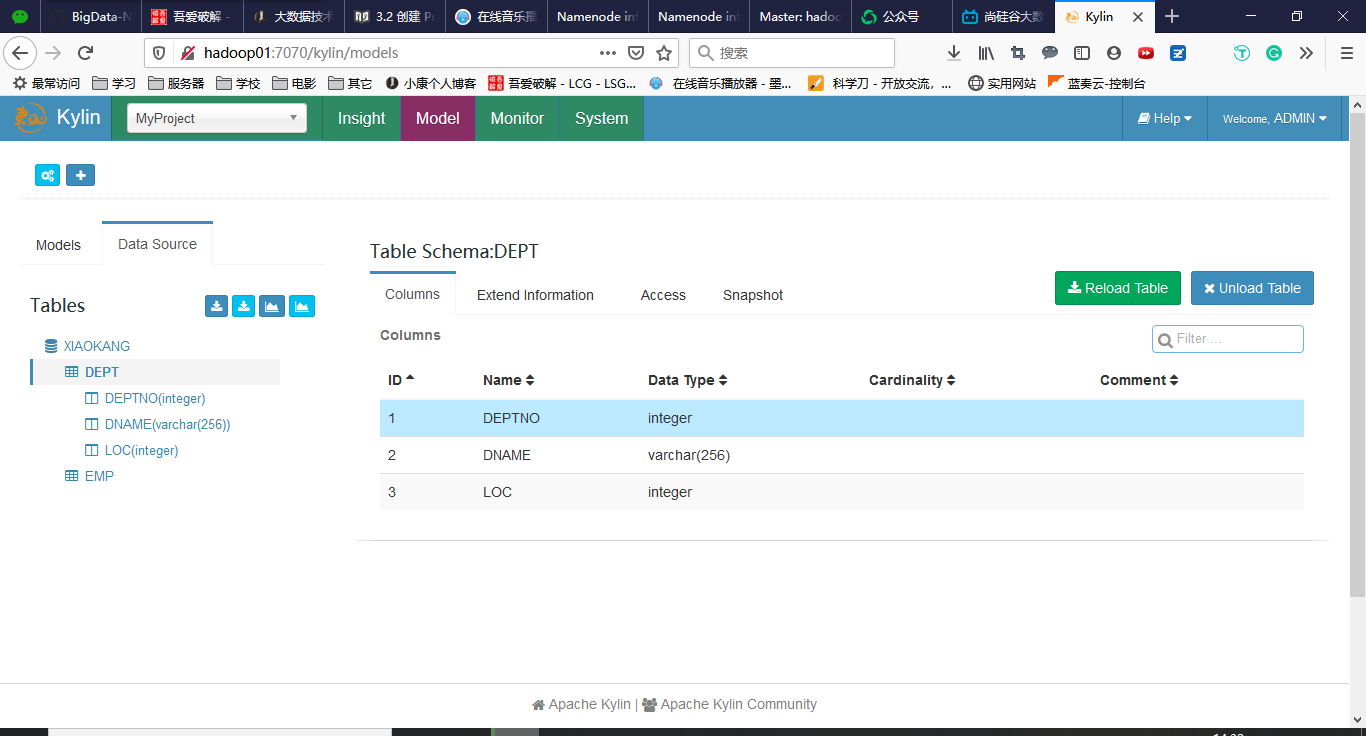
查看数据源
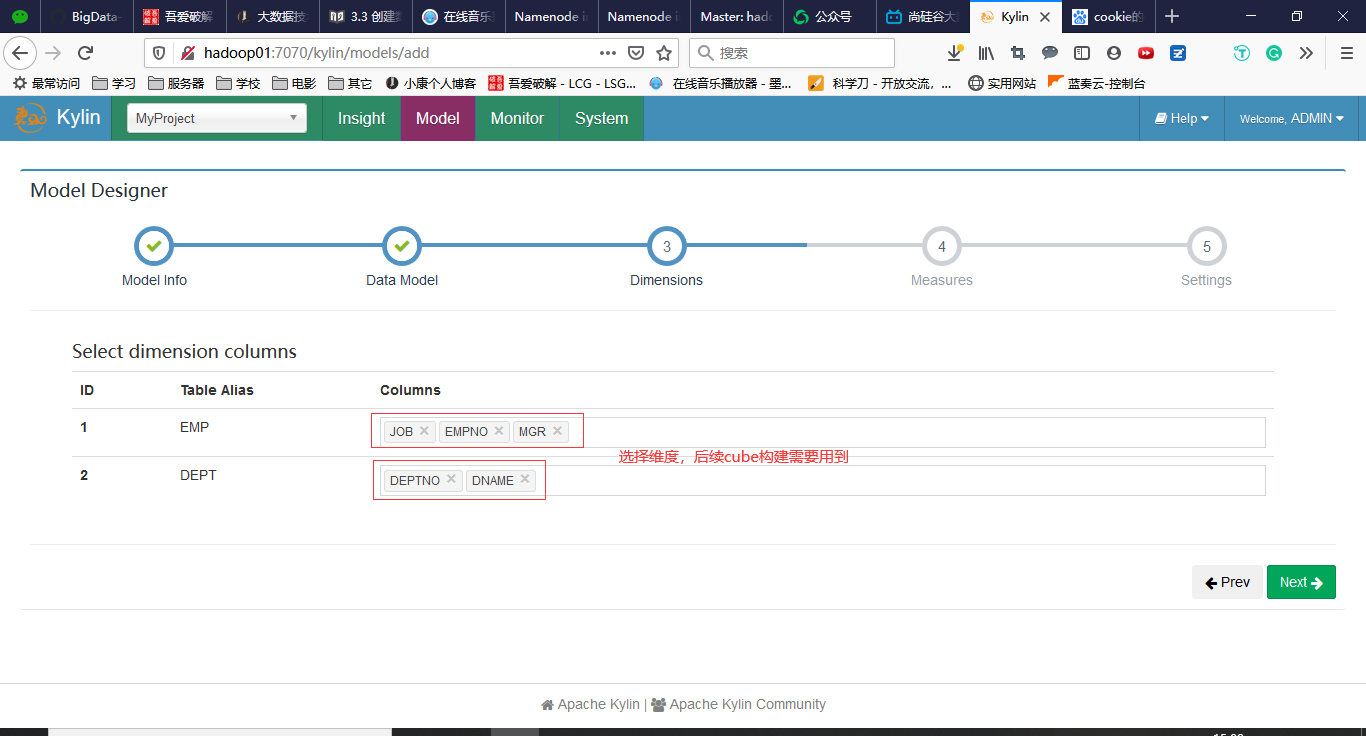
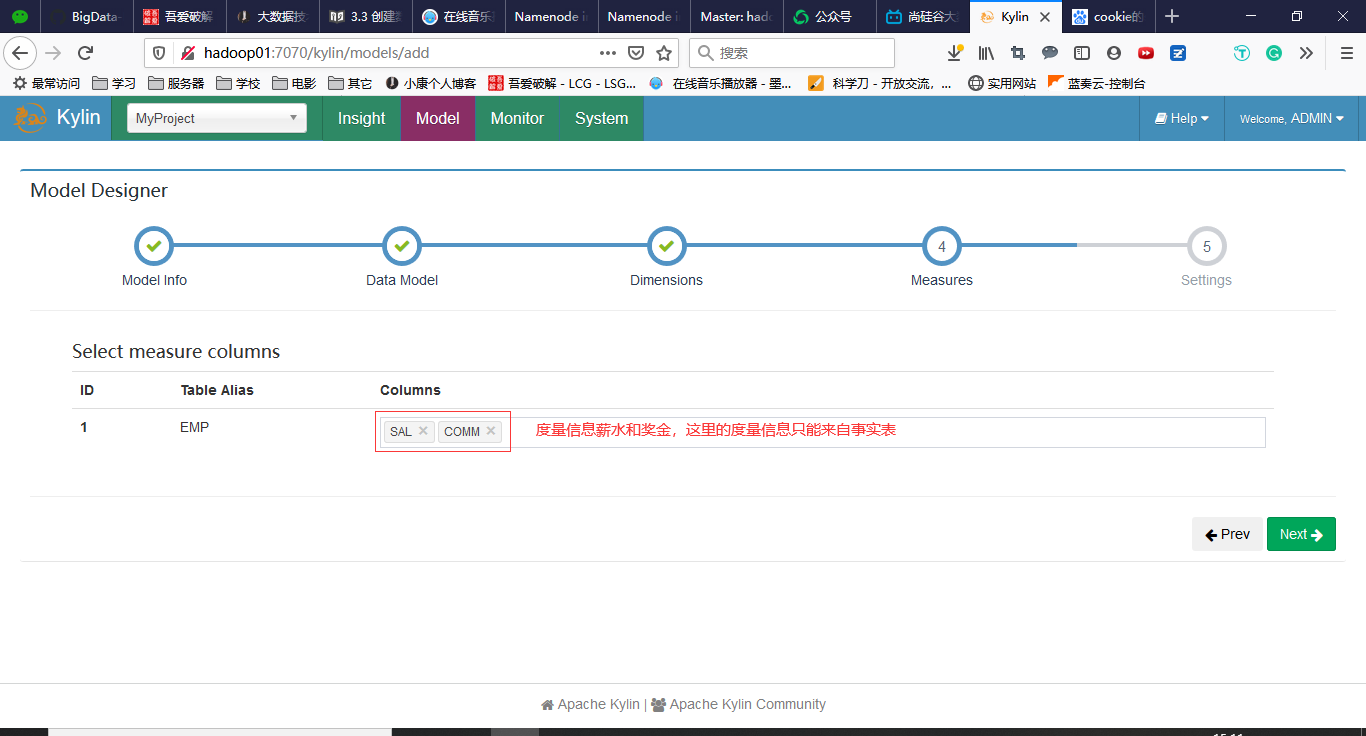
