

[论文阅读] RSS2023 Paper Sessions概况
一、Human-Centered RoboticsFollow my Advice: Assume-Guarantee Approach to Task Planning with Human in the Loop:Autonomous Justification for Enabling Explainable Decision Support in Human-Robot Teaming:人

Human-Centered Robotics
- Autonomous Justification for Enabling Explainable Decision Support in Human-Robot Teaming:人机协作中自动agent提供可解释的建议
- Enabling Team of Teams: A Trust Inference and Propagation (TIP) Model in Multi-Human Multi-Robot Teams:提出了用于多人多机器人团队中信任建模的信任推理和传播(TIP)模型
- Investigating the Impact of Experience on a User's Ability to Perform Hierarchical Abstraction(Nominated for Best Student Paper):通过提供演示来增加参与者的经验可以提高他们的演示在新领域中的子任务抽象程度 (p<.001)、教学效率 (p<.001) 和子任务冗余 (p<.05),从而允许机器人教学中的推广
-
Robot Learning on the Job: Human-in-the-Loop Autonomy and Learning During Deployment(Nominated for Best Paper):提出了 Sirius,这是一个人类和机器人通过分工进行协作的原则框架。半自主机器人的任务是在可靠工作的情况下处理大部分决策;与此同时,人类操作员监控过程并在具有挑战性的情况下进行干预。我们引入了一种新的学习算法来提高策略在从任务执行中收集的数据上的性能,核心思想是用近似的人类信任重新权衡训练样本,并用加权行为克隆优化策略;Sirius 在一系列接触丰富的操作任务中始终优于基线,与最先进的方法相比,在模拟中实现了 8% 的提升,在真实硬件上实现了 27% 的提升
-
Robotic Table Tennis: A Case Study into a High Speed Learning System:在之前的工作中,该系统被证明能够与人类进行数百次乒乓球对打,并且能够精确地将球击回所需的目标;补充了完整的系统描述,包括许多通常不会广泛传播的设计决策,并通过一系列研究阐明了减轻各种延迟来源、考虑培训和部署分布变化、感知系统的稳健性、对策略超参数和行动空间的选择。
-
SAR: Generalization of Physiological Dexterity via Synergistic Action Representation:通过肌肉协同作用的模块化控制,即协调的肌肉共同收缩,被认为是一种假定的机制,使生物体能够在简化且可概括的动作空间中学习肌肉控制。从这种进化的运动控制策略中汲取灵感,我们使用生理上准确的手模型来研究利用从更简单的操作任务中获得的协同动作表示(SAR)是否可以改善更复杂任务的学习和泛化;使用机器人操作任务集和全身人形运动任务,我们建立了 SAR 在更广泛的高维控制问题上的通用性,实现了 SOTA 性能,这项研究是同类研究中第一个提出端到端pipeline,用于发现协同作用并使用这种表示来学习跨各种任务的高维连续控制
- One Policy to Dress Them All: Learning to Dress People with Diverse Poses and Garments:开发了一种机器人辅助穿衣系统,该系统能够根据学习的策略,根据部分点云观察,为具有不同姿势的人穿不同的衣服
Manipulation from Demonstrations and Teleoperation
-
Teach a Robot to FISH: Versatile Imitation from One Minute of Demonstrations(Nominated for Best Student Paper):我们提出了快速模仿人类技能(FISH),这是一种新的模仿学习方法,可以通过不到一分钟的人类演示来学习强大的视觉技能,给定通过离线模仿演示训练的弱基本策略,FISH 计算与机器人行为和演示之间的“匹配”相对应的奖励。然后,这些奖励用于自适应更新添加到基本策略的剩余策略,FISH 的构建具有多功能性,这使得它可以在机器人形态(例如 xArm、Allegro、Stretch)和相机配置(例如第三人称、手眼)中使用
-
GenAug: Retargeting behaviors to unseen situations via Generative Augmentation(Nominated for Best System Paper):为了使机器人学习具有普遍性,我们必须能够利用机器人自身经验之外的数据源或先验知识。在这项工作中,我们假设在大型网络抓取数据语料库上预先训练的图像文本生成模型可以作为这样的数据源。尽管这些生成模型主要是在非机器人数据上进行训练的,但它们可以作为有效的方法,以一种能够广泛推广的方式将先验知识传递到现实世界中的机器人学习过程中,我们展示了用于修复的预训练生成模型如何作为语义上有意义的数据增强的有效工具,通过利用这些预先训练的模型来生成适当的“功能”数据增强,我们提出了一个能够显着提高策略泛化能力的系统 GenAug
