
基于scrapy的电商平台数据爬取与展示
PyCharm是一种PythonIDE,由JetBrains打造,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。由C语言为底层开发的,本身有许多库由C语言封装的,起初被用于数学家和科学家的数学计算,因其简洁、易学、扩展性强的特点,被广泛的使用在各个领域,比如软件开发、大数据、AI、网络编
摘要:随着大数据的发展和国家推进大数据落地的迫切需要,各行各业都必须加强两化的紧密结合,加快进入数字经济时代。如今,网购已经成为人们生活中不可分割的一部分,但面对琳琅满目的商品,人们可以直接在每家门店搜索、比较信息。例如,正面评论、负面评论和买家数量。网络爬虫的出现有效地解决了这个问题,它们可以根据人设计的规则快速获取和提取有价值的数据,并依靠计算机强大的处理能力。以更高的效率。通过分析您的在线购物活动,从每个商家那里收集所有有用的信息,并分析这些大数据,您可以直接、清晰地向您的客户展示有用的信息。
本文对电商平台上各店铺的网页进行分析,将抓取的数据与通过数据挖掘和数据分析分发的分析数据连接起来,并将分析结果返回给前台展示的京东购物数据分析系统。因此,通过分析客户对电商平台店铺的评价,获取商品的质量,帮助用户快速获取商品的大量重要信息。
关键词: Scrapy;爬虫系统 ;Python ;数据分析;爬取展示
Data crawling and display of the e-commerce platform based on Scrapy
Abstract: With the development of big data and the urgent need of the country to promote the implementation of big data, all walks of life must strengthen the close combination of the two industries to industrialization and accelerate the digital economy era.Nowadays, online shopping has become an integral part of people’s life, but faced with a wide variety of goods, people can directly search and compare information in each store.For example, positive reviews, negative reviews, and the number of buyers.The emergence of web crawlers effectively solves this problem, they can quickly acquire and extract valuable data according to the rules designed by people, and rely on the powerful processing power of computers.With a higher efficiency.By analyzing your online shopping activities, gathering all the useful information from every merchant, and analyzing this big data, you can present useful information to your customers directly and clearly.
This paper analyzes the web pages of each store on the e-commerce platform, connects the captured data with the analysis data distributed through data mining and data analysis, and returns the analysis results to the JD shopping data analysis system displayed at the front desk.Therefore, by analyzing customers’ evaluation of the e-commerce platform stores, the quality of goods is obtained, and users can quickly obtain a large amount of important information of goods.
Key words: Scrapy; crawler system; Python; data analysis; crawl display
目 录
1 绪论 1
1.1 选题背景 1
1.1.1 课题的国内外的研究现状 1
1.1.2 课题研究的必要性 3
1.2 课题研究的内容 3
2 开发软件平台介绍 4
2.1 软件平台 4
2.2 开发语言 5
2.3 运行环境和系统结构 6
3 基于Scrapy的电商平台数据爬取与展示系统总体方案 7
3.1 系统组成 7
3.2 robot协议对本设计的影响 8
3.3 爬虫 8
3.3.1 商品原理 8
3.3.2 商品流程 9
3.3.3 抓取策略 9
4 基于Scrapy的电商平台数据爬取与展示模块化设计 10
4.1 数据采集 10
4.1.1 确定待采集数据 10
4.1.2 确定采集对象及采集思路 10
4.1.3 采集准备 11
4.1.4开始采集数据 12
4.2 数据清洗与分析 17
4.2.1 清洗过程简述 17
4.2.2 可视化与分析 18
1.消费时段分析 18
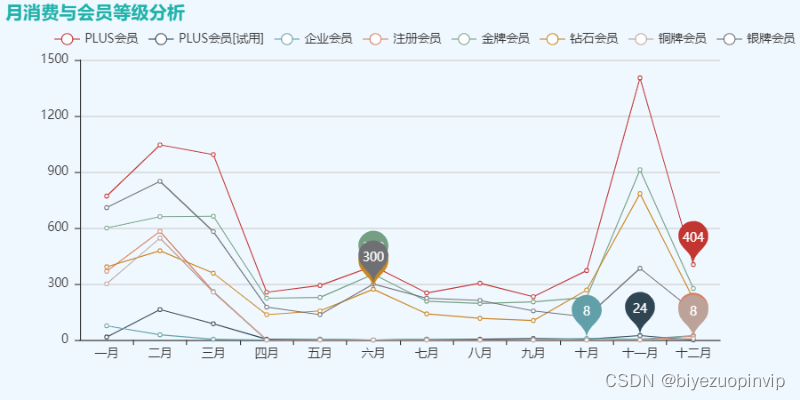
2.月消费与会员等级分析 19
3.评论内容分析 20
4.3 设计过程中存在的问题和解决过程 21
4.3.1 问题1描述 21
4.3.2 解决办法 21
4.3.3 问题2描述 22
4.3.4 解决办法: 22
4.4 心得体会 24
5 结论与发展前景 25
5.1 基于Scrapy的电商平台数据爬取与展示系统主要实现代码 25
5.2 xlsx文件 26
参考文献 27
致 谢 29
2 开发软件平台介绍
2.1 软件平台
本设计基于Pycharm软件平台。PyCharm是一种Python IDE,由JetBrains打造,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django、scarpy、pyspider等常用框架。同时支持Google App Engine,PyCharm支持IronPython。这些功能在先进代码分析程序的支持下,使 PyCharm 成为 Python 专业开发人员和刚起步人员使用的有力工具[2]。