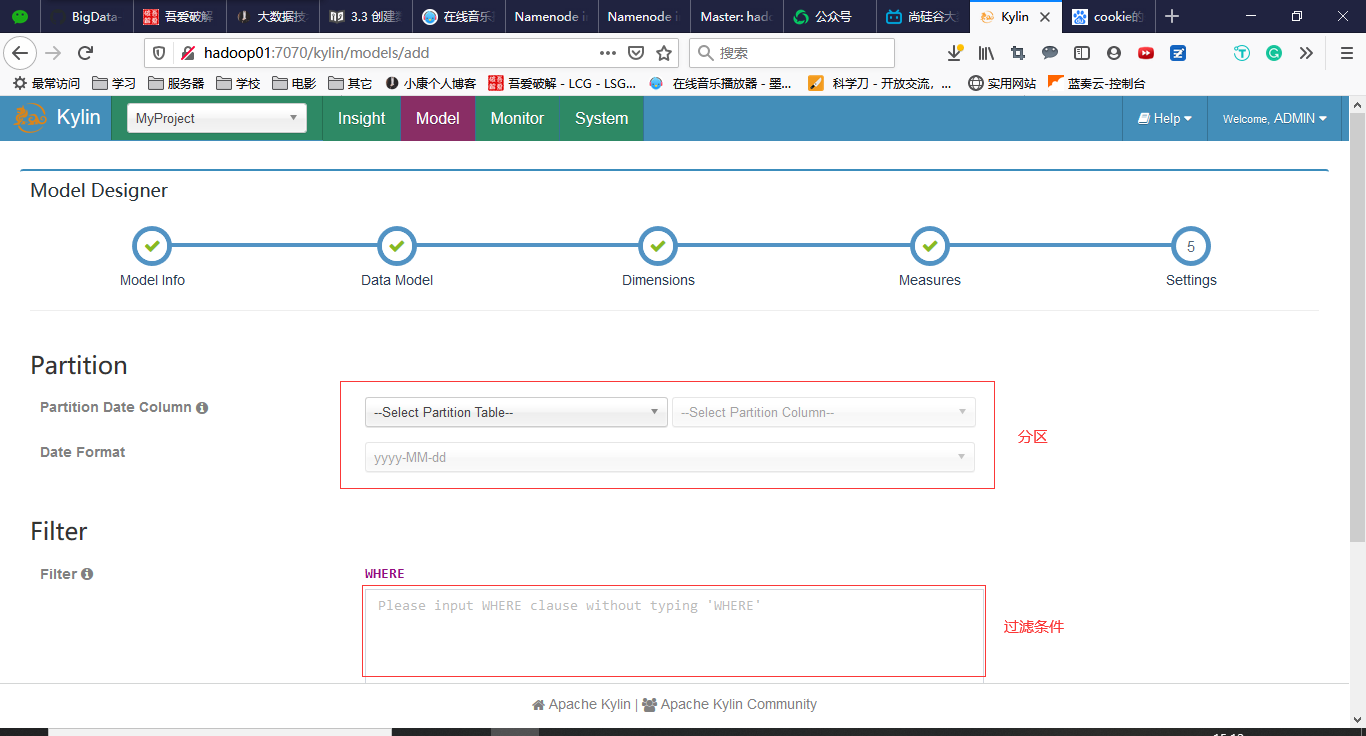
3.3 创建数据模型(Model)
回到Models,点击New->New Model
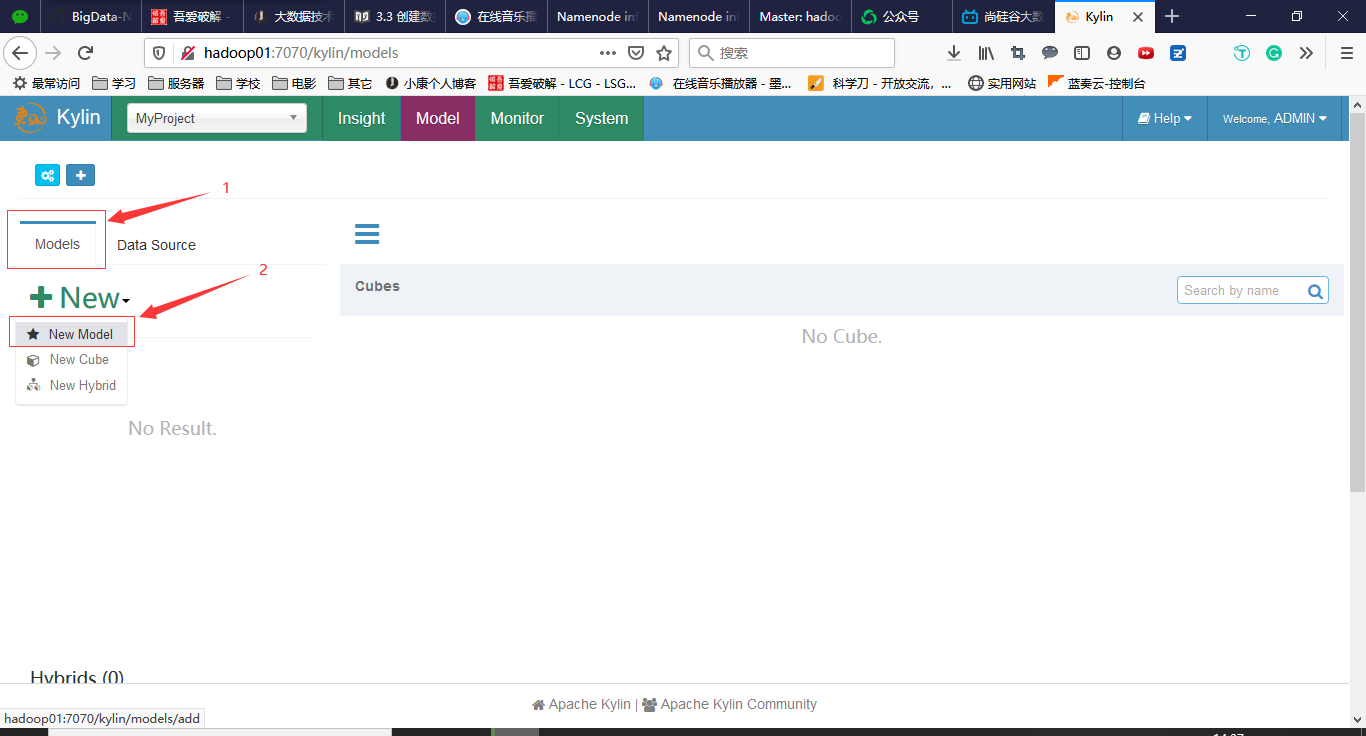