-
Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets:让机器人以数据有效的方式学习新颖的视觉运动技能仍然是一个尚未解决的问题,解决这个问题的一个流行范例是利用包含许多行为的大型未标记数据集,然后使用少量特定于任务的人工监督(即干预或演示)来调整策略以适应特定任务,如何最好地利用狭隘的特定任务监督并将其与离线数据平衡仍然是一个悬而未决的问题,我们在这项工作中的主要见解是,特定于任务的数据不仅为代理提供了用于训练的新数据,而且还可以告知代理应该用于学习的先前数据的类型,我们提出了一种简单的方法,使用少量下游专家干预或演示来有选择地从离线、未标记的数据集中查询相关行为,代理将接受专家数据和查询数据的联合训练。
-
Structured World Models from Human Videos:我们的方法构建了一个结构化的、以人为中心的动作空间,其基础是从人类视频中学到的视觉可供性。此外,我们在人类视频上训练世界模型,并在没有任何任务监督的情况下对少量机器人交互数据进行微调。我们证明,这种可供性空间世界模型的方法使不同的机器人能够在 30 分钟的交互内学习复杂环境中的各种操作技能
- PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection:收集大规模机器人数据的成本更高且速度更慢,因为每个操作员一次只能控制一个机器人。为了使这一成本高昂的数据收集过程变得高效且可扩展,我们提出了策略辅助远程操作(PATO),这是一个使用学习的辅助策略自动执行部分演示收集过程的系统,PATO 在数据收集中自动执行重复行为,并且仅在不确定要执行哪个子任务或行为时才要求人工输入,证明我们的辅助远程操作系统减少了人类操作员的精神负担,同时提高了数据收集效率
-
To the Noise and Back: Diffusion for Shared Autonomy:共享自主是一种操作概念,其中用户和自主代理协作控制机器人系统,在本文中,我们提出了一种共享自治的新方法,该方法采用扩散模型的前向和反向扩散过程的调制。我们的方法不假设已知的环境动态或用户目标的空间,并且与之前的工作相比,它不需要任何奖励反馈,也不需要在训练期间访问用户的策略,我们的框架学习期望行为空间的分布。然后,它采用扩散模型将用户的操作转换为该分布中的样本。至关重要的是,我们证明可以以保留用户控制权限的方式执行此过程。
- AnyTeleop: A General Vision-Based Dexterous Robot Arm-Hand Teleoperation System:当前基于视觉的远程操作系统是针对特定的机器人模型和部署环境进行设计的,随着机器人模型池的扩大和操作环境多样性的增加,其扩展性很差,我们提出了 AnyTeleop,这是一个统一且通用的远程操作系统,可在单个系统内支持多个不同的手臂、手、现实和相机配置。
-
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Self-supervision and RL for Manipulation
- Self-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction:我们引入了一种新颖的机器人系统,通过利用机器人与物体的长期交互来改善现实世界中看不见的物体实例分割,我们的系统在一系列机器人推动动作之后推迟了分割对象的决定。通过对机器人推送收集的图像应用多对象跟踪和视频对象分割,我们的系统可以以自我监督的方式生成这些图像中所有对象的分割掩模。我们通过使用我们的系统收集的真实世界数据对合成数据训练的分割网络进行微调来证明我们系统的实用性,我们验证了微调网络可以改善机器人对现实世界中看不见的物体的自上而下的抓取
- Self-Supervised Visuo-Tactile Pretraining to Locate and Follow Garment Features:视觉提供有关场景的全局信息,触觉在操作过程中测量局部信息,而不会受到遮挡。虽然之前的工作证明了触觉传感对于精确操纵可变形物体的功效,但它们通常依赖于受监督的、人类标记的数据集。我们提出了自监督视觉触觉预训练(SSVTP),这是一种通过跨模态监督以自监督方式学习多任务视觉触觉表征的框架,我们设计了一种机制,使机器人能够自主收集精确空间对齐的视觉和触觉图像对,然后训练视觉和触觉编码器使用跨模态对比损失将这些图像对嵌入到共享的潜在空间中。我们将这个潜在空间应用于平面上可变形服装的下游感知和控制
-
Pre-Training for Robots: Offline RL Enables Learning New Tasks in a Handful of Trials:如何利用现有的多样化离线数据集与少量特定于任务的数据相结合来解决新任务,同时仍然享受大量数据训练的泛化优势?在本文中,我们证明端到端离线强化学习可以是实现此目的的有效方法,而不需要任何表示学习或基于视觉的预训练。我们提出了机器人预训练(PTR),这是一个基于离线 RL 的框架,试图通过将现有机器人数据集的预训练与新任务的快速微调相结合来有效地学习新任务,PTR 利用现有的离线 RL 方法,保守 Q 学习 (CQL),但将其扩展为包括几个关键的设计决策,使 PTR 能够真正发挥作用并超越各种先前的方法。
-
Sampling-based Exploration for Reinforcement Learning of Dexterous Manipulation:在本文中,我们提出了一种新方法,可以实现复杂物体的灵巧操纵,我们假设在强化学习框架中训练此类策略的一个关键困难是探索问题状态空间的困难,因为该空间的可访问区域沿着高维空间的流形形成了复杂的结构,我们使用两个版本的非完整快速探索随机树算法:第一个版本更通用,但需要显式使用环境的转换函数,而第二个版本则使用特定于操作的运动学约束来获得更好的采样效率。我们都使用通过基于采样的探索发现的状态来生成重置分布,从而通过无模型强化学习在完全动态约束下启用训练控制策略。
