
Python爬虫:爬取华为应用市场app数据
Python爬取华某应用市场app数据爬取华某应用商店的所有APP名称和介绍,因为页面数据是ajax异步加载的,所以要找到对应的接口去解析数据。爬取华某应用市场app数据Python爬取华某应用市场app数据一、分析网页1. 分析主页2. 分析appid3. 分析uri二、撰写爬虫三、总结一、分析网页首先分析页面1. 分析主页打开华某应用市场主页:https://appgallery.华某网址.c
爬取华为应用商店的所有APP名称和介绍,因为页面数据是ajax异步加载的,所以要找到对应的接口去解析数据。
一、分析网页
首先分析页面
1. 分析主页
打开华为应用市场主页:https://appgallery.huawei.com/#/Apps 查看网页源代码。
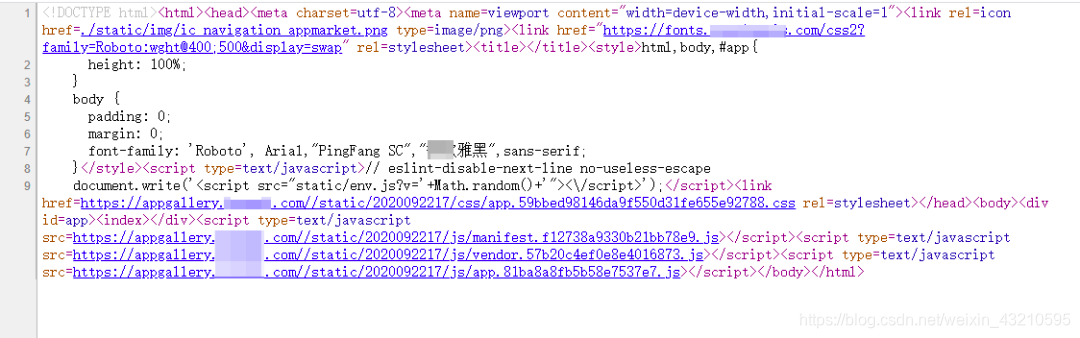
发现数据是动态Ajax异步加载渲染出来的 ,因为我们要爬取APP 名称和介绍,所以随便点开一个应用并且打开F12开发者工具,发现网页数据是由动态Ajax请求生成的数据。
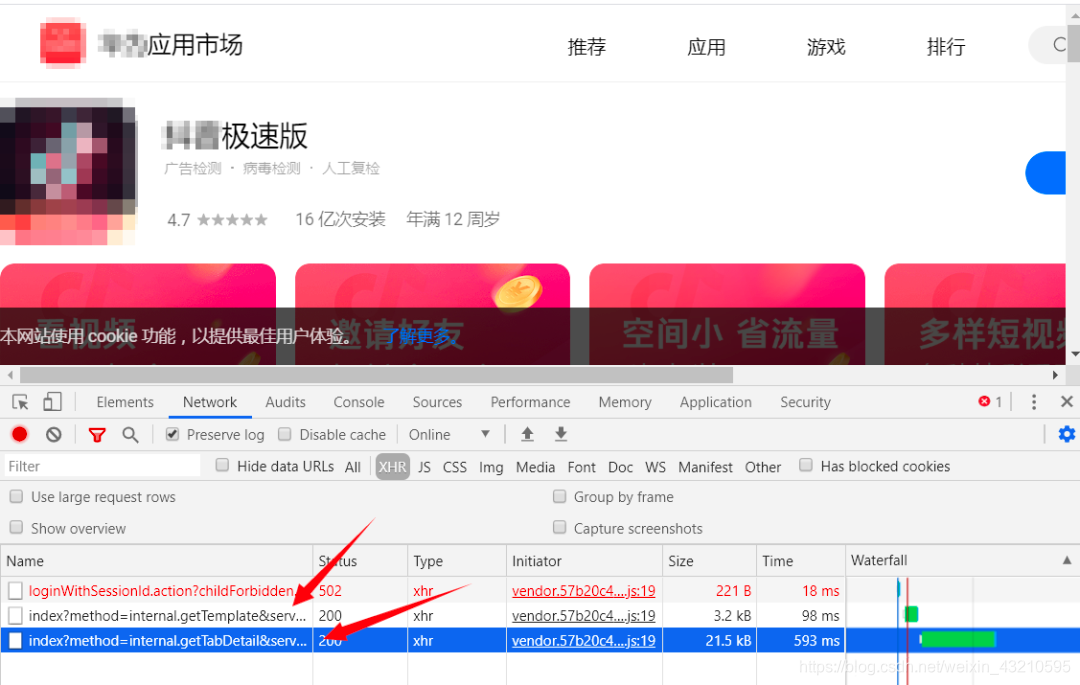
地址1:
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTemplate&serviceType=20&zone=&locale=zh_CN
地址2:
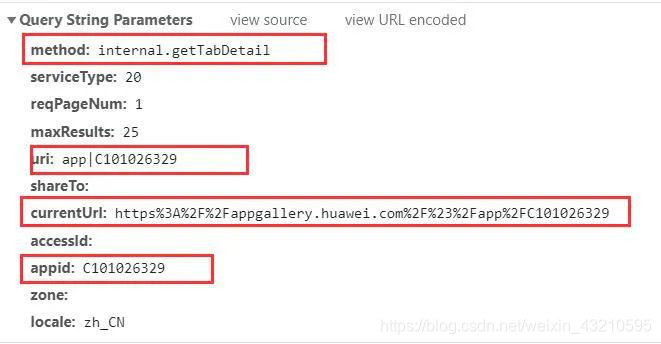
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app%7CC101026329&shareTo=¤tUrl=https%253A%252F%252Fappgallery.huawei.com%252F%2523%252Fapp%252FC101026329&accessId=&appid=C101026329&zone=&locale=zh_CN