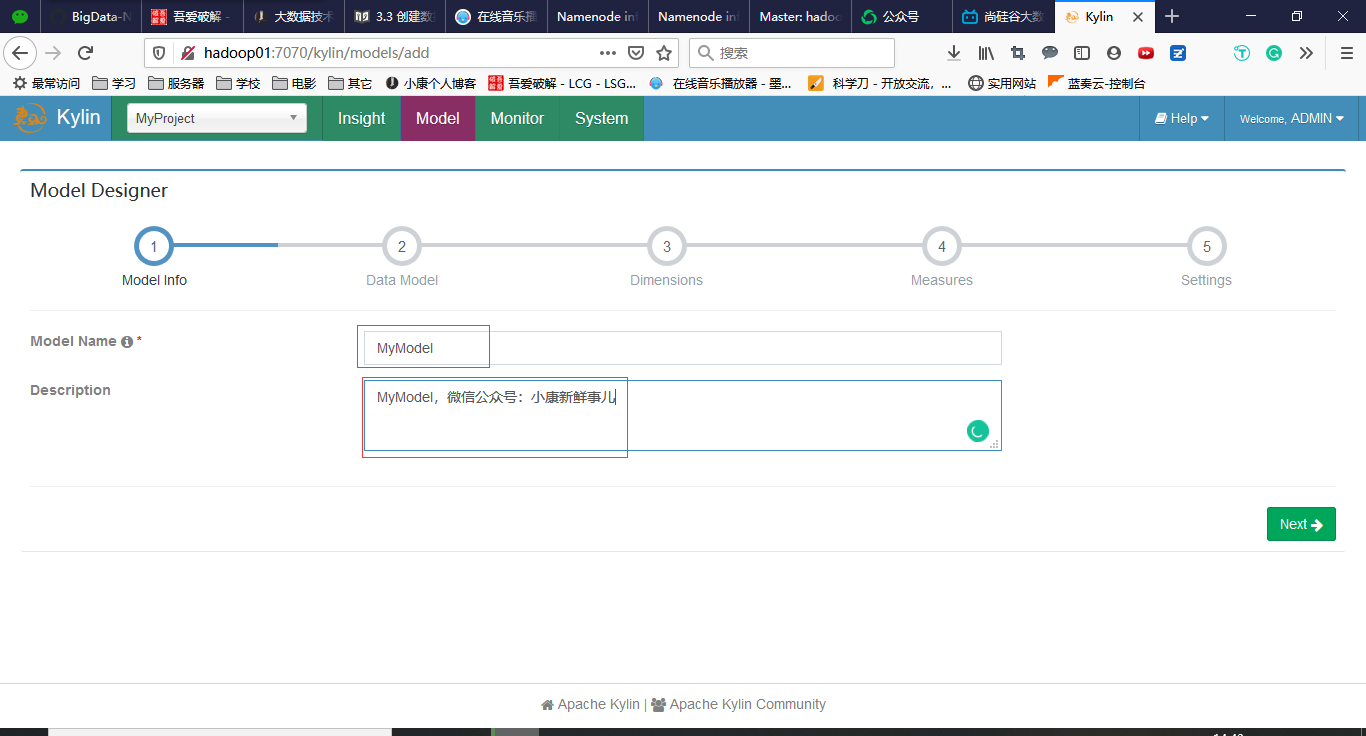
填写相关信息,如下图所示
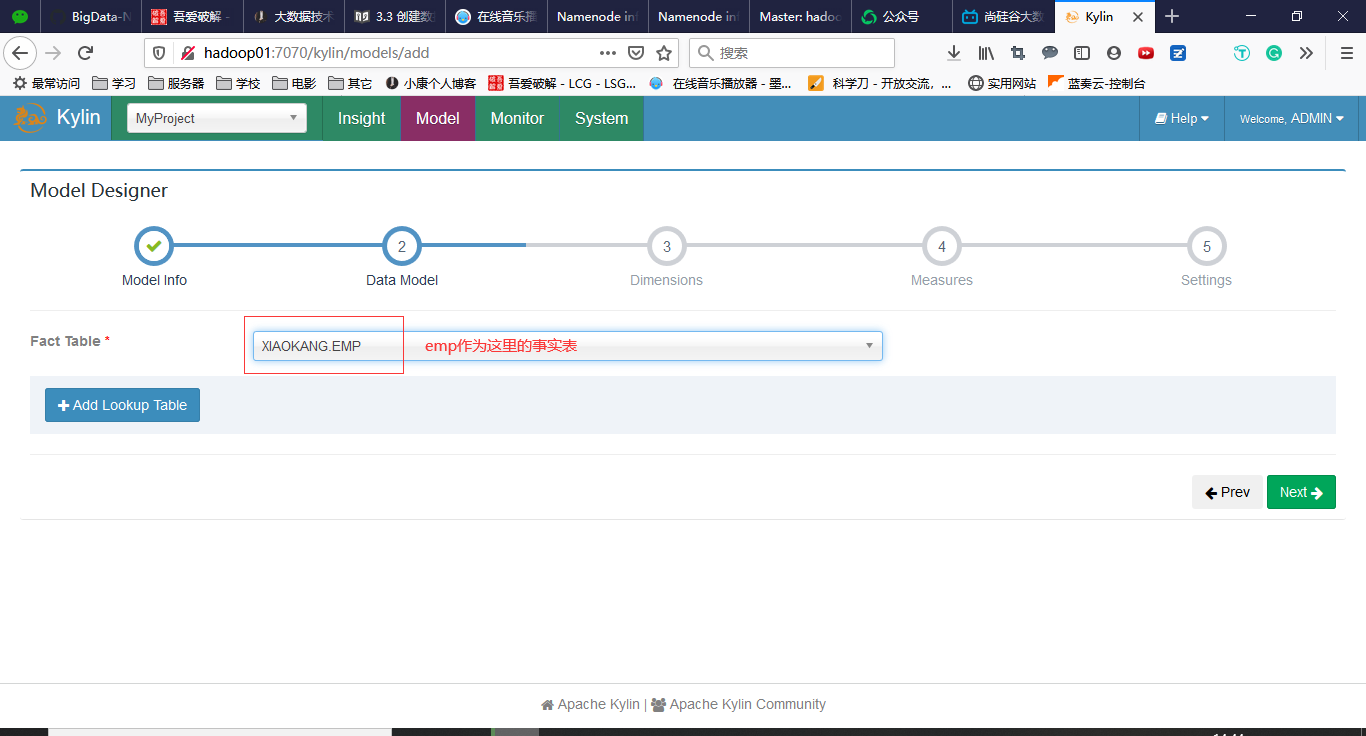
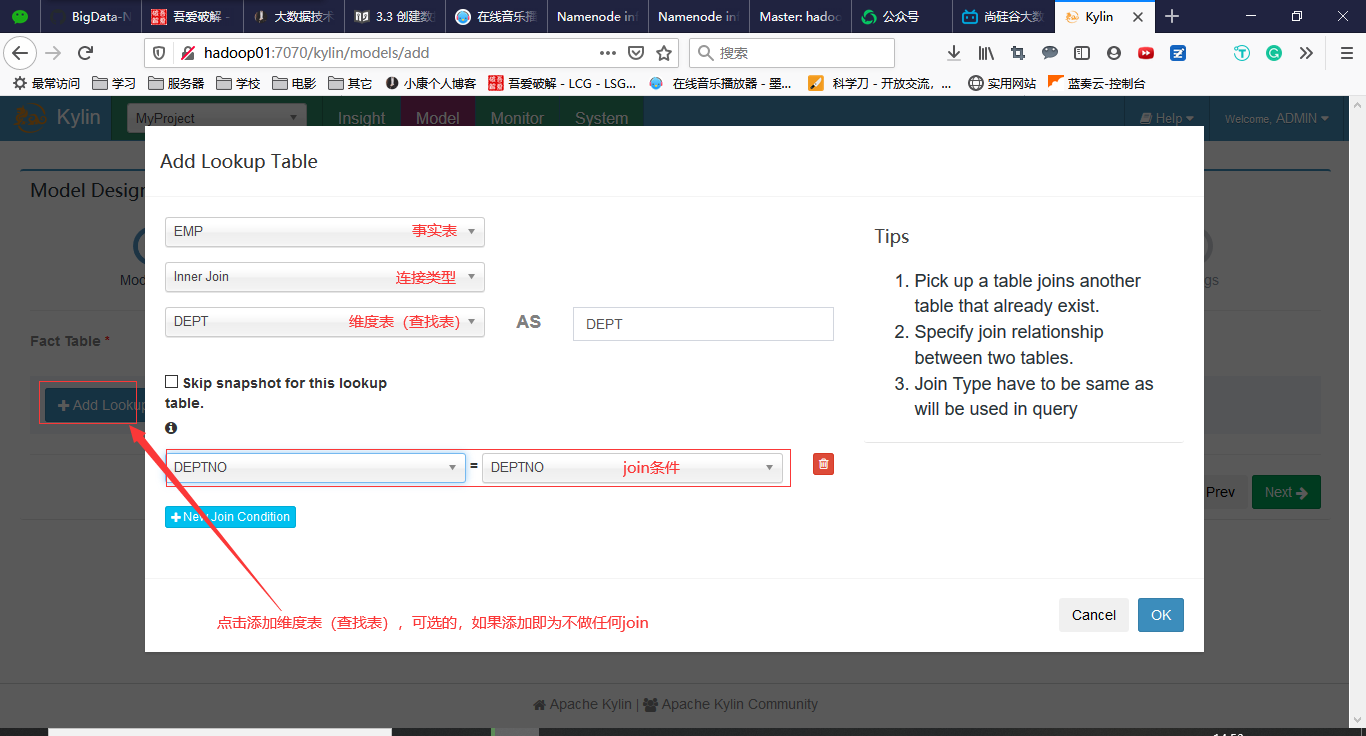
3.4 创建Cube