-
Cherry-Picking with Reinforcement Learning:抓取被不稳定或非刚性材料包围的小物体在手术、收割、建筑、灾难恢复和辅助喂养等应用中发挥着至关重要的作用。为了克服建立准确的接触和动力学模型的困难,强化学习 (RL) 等数据驱动方法可以通过反复试验来优化任务性能,从而减少对准确的接触和动力学模型的需求。然而,将强化学习方法应用于真实机器人却受到一些因素的阻碍,例如过高的样本复杂性或在硬件上提供重置所需的高训练基础设施成本。这项工作提出了 CherryBot,这是一种 RL 系统,它使用筷子进行精细操作,在某些动态抓取任务中超越了人类的反应。通过集成不精确的模拟器、次优演示和外部状态估计,我们研究如何使现实世界的机器人学习系统样本高效且通用,同时减少监督所需的人力。
-
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators:该系统应用于大规模的现实世界任务:对办公楼中的可回收物和垃圾进行分类。我们的系统将来自现实世界数据的可扩展深度 RL 与来自模拟训练的引导相结合,并结合了来自现有计算机视觉系统的辅助输入,作为促进对新颖对象的泛化的一种方式,同时保留了端到端的优势结束训练。提出了大规模的实证验证,其中包括对在 24 个月的实验过程中收集的真实世界数据进行训练,这些数据涉及三栋办公楼的 23 台机器人,其中总共9527小时的机器人经验训练集。
-
Demonstrating Large-Scale Package Manipulation via Learned Metrics of Pick Success:本文演示了 Amazon Robotics 机器人感应 (Robin) 车队中非结构化堆垛的大规模包裹操作,该车队利用了根据实际生产数据训练的拣选成功预测器。具体来说,该系统接受了超过 394K 的选秀训练。它每天用于分离多达 5~000 万个包裹。开发的学习选择质量度量实时对各种选择替代方案进行排名,并优先考虑最有希望执行的选择。拾取成功预测器旨在根据先前的经验估计部署的工业机器人手臂在包含具有部分已知属性的可变形和刚性物体的杂乱场景中进行所需拾取的成功概率。它是一种浅层机器学习模型,使我们能够评估哪些特征对于预测最重要。这种学习的排名过程被证明可以克服手动设计和启发式替代方案的局限性并超越其性能。据作者所知,本文首次在实际生产系统中大规模部署了学习的拣选质量估计方法。
-
Demonstrating Large Language Models on Robots(Nominated for Best Demo Paper):该演示包括几个基于最新方法的系统,这些系统将LLMs集成到机器人上:SayCan, Socratic Models, Inner Monologue, and Code as Policies。这种结构为演示提供了一些实用的好处,因为(i)我们可以使用现有的视频聊天界面通过输入命令并通过视频流广播其动作来指导机器人,(ii)人们可以在与不同的界面进行通信的界面之间无缝切换。 (iii) 这一切都可以在笔记本电脑上远程完成,真正硬件上的机器人可以在实验室中处于待命状态,准备按照命令运行
Large Data and Vision-Language Models for Robotics
-
RT-1: Robotics Transformer for Real-World Control at Scale
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion:本文介绍了扩散策略,这是一种通过将机器人的视觉运动策略表示为条件去噪扩散过程来生成机器人行为的新方法。扩散策略学习动作分布的得分函数,并在推理过程中通过一系列随机Langevin动力学步骤迭代优化该梯度场。我们发现扩散公式在用于机器人策略时具有强大的优势,包括优雅地处理多模态动作分布、适用于高维动作空间以及表现出令人印象深刻的训练稳定性。本文提出了一系列关键技术贡献,包括the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer。
- Scaling Robot Learning with Semantically Imagined Experience:最新进展显示出使机器人能够执行各种操作任务并推广到新场景的希望。这一进展的关键因素之一是用于训练模型的机器人数据的规模。为了获得大规模数据集,先前的方法要么依赖于需要高度人类参与的演示,要么依赖于工程量大的自主数据收集方案。为了缓解这个问题,我们建议采取另一种途径,利用计算机视觉和自然语言处理中广泛使用的文本到图像基础模型来获取用于机器人学习的有意义的数据,而不需要额外的机器人数据。我们利用最先进的文本到图像扩散模型,并通过纯文本指导修复各种看不见的操作对象、背景和干扰物,在现有的机器人操作数据集之上执行积极的数据增强。通过广泛的现实世界实验,我们表明,在增强数据上训练的操纵策略能够使用新对象解决完全未见过的任务,并且可以表现得更加鲁棒
-
