

前言
我们的研发协作平台包括了应用生命周期管理、研发代码管理、云计算资源管理、流水线管理、发布交付管理、一体化监控管理、质效度量管理、智能运维管理、测试自动化管理等版图,跨越开发、测试、运维、安全多个领域,部分能力已经比较成熟,部分能力苦于资源不足暂未深入开展,这些基础技术的设施每个板块都有大量的痛点值得挖掘,建设完善的话都可以深度提升整个技术团队的研发效能和质量。
这里监控平台是我们发力比较多的一个版块,应用监控、运维监控、业务监控、安全监控陆续成熟并有序聚合,为整个技术团队提供了一套多维一体化的监控平台,价值比较明显,所以有必要先重点介绍下该平台的一些设计思路和实践。
监控平台的根本之道
每个公司或多或少都有一些自动化监控手段,在各个技术社区里也能看到大量关于监控技术的讨论。但在讨论监控系统时,大多数都是集中在单维度监控技术的讨论,针对监控体系的概念目前也几乎没有通用的术语,各个职能团队往往会专注于各自职能领域的监控,比如运维团队关注服务器和网络资源,安全团队关注网络攻防和业务风控,开发团队关注应用可用性和链路性能,测试团队更多关注业务故障和用户舆情等等。
单维度的监控平台主要反映的是单个业务或技术层面的运行状态,缺少能反应整个“业务域”上下游整体运行状况的全局视角;线上出现问题时由于各职能团队掌握的信息片面而且不共享,很多时候都需要开发/测试/运维/DBA/安全等多个团队参与排查,问题原因定位难,无法快速响应和解决故障;另外因为各监控平台都是独立建设,往往存在监控方式和标准不统一,报警讯息的格式混乱等问题。
线上出现重大故障后召集一堆人却无法有效定位到问题,或者半夜收到一堆莫名奇妙的报警短信却不知道报警来源在哪里,类似这样的问题只有经历过的技术人员才能深深体会到那份痛苦和绝望。
结论:单维度监控效果有限,多维度立体化监控才是监控平台的根本之道。
监控平台的分类和设计
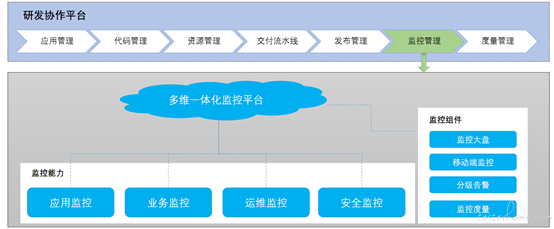
随着微服务架构与容器虚拟化技术的发展,DevOps 和敏捷文化已经深入人心,开发、测试和运维等职能团队的边界逐渐被淡化并打通。在监控领域复用各维度的监控资产实现信息共享,构建多维监控一体化平台,实现开发、测试、生产运维阶段的全生命监测管理,是 DevOps 研发协作平台建设的重要组成部分。
依照监控层次的维度,监管管理平台的监控能力大致分为几类:
应用层面的监控
• 监控范围:包括服务的可用性、请求量、链路状态等,APP 端的 Crash 率 / 卡顿等
• 核心技术:接口 / 页面拨测、分布式链路分析、客户端 APM
运维层面的监控
• 监控范围:包括主机资源、网络吞吐的情况,以及服务器上的各类中间件运行状况等
• 核心技术:Zabbix、Prometheus、Grafana 等
业务层面的监控
• 监控范围:包括核心的业务指标,用户行为,以及用户舆情等
• 核心技术:大数据采集、大数据分析
安全层面的监控
• 监控范围:如安全态势感知,用户行为风控等
• 核心技术:威胁情报、入侵检测、大数据风控等
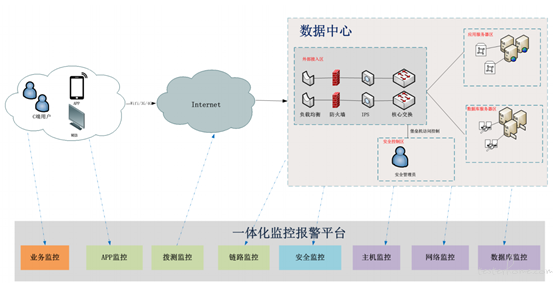
监控平台研发实践
各个维度的监控能力采用不同的技术栈研发,构建一套一体化的监控平台上并不是生硬的聚合,关键是要需要依据统一的监控标准抽象出公共能力。
通过一些公共的监控组件,我们实现了监控标准和报警方式的统一;提供了公共的监控大盘页(包括移动端页面),核心的监控指标以及告警讯息在一个dashboard页面直观展现;同时还提供了统一的监控度量标准,各业务应用可横向进行系统可用性对比。
• 监控大盘-一眼看尽平台健康度