回到Models,点击New->New Cube
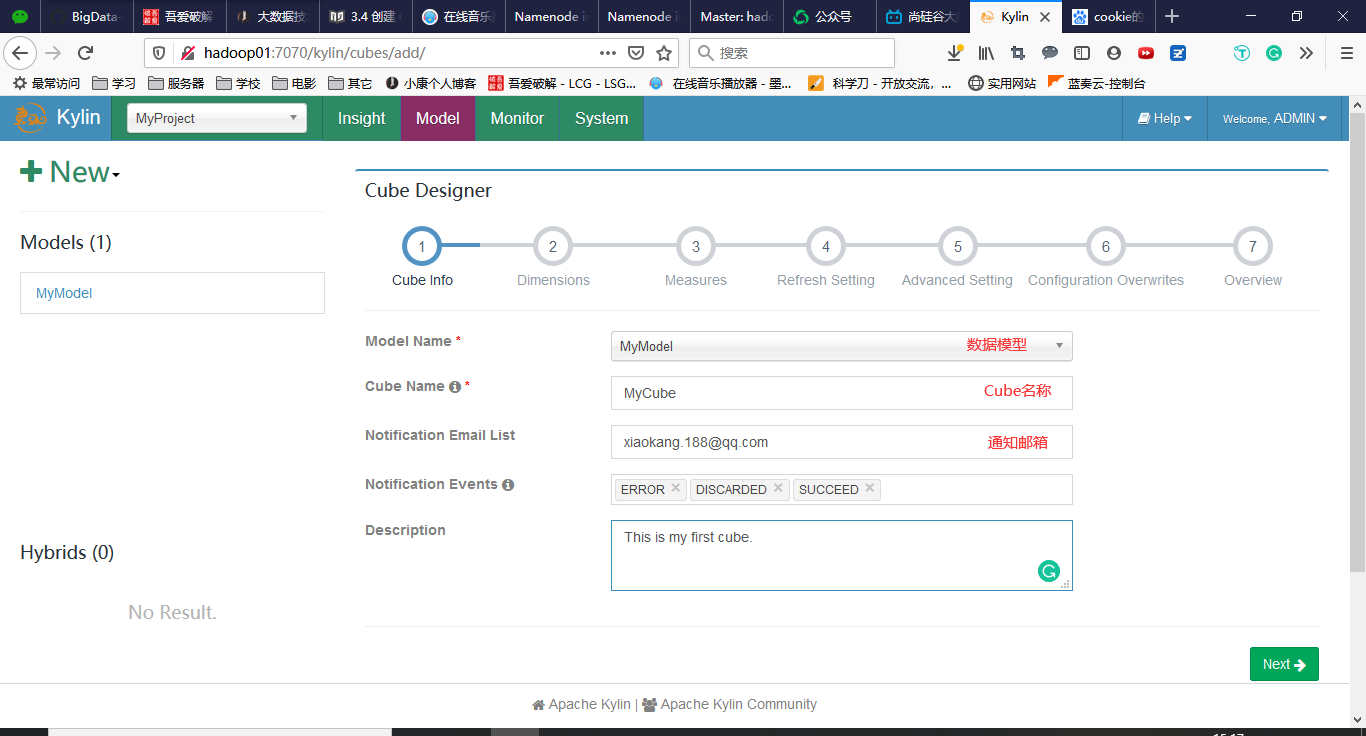
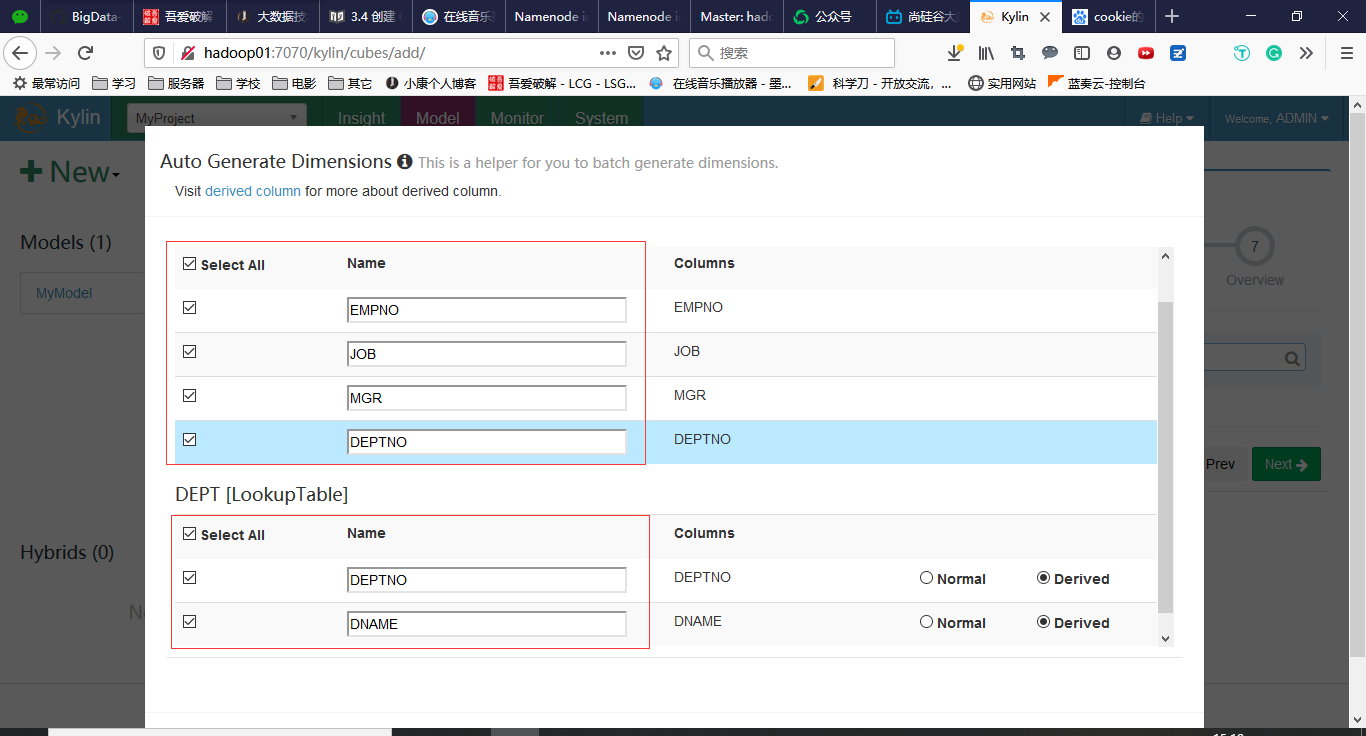
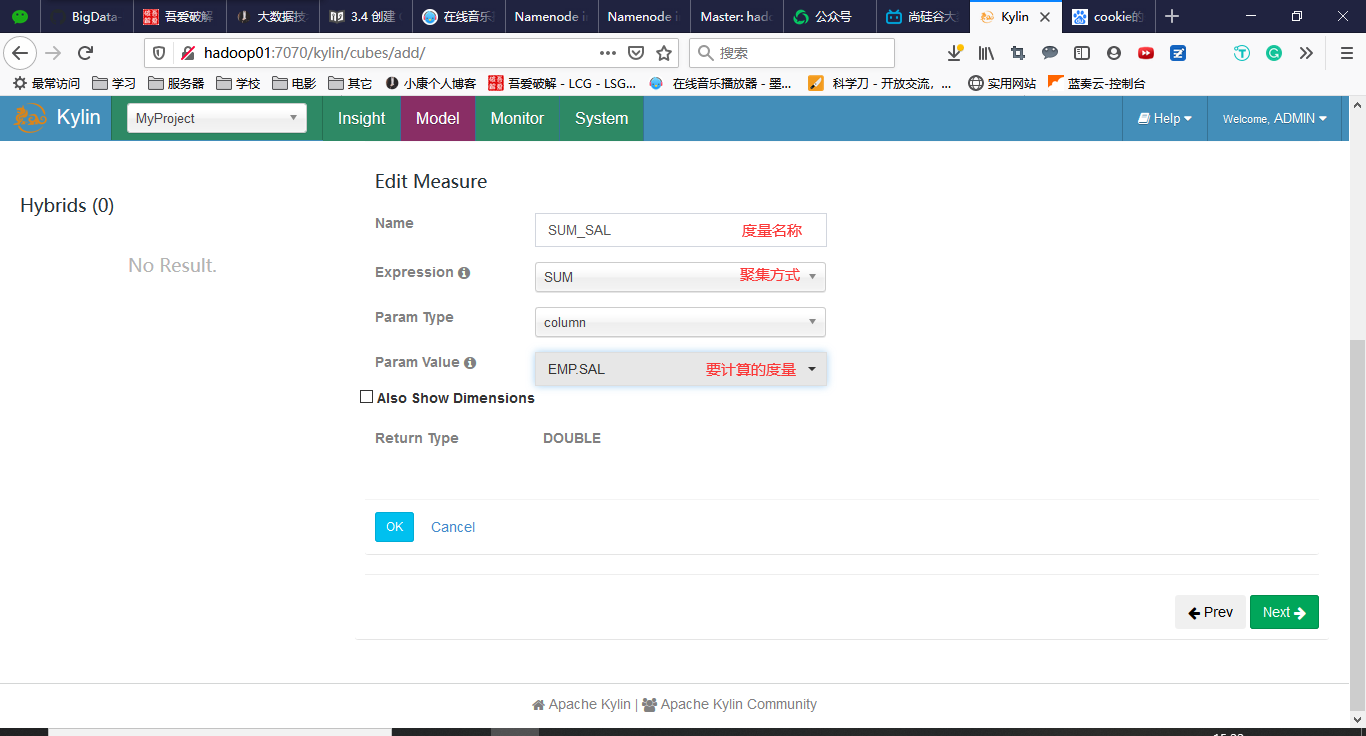