Goal-Conditioned Imitation Learning using Score-based Diffusion Policies:提出了一种新的基于分数扩散模型的策略表示方法。我们将新的策略表示方法应用于目标条件模仿学习(GCIL)领域,从大数据集中无奖赏地学习通用的目标指定策略。我们的新的目标条件策略结构(BESO)利用一个生成性的基于分数的扩散模型作为其策略。此外,BESO将分数模型的学习与推理采样过程分离,从而允许快速采样策略在仅3个推理步骤中生成目标指定的行为,而其他基于扩散的策略的推理步骤为30多个步骤。BESO不依赖于复杂的分层策略或额外的聚类来进行有效的目标条件化行为学习。最后,BESO具有较强的表现力,能够有效地捕捉游戏数据解空间中的多通道。Goal Conditioned Imitation Learning using Score-based Diffusion Policies (intuitive-robots.github.io)
-
Robotic Skill Acquisition via Instruction Augmentation with Vision-Language Models:大规模的预训练视觉语言模型(像 CLIP 或 ViLD 这样的 VLM)已应用于机器人技术,用于学习表示和场景描述符。这些预训练模型能否充当机器人数据的自动标记器,有效地将互联网规模的知识导入到现有数据集中,例如,如果原始注释包含简单的任务描述,例如“拿起苹果”,则基于 VLM 的预训练标记器可以显着扩展数据中可用的语义概念的数量,并引入空间概念。为了实现这一目标,我们引入了语言条件控制的数据驱动指令增强(DIAL):我们利用半监督语言标签,利用 CLIP 的语义理解来将知识传播到未标记演示数据的大型数据集上,然后在增强的数据集上训练语言条件策略。与昂贵的人工标签相比,这种方法可以更便宜地获取有用的语言描述,从而可以更有效地覆盖大规模数据集。我们发现 DIAL 使模仿学习策略能够获得新的能力并泛化到 60 个新颖的能力原始数据集中未见的指令
-
Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement:我们这项工作的重点是一个可指导的场景重新排列框架,该框架可推广到训练时从未见过的较长指令和空间概念组合。我们建议用相对对象排列的能量函数来表示语言指导的空间概念。语言解析器将指令映射到相应的能量函数。我们展示了我们的模型可以在模拟和现实世界中零次执行高度组合指令。它大大优于语言到动作反应策略和大型语言模型规划器,特别是用于涉及多个空间概念的组合的长指令。https://ebmplanner.github.io
-
StructDiffusion: Language-Guided Creation of Physically-Valid Structures using Unseen Objects:在人类环境中运行的机器人必须能够将物体重新排列成语义上有意义的配置,即使这些物体以前是看不见的。在这项工作中,我们重点关注在没有逐步说明的情况下构建物理有效结构的问题。我们提出了 StructDiffusion,它结合了扩散模型和以对象为中心的transformer来构造给定部分点云和高级语言目标(例如“布置桌面”)的结构。我们的方法可以使用一个模型执行多个具有挑战性的语言条件多步骤 3D 规划任务。与在特定结构上训练的现有多模态 Transformer 模型相比,StructDiffusion 甚至可以将看不见的物体组装物理有效结构的成功率平均提高 16%
-
Language-Driven Representation Learning for Robotics(Nominated for Best Paper):我们介绍 Voltron,这是一个从人类视频和相关字幕中进行语言驱动表示学习的框架。 Voltron 权衡了以语言为条件的视觉重建来学习低级视觉模式,以及以视觉为基础的语言生成来编码高级语义。我们还构建了一个新的评估套件,涵盖五个不同的机器人学习问题
Simulation and Sim2Real
-
Local object crop collision network for efficient simulation of non-convex objects in GPU-based simulators:开发一种高效的接触检测算法,用于基于GPU的大规模非凸对象模拟。我们的方法将现有CD方法的效率提高了5-10倍。
-
GranularGym: High Performance Simulation for Robotic Tasks with Granular Materials:我们提出了一套在图形处理单元(GPU)上快速模拟颗粒材料的方法和系统,并表明这种模拟足够快,可以使用强化学习算法进行基本训练,目前需要许多动力学样本才能获得可接受的性能
-
Beyond Flat GelSight Sensors: Simulation of Optical Tactile Sensors of Complex Morphologies for Sim2Real Learning:我们扩展了先前提出的针对平面传感器开发的 GelSight 模拟方法,并提出了一种针对弯曲传感器的新颖方法。特别是,我们模拟了光线以测地线路径的形式穿过弯曲的触觉膜。通过模拟指形 GelTip 传感器并将生成的合成触觉图像与相应的真实图像进行比较,对该方法进行了验证。
-
Rotating without Seeing: Towards In-hand Dexterity through Touch:在本文中,我们建议仅使用触摸来执行手中的对象旋转,而无需看到对象。我们引入了一种新的系统设计,使用覆盖整个机器人手(手掌、手指链接、指尖)一侧的密集二元力传感器(触摸或无触摸),而不是依赖于小区域内的精确触觉传感。
-
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training:使用并行 GPU 加速物理模拟器 (Isaac Gym),我们为这些机器人实施具有挑战性的任务,包括重新抓取、抓取和投掷以及对象重新定向。为了解决这些问题,我们引入了一种去中心化的基于群体的训练(PBT)算法,该算法使我们能够大规模增强深度强化学习的探索能力。我们发现这种方法明显优于常规的端到端学习,并且能够在具有挑战性的任务中发现稳健的控制策略。