通过对响应体分析 发现地址2中存在我们想要的数据 即app 名称和介绍他们分别在这里。
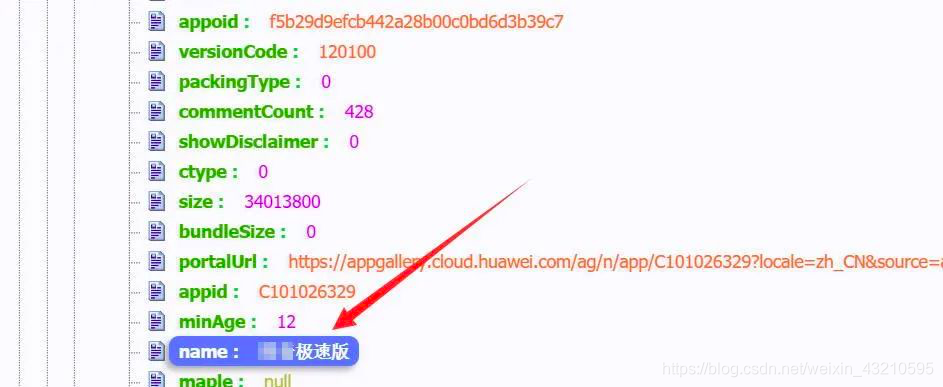
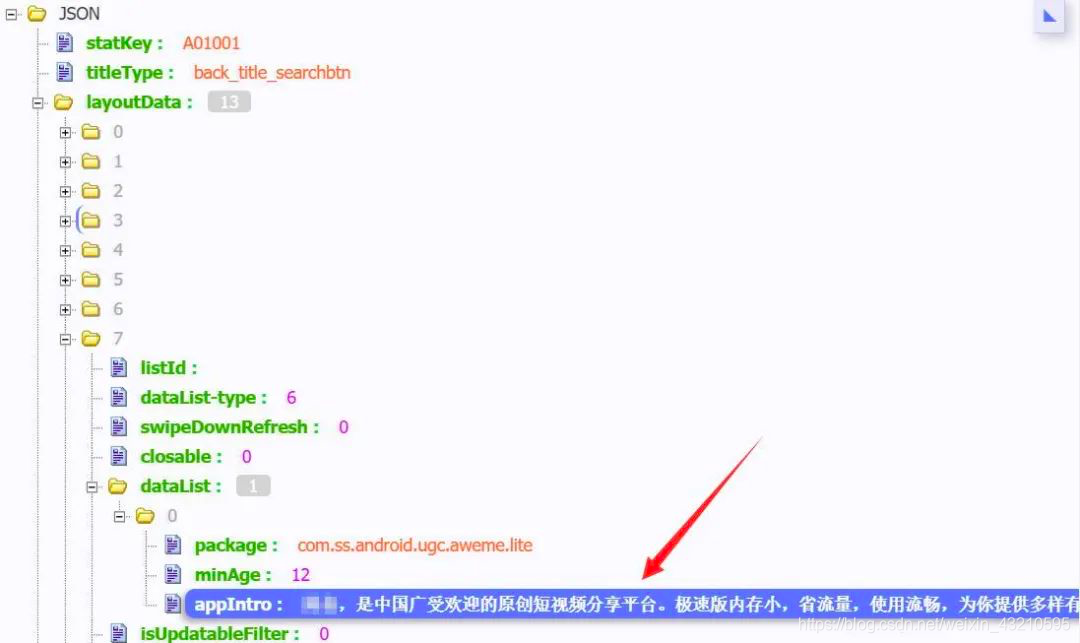
通过对地址2的分析,发现需要传这些参数,其中后三项是和appid有关的,所以为了得到地址2的链接 我们还要获取appid这一参数。
2. 分析appid
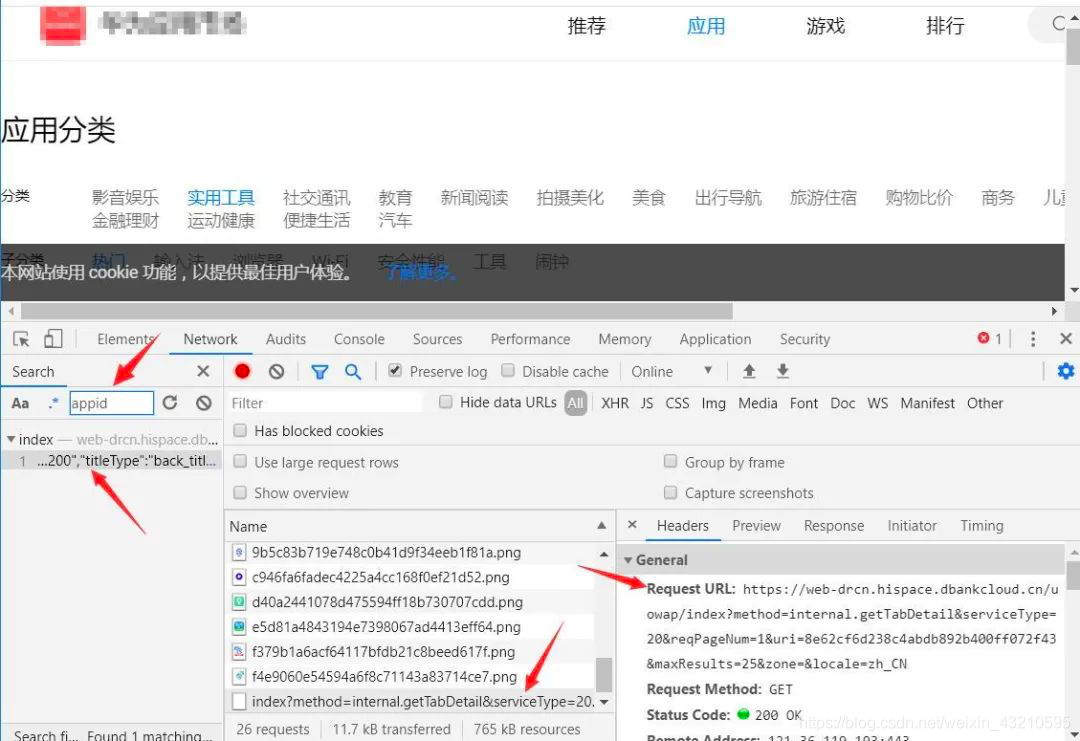
返回上一级页面 随便点击一个分类 (我点的:实用工具),发现产生了一个Ajax请求,在左侧搜索 appid 结果指向了这个地址:
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=8e62cf6d238c4abdb892b400ff072f43&maxResults=25&zone=&locale=zh_CN
我们查看这个json包 ctrl+f搜索appid 发现搜索到了24个结果。
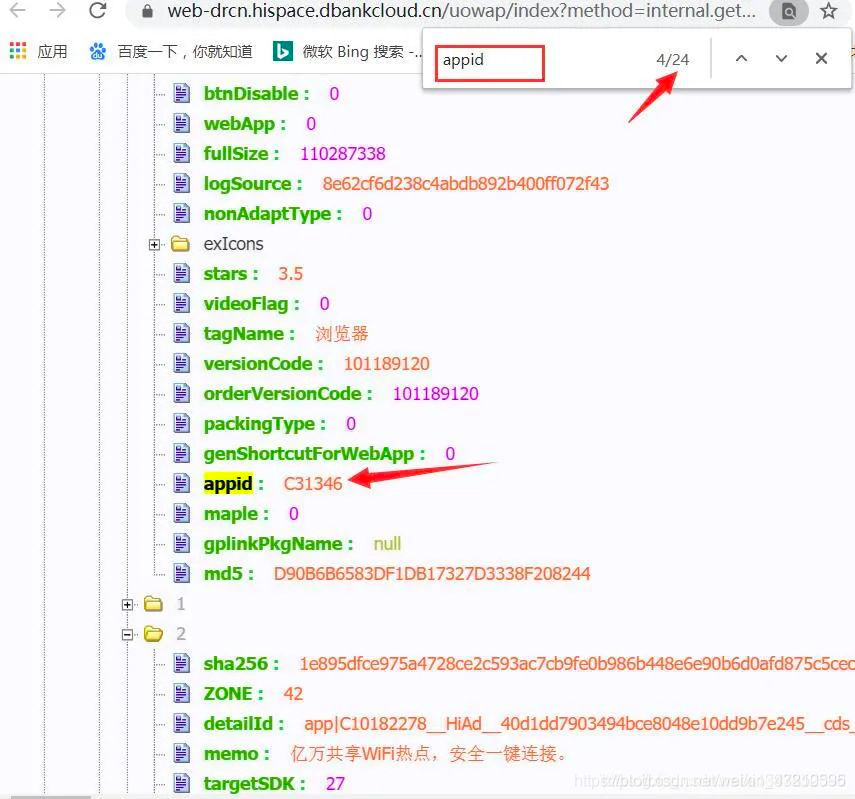
通过分析发现这个url地址关键参数是 uri,这个uri应该是子分类的标识。
3. 分析uri
回到主页面https://appgallery.huawei.com/#/Apps 刷新后搜索uri 看下。左侧得到好多结果,通过对比uri发现这个是我们要的(因为和刚才看到的的一样)。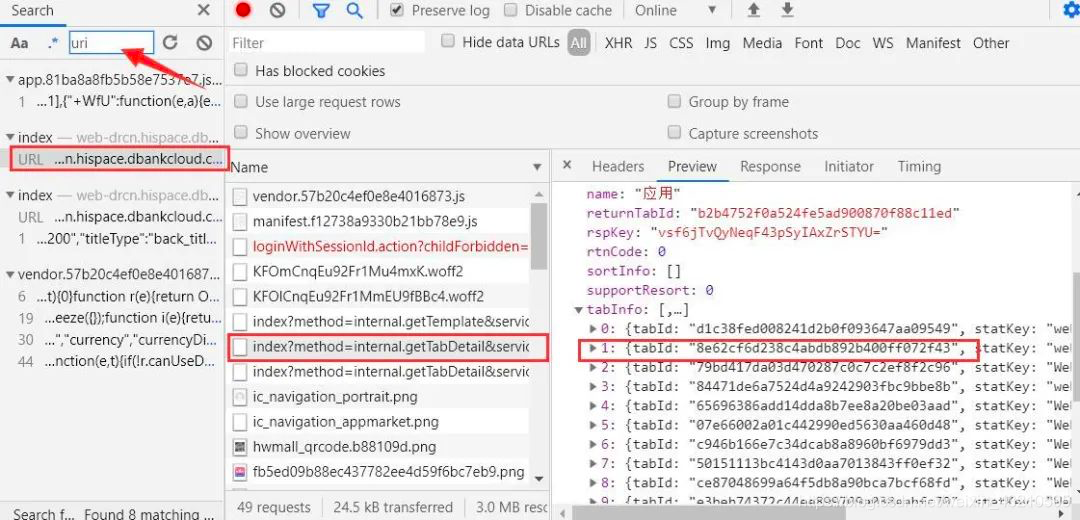
地址:
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=b2b4752f0a524fe5ad900870f88c11ed&maxResults=25&zone=&locale=zh_C
上面的json包展开之后就能看到所有子分类的uri
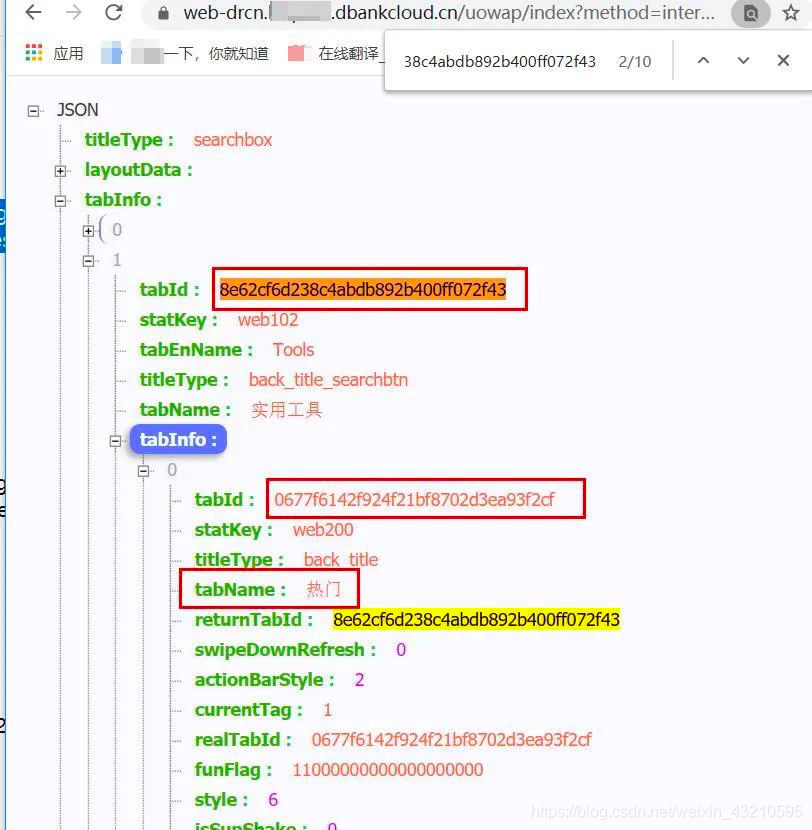 ps:这里面有个坑,所有小分类都是以 热门 开始的,只有 拍摄美化 里面没有热门,在提取uri时要注意。
ps:这里面有个坑,所有小分类都是以 热门 开始的,只有 拍摄美化 里面没有热门,在提取uri时要注意。
好,既然找到了所有分类的入口,就可以从这里开始。我们的思路就是:获取uri–>获取appid–>解析app详情页。
二、撰写爬虫
import requests
import json
import random
from concurrent.futures import ThreadPoolExecutor
class HuaWei_appPrase(object):
def __init__(self):
self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
#获取uri 即每个分类的标识
def get_uri(self):
fujia = '0b58fb4b937049739b13b6bb7c38fd53'
all_tab_uri = list()
result = list()
for i in range(2):
if i == 0:
url = 'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=b2b4752f0a524fe5ad900870f88c11ed&maxResults=25&zone=&locale=zh_CN'
else:
url = 'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=56a37d6c494545f98aace3da717845b7&maxResults=25&zone=&locale=zh_CN'
r = requests.get(url)
_json = json.loads(r.text)
data = _json.get('tabInfo')
for k in data:
tab_ids = k.get('tabInfo')
aim = tab_ids[0]
tab_id = aim.get('tabId')
result.append(tab_id)
for e in tab_ids:
tab_id1 = e.get('tabId')
if tab_id1 not in result:
all_tab_uri.append(tab_id1)
all_tab_uri.append(fujia)
return all_tab_uri
#获取每个分类里应用的appid
def get_appid(self,uri):
n=1
#死循环,当layoutData为空时,停止获取appid,即一个类别爬取结束
while True:
url=f'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum={n}&uri={uri}&maxResults=250&zone=&locale=zh_CN'
r=requests.get(url,headers=self.headers)
_json=json.loads(r.text)
data1=_json.get('layoutData')
if len(data1)!=0:
for app in data1:
datalist=app.get('dataList')
for data in datalist:
appid=data.get('appid')
yield appid
n += 1
else:
break
#解析主程序,用于解析每个app的name和introduce
def parse(self,appid):
item={}
url=f'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app%7C{appid}&shareTo=¤tUrl=https%253A%252F%252Fappgallery.huawei.com%252F%2523%252Fapp%252F{appid}&accessId=&appid={appid}&zone=&locale=zh_CN'
r=requests.get(url,headers=self.headers)
r.encoding='utf-8'
_json=json.loads(r.text)
data=_json.get('layoutData')
aim_appname=data[1]
datalist1=aim_appname.get('dataList')
for data1 in datalist1:
item['app_name']=data1.get('name')
#通过分析发现 app_intro 在dataList里面 但是有的在[6] 有的在[7],所以要加判断
flag1=data[7]
datalist=flag1.get('dataList')
for data2 in datalist:
app_intro=data2.get('appIntro')
if app_intro :
item['app_intro'] = app_intro.replace('\n','').replace('\r','').replace('\t','')
else:
flag2 = data[6]
datalist2 = flag2.get('dataList')
for data2 in datalist2:
app_intro2 = data2.get('appIntro')
item['app_intro']=app_intro2.replace('\n','').replace('\r','').replace('\t','')
#将得到的数据插入到数据 使用insert方法(先将数据转为字典类型)
data=dict(item)
print(data)
#主函数
def main():
#线程池,创建四个线程
pool=ThreadPoolExecutor(max_workers=4)
huaweiapp_prase=HuaWei_appPrase()
for uri in huaweiapp_prase.get_uri():
for appid in huaweiapp_prase.get_appid(uri):
pool.submit(huaweiapp_prase.parse,appid)
pool.shutdown()
print(f'\033[31;44m********************程序结束了********************\033[0m')
if __name__ == '__main__':
main()
三、总结
本次爬取的是华为应用商店所有app名称和介绍,此网页全部是由动态ajax异步加载后渲染生成的,重点应该在如何构造ajax请求的url,实践证明我的思路没有问题。此网站没有封ip、封设备等反爬措施,但是出于安全考虑,我还是加入了请求头。思路、代码方面有什么不足欢迎各位大佬指正、批评!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)