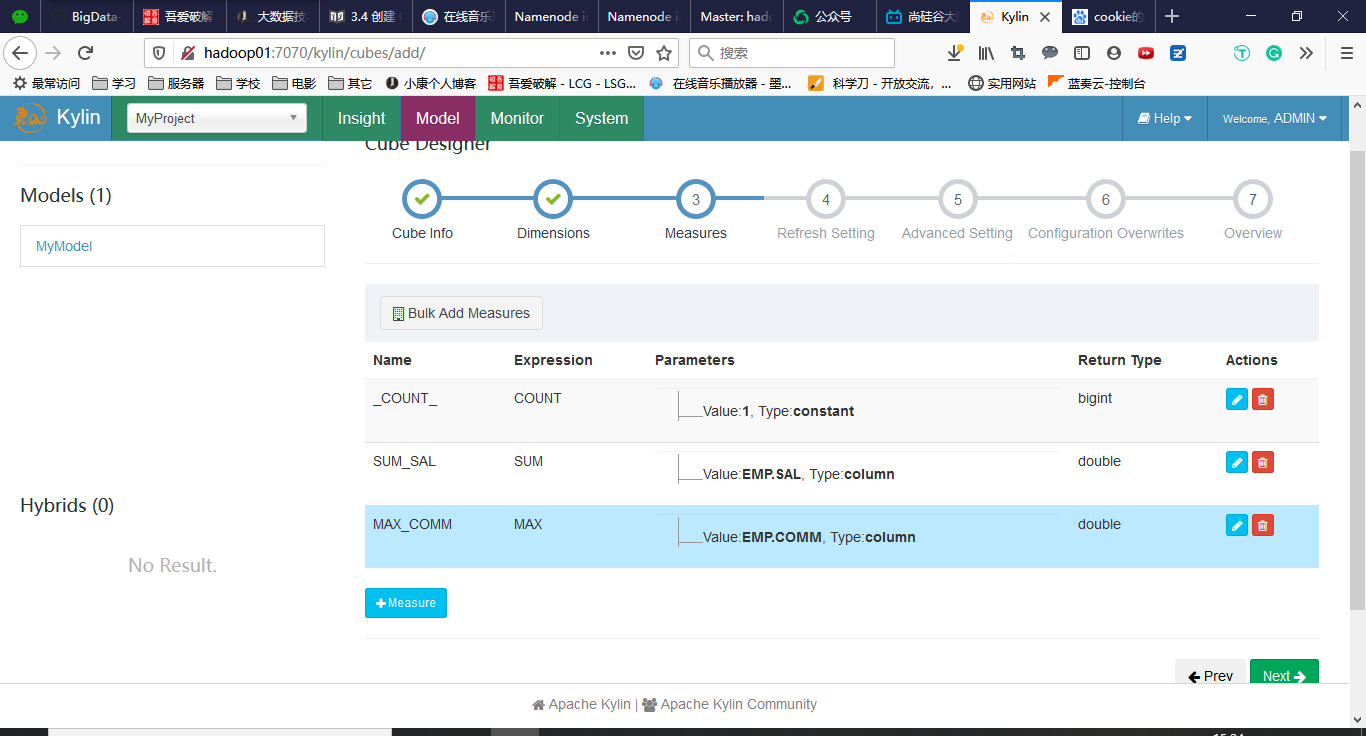
点击Save完成Cube的创建
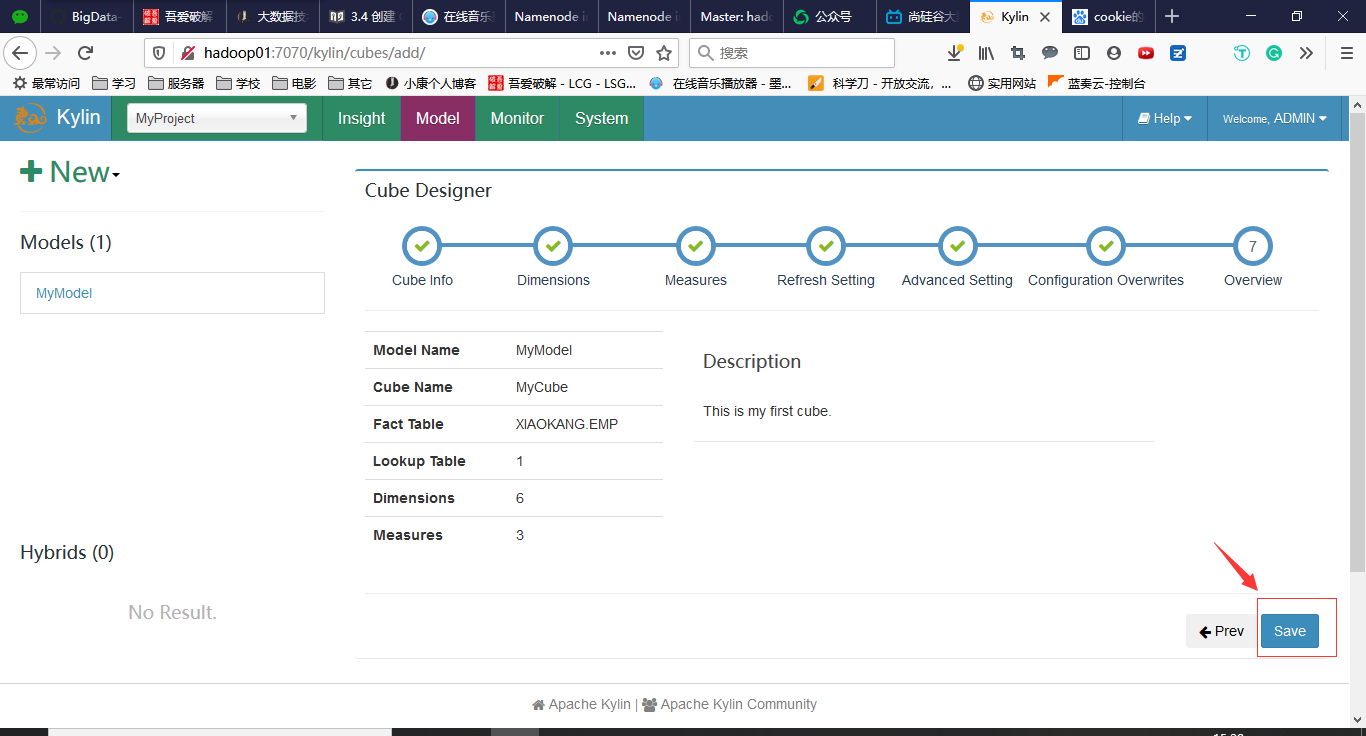
Cube创建完成后,需要进行Build