-
Hindsight States: Blending Sim & Real Task Elements for Efficient Reinforcement Learning:在这里,我们利用动态复杂性的不平衡来更有效地学习样本。我们(i)将任务抽象为不同的组件,(ii)将简单的动力学部分卸载到模拟中,以及(iii)将这些虚拟部分相乘以在事后生成更多数据。我们的新方法,后见之明状态(HiS),使用这些数据并选择最有用的转换进行训练。它可以与任意离策略算法一起使用。我们在几个具有挑战性的模拟任务上验证了我们的方法,并证明它可以单独提高学习效果
-
IndustReal: Transferring Contact-Rich Assembly Tasks from Simulation to Reality:我们推出了 IndustReal,这是一套算法、系统和工具,可通过强化学习 (RL) 解决模拟中的装配任务,并成功实现策略向现实世界的转移。具体来说,我们建议 1) 模拟感知策略更新,2) 符号距离场奖励,3) 机器人强化学习代理基于采样的课程。我们使用这些算法使机器人能够在模拟中解决接触丰富的拾取、放置和插入任务。
-
SAM-RL: Sensing-Aware Model-Based Reinforcement Learning via Differentiable Physics-Based Simulation and Rendering(Nominated for Best System Paper):基于模型的强化学习 (MBRL) 如何从原始感官输入(例如图像)自动高效地开发准确的模型,特别是对于复杂的环境和任务,是一个具有挑战性的问题,我们提出了一种基于感知感知模型的强化学习系统,称为 SAM-RL。利用基于物理的可微分模拟和渲染,SAM-RL 通过将渲染图像与真实原始图像进行比较来自动更新模型,并有效地生成策略。SAM-RL 允许机器人选择信息丰富的视角来监控任务过程:https://sites.google.com/view/rss-sam-rl
Grasping and Manipulation
-
FurnitureBench: Reproducible Real-World Benchmark for Long-Horizon Complex Manipulation:为了使自主机器人能够实现更复杂的长视野行为,我们建议重点关注现实世界的家具组装,这是一项复杂的长视野机器人操纵任务,需要解决当前的许多机器人操纵挑战。我们推出 FurnitureBench,这是一种可重现的现实世界家具组装基准,旨在提供较低的进入门槛并易于重现,以便世界各地的研究人员能够可靠地测试他们的算法并将其与之前的工作进行比较。
-
Learning-Free Grasping of Unknown Objects Using Hidden Superquadrics:最近,随着机器学习的重大进展,数据驱动的方法在该领域占据主导地位。尽管已经取得了令人印象深刻的改进,但这些方法需要大量的训练数据,并且通用性有限。在本文中,我们提出了一种新颖的两阶段方法,可以直接从对象的点云预测和合成抓取姿势,而无需数据库知识或学习。首先,在物体内的不同位置恢复多个超二次曲面,代表物体表面的局部几何特征。随后,我们的算法利用超二次曲面的三对称特征,并从每个恢复的超二次曲面合成对映掌握列表。评估模型旨在评估和量化每个掌握候选者的质量。然后选择得分最高的抓取候选者作为最终抓取姿势。
-
Uncertain Pose Estimation during Contact Tasks using Differentiable Contact Features:对于许多机器人操纵和接触任务,准确估计不确定的物体姿态至关重要,之前针对该问题的结果主要采用基于采样或端到端的学习方法,但往往存在效率和泛化性问题。在本文中,我们针对接触过程中的不确定姿态估计提出了一种新颖的可微分框架,以便可以使用基于梯度的求解器以高效且准确的方式对其进行求解。为了实现这一目标,我们引入了一种新的几何定义,该定义具有高度适应性并能够提供可微分的接触特征。然后,我们从双层角度处理问题,并利用这些接触特征的梯度以及可微优化来有效地解决不确定的姿态。
-
Simultaneous Trajectory Optimization and Contact Selection for Multi-Modal Manipulation Planning:复杂的灵巧操作需要在可抓握和不可抓握之间切换,以及相对于环境滑动和旋转物体。本文提出了一种操作规划器,它能够推理联系人的各种变化以发现此类计划。它实现了一种混合方法,该方法对旋转和滑动操作基元执行接触隐式轨迹优化,并基于采样进行规划以在操作基元和目标对象姿势之间进行更改。该优化方法,同步轨迹优化和接触选择(STOCS),引入了无限编程框架,可以在操作基元期间动态选择对象与环境之间的接触点和支撑力。
-
Precise Object Sliding with Top Contact via Asymmetric Dual Limit Surfaces:在本文中,我们讨论了通过与顶面的摩擦贴片接触来使物体在水平平面上滑动的力学和规划算法。在这里,我们提出了一个非对称双极限表面模型来确定顶部和底部接触的滑移边界条件。通过该模型,我们获得了一系列扭曲,可以使物体在支撑平面上滑动时与机器人末端执行器保持粘着接触。基于这些约束,我们推导了一种规划算法,可以将仅顶部接触的物体滑动到任意目标姿势,而末端执行器和物体之间不会发生滑动。