• 移动端监控-在家里/在路上都可关注监控报警情况。
• 监控度量-横向系统可用性对比
• 分级告警-以应用为核心的告警机制
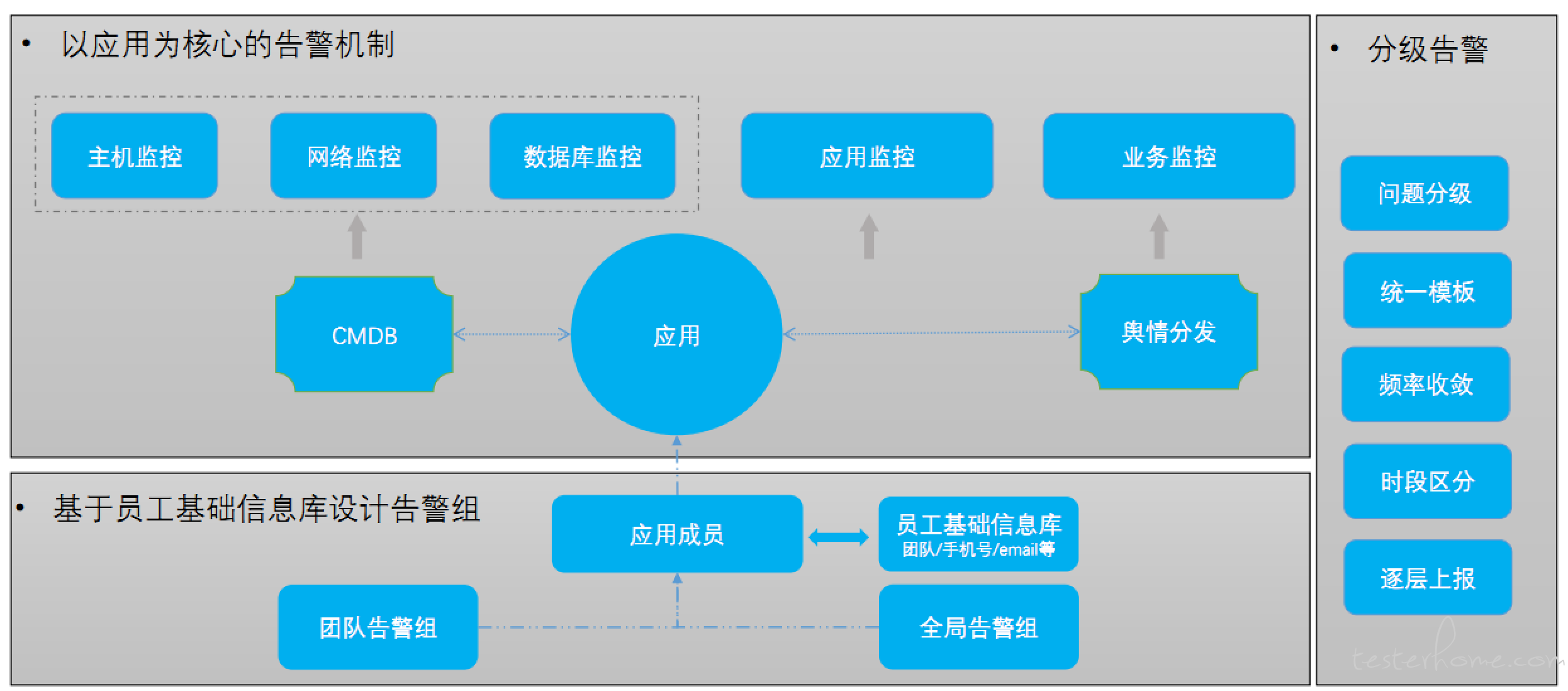
目前微医整个技术团队都使用这套一体化监控平台,每月输出1000+次的故障预警,具备了包括可用性指标、运营指标、性能指标、安全指标、基础资源指标等多维度全方位的监控能力,提供了包括短信、邮件、钉钉、微信等在内的分级告警能力,技术团队针对线上故障的预警、协同和处理能力都得到大幅度的提升。
下一步的技术发展提升方向和思路
在具备相对全面的故障监控能力以后,设计和提升系统的故障自愈能力是下一步技术发展的重点。云计算和容器技术赋予了监控平台更多的想象空间,比如在监控到某应用的资源瓶颈时,如何与云计算资源调度平台协作,利用弹性伸缩技术自动调整资源,这些都是值得进一步深入探索的领域。
另外,右侧的监控平台也可以与左侧的CI/CD平台有效集合,在发布环节依靠高度智能化的监控平台能力,有效检测对比发布前后的监控指标并科学设计发布质量门,从而提升发布交付环节的稳定性,这也是我们正在做的事情。
结语
停更比较久了,实践需要修炼,等成熟了再总结会更饱满一些,MTSC2019会尝试详细分享下该主题的实践细节。




 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)