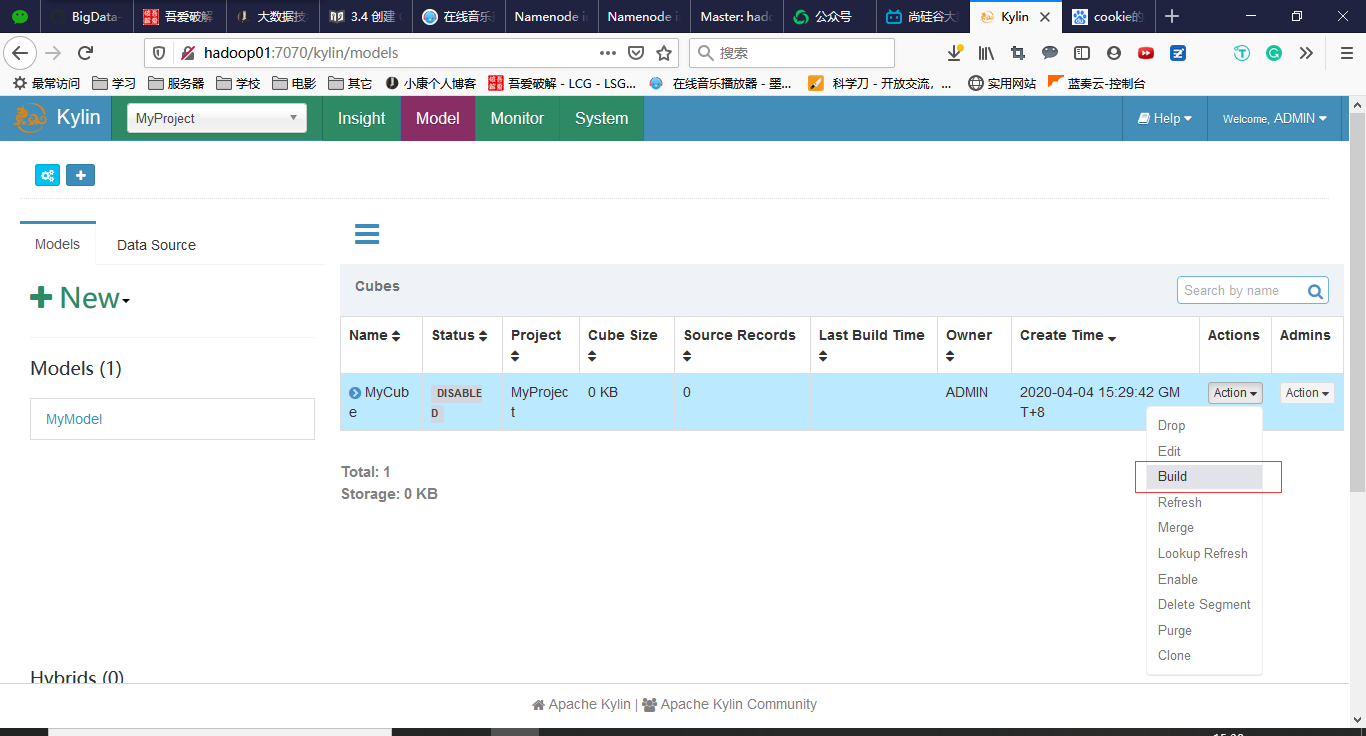
查看Build详细进度
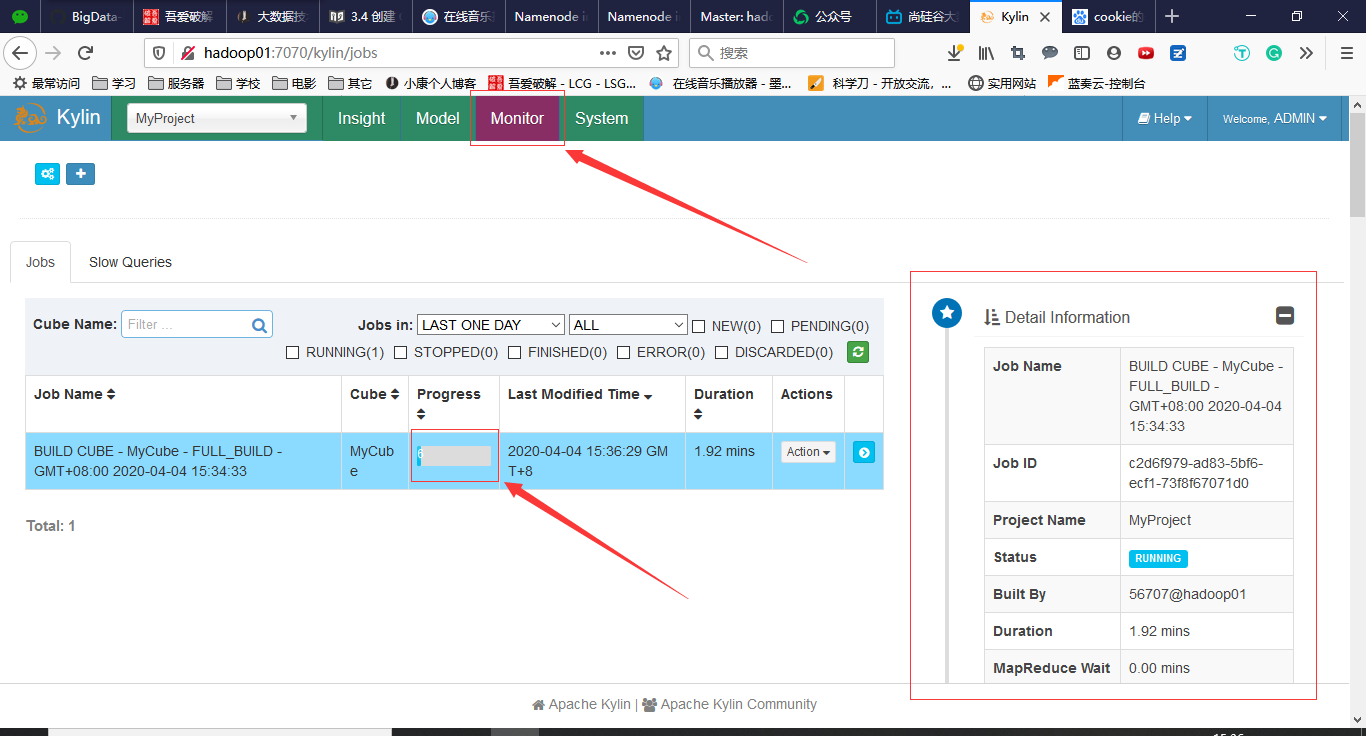
3.5 查询
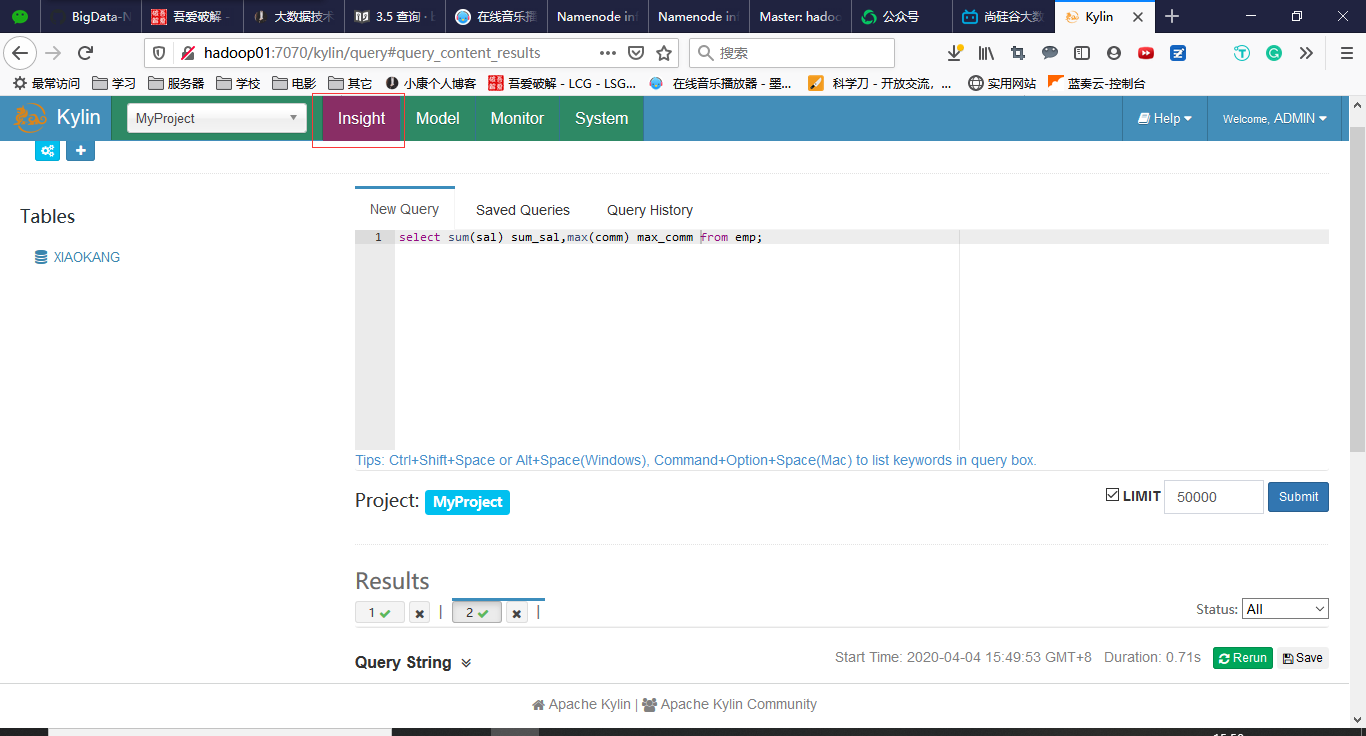