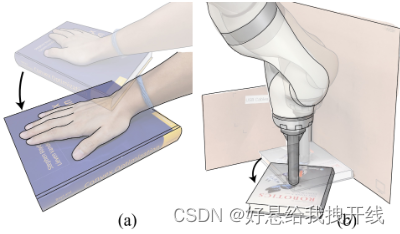
-
RoboNinja: Learning an Adaptive Cutting Policy for Multi-Material Objects:oboNinja,这是一种基于学习的多材料物体切割系统(即具有刚性核心的软物体,如鳄梨或芒果)。与之前使用开环切割动作来切割单一材料物体(例如切片黄瓜)的作品相比,RoboNinja 的目标是去除物体的柔软部分,同时保留刚性核心,从而最大限度地提高产量。我们的系统通过利用交互式状态估计器和自适应切割策略来关闭感知-行动循环。该系统首先利用稀疏碰撞信息迭代地估计物体核心的位置和几何形状,然后根据估计的状态和公差值生成闭环切割动作。策略的“自适应”是通过容差值来实现的,它在遇到碰撞时调节策略的保守性,与估计的核心保持自适应安全距离。

-
Dynamic-Resolution Model Learning for Object Pile Manipulation:从视觉观察中学习到的动力学模型已被证明在各种机器人操作任务中是有效的。学习此类动力学模型的关键问题之一是使用什么场景表示。先前的工作通常假设以固定维度或分辨率表示,这对于简单任务可能效率低下,对于更复杂的任务则无效。在这项工作中,我们研究如何学习不同抽象级别的动态和自适应表示,以实现效率和有效性之间的最佳权衡。我们构建环境的动态分辨率粒子表示,并使用允许连续选择抽象级别的图神经网络(GNN)学习统一的动力学模型。在测试期间,代理可以自适应地确定每个模型预测控制(MPC)步骤的最佳分辨率。
-
Few-shot Adaptation for Manipulating Granular Materials Under Domain Shift:本文提出了一种自适应铲取策略,该策略使用经过元学习训练的深度高斯过程方法,从目标地形上非常有限的经验中进行在线学习。它引入了一种新颖的元训练方法,即具有受控部署间隙的深度元学习(CoDeGa),该方法显式训练深度内核以在大域变化下稳健地预测舀量。采用贝叶斯优化顺序决策框架,所提出的方法允许机器人使用视觉和很少的在线经验在分布外的地形上实现高质量的铲斗动作,显着优于 中提出的非自适应方法。
Mobile Manipulation and Locomotion
-
Causal Policy Gradient for Whole-Body Mobile Manipulation:由于机器人的动作空间大以及任务常见的多目标性质(例如,在避开障碍物的同时有效地达到目标),mobile manipulation MoMa 任务非常困难。目前的方法通常通过手动将部分动作空间与 MoMa 子目标匹配(例如,用于运动目标的基本动作和用于操纵的手臂动作),将任务分为无操纵的导航和无运动的固定操纵。我们介绍了 Causal MoMa,这是一种用于训练典型 MoMa 任务策略的新框架,该框架利用机器人动作空间中最有利的子空间来解决每个子目标。因果 MoMa 自动发现奖励函数的动作和项之间的因果依赖性,并在因果策略学习过程中利用这些依赖性,与之前最先进的策略梯度算法相比,该过程减少了梯度方差,从而提高了收敛性和结果。https://sites.google.com/view/causal-moma
-
Centralized Model Predictive Control for Collaborative Loco-Manipulation:将腿式机器人文献中开发的模型预测控制方法扩展到协作局部操纵设置。我们研究的系统需要由多个配备机械臂的四足机器人共同携带有效负载。我们使用直接多重射击方法来解决由此产生的地面反作用力、操纵扳手和步进位置轨迹的高维最优控制问题。为了捕捉系统的主要动态,我们将每个代理和共享有效负载建模为单个刚体。
-
Learning and Adapting Agile Locomotion Skills by Transferring Experience:对这些高维、欠驱动系统的探索仍然是腿式机器人学习高性能、自然和多功能敏捷技能的一个重大障碍。我们提出了一个框架,通过将现有控制器的经验转移到快速学习新任务来训练复杂的机器人技能。为了利用我们在实践中可以获得的控制器,我们将这个框架设计得在源方面是灵活的。我们表明,我们的方法能够学习复杂的敏捷跳跃行为,在后腿行走时导航到目标位置,并适应新环境
-
Robust and Versatile Bipedal Jumping Control through Reinforcement Learning:我们提出了一个强化学习框架,用于训练机器人完成各种跳跃任务,例如跳跃到不同的位置和方向。为了提高这些挑战性任务的性能,我们开发了一种新的策略结构,对机器人的长期输入/输出 (I/O) 历史记录进行编码,同时还提供对短期 I/O 历史记录的直接访问。为了训练多功能的跳跃策略,我们采用多阶段训练方案,其中包括针对不同目标的不同训练阶段。经过多阶段训练后,该策略可以直接转移到真正的双足 Cassie 机器人上。
-
On discrete symmetries of robotics systems: A group-theoretic and data-driven analysis:我们对动力系统的离散形态对称性进行了全面的研究,这种对称性在生物和人工运动系统中很常见,例如有腿、游泳和飞行的动物/机器人/虚拟角色。这些对称性源于系统形态中存在一个或多个对称平面/轴,从而导致身体部位的和谐复制和分布。我们描述了形态对称性如何扩展到系统动力学、最优控制策略以及与系统动力学演化相关的所有本体感受和外感受测量中的对称性。在数据驱动方法的背景下,对称性代表了一种归纳偏差,证明了使用数据增强或对称函数逼近器的合理性。
-
Fast Traversability Estimation for Wild Visual Navigation:森林和草原等自然环境对机器人导航来说是一个挑战,因为人们会对高草、树枝或灌木丛中的刚性障碍物产生错误的感知。在这项工作中,我们提出了 Wild Visual Navigation (WVN)这是一种仅使用视觉进行可遍历性估计的在线自监督学习系统。该系统能够不断适应现场短暂的人类演示。它利用self-supervised visual transformer models的高维特征,以及在机器人上实时运行的监督生成在线方案
-
Demonstrating Mobile Manipulation in the Wild: A Metrics-Driven Approach(Nominated for Best Demo Paper):我们展示了我们的通用移动操纵系统,由定制机器人平台和涵盖感知和规划的关键算法组成。为了在野外广泛测试系统并对其性能进行基准测试,我们选择了在真实的、未经修改的杂货店中进行杂货购物的场景。我们从为期 18 个月、为期六周的现场测试中收集的详细机器人日志数据中得出关键性能指标。这些客观指标是从复杂但可重复的测试中获得的,它们推动了我们研究工作的方向,并让我们不断改进系统的性能。我们发现,对复杂的移动操纵系统进行彻底的端到端系统级测试可以作为机器人技术中最先进方法的现实检验。
-
Demonstrating A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning:我们证明了机器学习算法和库的最新进展与仔细的 MDP 公式相结合,可以在现实世界中仅用 20 分钟就可以学习四足动物的运动。
Robot Planning
-
Non-Euclidean Motion Planning with Graphs of Geodesically-Convex Sets(Nominated for Best Paper):计算高维系统的最佳无碰撞轨迹是一个具有挑战性的问题。基于采样的规划器与维数作斗争,而轨迹优化器可能由于优化环境中固有的非凸性而陷入局部最小值。在本文中,我们通过将配置空间建模为黎曼流形来处理此类场景,并描述了零曲率情况到混合整数凸优化问题的简化过程。
-
Convex Geometric Motion Planning on Lie Groups via Moment Relaxation(Nominated for Best Paper):本文报告了一项新颖的结果:利用矩阵李群上的适当机器人模型,可以将刚体系统的运动动力学运动规划问题表述为精确的多项式优化问题,并可以将其简化为半定规划(SDP)。由于非线性刚体动力学,刚体系统的运动规划问题是非凸的。现有的基于全局优化的方法不能正确处理3D刚体的配置空间;因此,它们不能很好地解决长期规划问题。我们在公式中使用李群作为配置空间,并应用变分积分器将强制刚体系统公式化为二次多项式。然后我们利用 Lasserre 层次结构通过 SDP 获得全局最优解。通过以稀疏方式构造运动规划问题,结果表明所提出的算法相对于规划范围具有线性复杂度。
Robot State Estimation
-
ConceptFusion: Open-set multimodal 3D mapping:大多数将语义概念与 3D 地图集成的现有方法在很大程度上仍然局限于封闭集设置:它们只能推理在训练时预先定义的有限概念集。为了解决这个问题,我们提出了 ConceptFusion,这是一种场景表示:(i) 本质上是开放集,能够超越封闭的概念集进行推理 (ii) 本质上是多模态的,能够对 3D 地图进行各种可能的查询,从语言、到图像、到音频、到 3D 几何,所有这些都协同工作。 ConceptFusion 利用当今基础模型的开放集功能,这些模型已在互联网规模的数据上进行了预训练,可以跨自然语言、图像和音频等模态推理概念。我们证明了像素对齐的开放集特征可以通过传统的 SLAM 和多视图融合方法融合到 3D 地图中。这可以实现有效的零样本空间推理,不需要任何额外的训练或微调,并且比监督方法更好地保留长尾概念,在 3D IoU 上比它们高出 40% 以上
Robot Perception
-
CoDEPS: Online Continual Learning for Depth Estimation and Panoptic Segmentation:最理想的是,机器人能够在没有人类监督的情况下自行适应新的条件,例如,自动调整其感知系统以适应不断变化的照明条件。在这项工作中,我们以在线方式解决新环境中基于深度学习的单目深度估计和全景分割的持续学习任务。我们引入 CoDEPS 来执行涉及多个现实世界领域的持续学习,同时通过利用经验回放来减轻灾难性遗忘。特别是,我们提出了一种新颖的域混合策略来生成伪标签以适应全景分割。此外,我们通过利用采样策略来构建基于稀有语义类采样和图像多样性的固定大小重播缓冲区,明确解决了机器人系统的有限存储容量。
-
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory:我们提出了 CLIP-Fields,这是一种隐式场景模型,可用于各种任务,例如分割、实例识别、空间语义搜索和视图定位。 CLIP-Fields 学习从空间位置到语义嵌入向量的映射。重要的是,我们表明,这种映射可以仅通过来自网络图像和网络文本训练模型(例如 CLIP、Detic 和 Sentence-BERT)的监督进行训练;因此不使用直接的人类监督。与 Mask-RCNN 等基线相比,我们的方法在 HM3D 数据集上的少样本实例识别或语义分割(仅包含一小部分示例)方面表现出色。最后,我们展示了使用 CLIP-Fields 作为场景记忆,机器人可以在现实环境中执行语义导航。CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