select sum(sal) sum_sal,max(comm) from emp;
在Kylin中用时7秒多,第二次查询的话仅仅0.0几秒(缓存)
在Hive中用时27秒左右
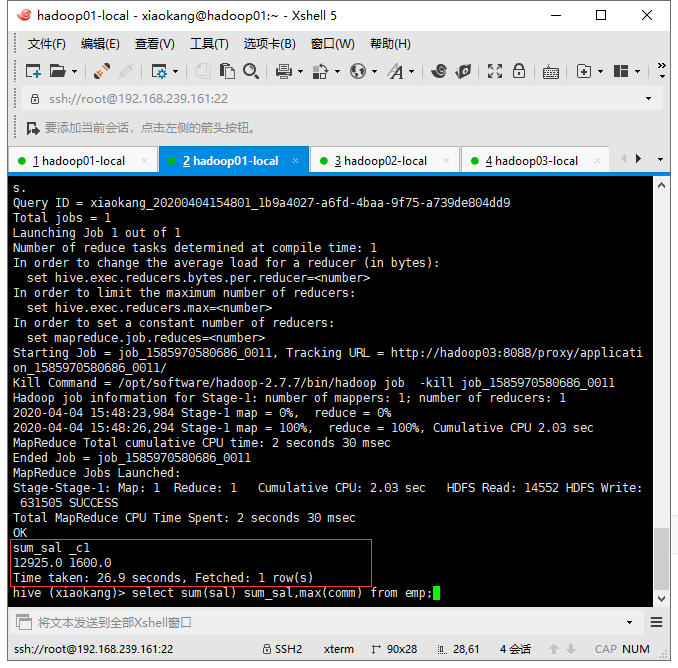
#Kylin用时0.77s,Hive用时24.214s
select count(*) from emp group by deptno;

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)