-
How To Not Train Your Dragon: Training-free Embodied Object Goal Navigation with Semantic Frontiers:对象目标导航是嵌入式人工智能中的一个重要问题,涉及引导代理在未知环境(通常是室内场景)中导航到对象类别的实例。不幸的是,当前解决这个问题的最先进方法严重依赖于数据驱动的方法,例如端到端强化学习、模仿学习等。我们提出了一种模块化且免训练的解决方案,其中包含更多经典方法,以解决对象目标导航问题。我们的方法基于经典的视觉同步定位和建图(V-SLAM)框架构建结构化场景表示。然后,我们将语义注入基于几何的前沿探索中,以推理有希望的区域来搜索目标对象。我们的结构化场景表示包括 2D 占用图、语义点云和空间场景图。我们的方法基于语言先验和场景统计在场景图上传播语义,以将语义知识引入几何边界。通过注入语义先验,代理可以推理出最有希望探索的前沿。
-
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training:现实世界的机器人应用需要能够在各种场景下可靠工作的物体姿态估计方法。现代基于学习的方法需要大量标记数据集,并且在训练领域之外往往表现不佳。我们的第一个贡献是开发一个强大的校正器模块,使用深度信息校正姿势估计,从而使现有方法能够更好地推广到新的测试领域;校正器对语义关键点进行操作(但也适用于其他姿势估计器)并且是完全可微分的。我们的第二个贡献是一种集成自我训练方法,它以自我监督的方式同时训练多个姿势估计器。我们的集成自训练架构使用鲁棒校正器来细化每个姿态估计器的输出;然后,它使用可观察的正确性证书评估输出的质量;最后,它使用可观察到的正确输出进行进一步训练,而不需要外部监督。
-
CHSEL: Producing Diverse Plausible Pose Estimates from Contact and Free Space Data:我们研究如何根据接触产生的力和触觉数据来估计姿势。使用从接触中获得的数据具有挑战性,因为它本质上比视觉数据的信息密度要低,因此当接触很少时,姿势估计问题严重受限。我们不是试图估计物体的真实姿态(如果没有大量接触就难以处理),而是寻求估计一组遵循传感器数据施加的约束的合理姿态。我们解决这个问题的方法是约束姿态假设集消除(CHSEL),具有三个关键属性:1)它考虑体积信息,这使我们能够考虑已知的自由空间; 2)它使用新颖的可微分体积成本函数来利用强大的基于梯度的优化工具; 3) 它使用质量多样性 (QD) 优化文献中的方法来生成一组多样化的高质量姿势。
-
MultiSCOPE: Disambiguating In-Hand Object Poses with Proprioception and Tactile Feedback:在本文中,我们提出了一种使用双手机器人系统的本体感觉和触觉反馈来估计手中物体姿势的方法。我们的方法解决了通过抓取物体之间的一系列摩擦接触相互作用来减少姿态不确定性的问题。作为我们方法的一部分,我们提出 1) 一种有助于接触位置和物体姿态估计的工具分割例程,2) 允许对交互之间的解决方案一致性进行推理的损失,以及 3) 促进收敛到物体姿态和接触位置的损失这解释了每只手臂所经历的外力-扭矩。我们在模拟和现实世界的双手平台上的基于任务的演示中展示了我们的方法的有效性
-
Tactile-Filter: Interactive Tactile Perception for Part Mating:在本文中,我们提出了一种使用基于视觉的触觉传感器进行零件配合任务的交互式感知方法,其中机器人可以使用触觉传感器和使用粒子滤波器的反馈机制来逐步改进其对物体(钉子和孔)的估计适合在一起。为此,我们首先训练一个深度神经网络,利用触觉图像来预测组合在一起的任意形状的物体之间的概率对应关系。训练后的模型用于设计双重使用的粒子滤波器。首先,给定对孔的部分(或非唯一)观察,它通过对更多触觉观察进行采样来逐步改进正确钉子的估计。其次,它选择机器人的下一个动作来采样下一个触摸(以及图像),从而最大限度地减少不确定性,从而最大限度地减少感知任务期间的交互次数。
Robot Mechanisms & Control
-
LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning:我们提出了 LEAP Hand,这是一种用于机器学习研究的低成本灵巧且拟人化的手。与之前的手相比,LEAP Hand 具有新颖的运动结构,无论手指姿势如何,都可以实现最大的灵活性。 LEAP Hand 成本低廉,可以在 4 小时内用现成的零件组装起来,成本为 2000 美元。

-
ROSE: Rotation-based Squeezing Robotic Gripper toward Universal Handling of Objects(Nominated for Best System Paper):将软材料集成到夹具的设计中可以容忍上述不确定性并降低控制的复杂性。在本文中,我们介绍了ROSE,一种新型的软夹具,通过简单地旋转底座,将漏斗状的薄壁软膜扣在物体周围,从而拥抱并挤压物体。由于这种设计,ROSE hand 可以适应各种可能落入漏斗内的物体,并以令人愉悦的抓握力进行处理。不管怎样,ROSE 可以产生高升力(高达 328.7 N),同时显着降低所抓取物体上的法向压力。
 https://youtu.be/E1wAI09LaoY?si=zQ0pOOnOTTP-xMCp
https://youtu.be/E1wAI09LaoY?si=zQ0pOOnOTTP-xMCp

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)