2.2 开发语言
本设计采用的Python语言是一种计算机程序设计语言,因常被用于脚本开发也常被称为脚本语言。由C语言为底层开发的,本身有许多库由C语言封装的,起初被用于数学家和科学家的数学计算,因其简洁、易学、扩展性强的特点,被广泛的使用在各个领域,比如软件开发、大数据、AI、网络编程等。基于Scrapy的电商平台数据爬取与展示系统常用语言为Java和Python,两者均支持基于Scrapy的电商平台数据爬取与展示系统。对比之下,Python开发速度更快且支持分布式爬虫,Java对比Python运行速度较快的特点显得苍白,因此采用Python语言。
Python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。Python语言是人工智能和大数据的标准语言,随着云计算、大数据、物联网、人工智能、区块链等技术被广泛应用于各行各业。自20世纪90年代Python语言公开发布以来,由于其语法简洁、类库丰富,适用于快速开发活动,已经成为当下较为流行的一种脚本语言。Python语言具有强大的数据分析功能,可以应用到电商平台开发、图像处理、数据统计和可视化表达等多个领域。
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
2.3 运行环境和系统结构
运行环境:
2.1运行环境
•Chrome 版本 72.0.3626.109(正式版本) (64 位)
•Python 3.5.2 :: Anaconda 4.2.0 (64-bit)
2.2前置库
•json
•time
•numpy
•requests
•BeautifulSoup
•fake_useragent
系统结构:本爬虫系统分为数据爬取模块(数据)、数据分析模块(数据预处理及分析)、数据可视化模块(词云展示以及绘图展示)
本文转载自:http://www.biyezuopin.vip/onews.asp?id=16494
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import time
import numpy as np
import requests
import json
import csv
# ua=UserAgent()
# headers={"User-Agent":ua.random}
# productid = ['35216&productId=5089271','136061&productId=5089275','22778&productId=5475612','7021&productId=6784504']#四种颜色id
def commentSave(list_comment):
file = open('JDComment_data.csv','w',newline = '')
writer = csv.writer(file)
writer.writerow(['用户ID','评论内容','会员级别','点赞数','回复数','得分','购买时间','手机型号'])
for i in range(len(list_comment)):
writer.writerow(list_comment[i])
file.close()
print('存入成功')
def getCommentData(maxPage):
sig_comment = []
global list_comment
cur_page = 0
while cur_page < maxPage:
cur_page += 1
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv%s&score=%s&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1'%(proc,i,cur_page)
try:
response = requests.get(url=url, headers=headers)
time.sleep(np.random.rand()*2)
jsonData = response.text
startLoc = jsonData.find('{')
#print(jsonData[::-1])//字符串逆序
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
pageLen = len(jsonData['comments'])
print("当前第%s页"%cur_page)
for j in range(0,pageLen):
userId = jsonData['comments'][j]['id']#用户ID
content = jsonData['comments'][j]['content']#评论内容
levelName = jsonData['comments'][j]['userLevelName']#会员级别
voteCount = jsonData['comments'][j]['usefulVoteCount']#点赞数
replyCount = jsonData['comments'][j]['replyCount']#回复数目
starStep = jsonData['comments'][j]['score']#得分
creationTime = jsonData['comments'][j]['creationTime']#购买时间
referenceName = jsonData['comments'][j]['referenceName']#手机型号
sig_comment.append(userId)#每一行数据
sig_comment.append(content)
sig_comment.append(levelName)
sig_comment.append(voteCount)
sig_comment.append(replyCount)
sig_comment.append(starStep)
sig_comment.append(creationTime)
sig_comment.append(referenceName)
list_comment.append(sig_comment)
sig_comment = []
except:
time.sleep(5)
cur_page -= 1
print('网络故障或者是网页出现了问题,五秒后重新连接')
return list_comment
if __name__ == "__main__":
global list_comment
ua=UserAgent()
headers={"User-Agent":ua.random}
#手机四种颜色对应的产品id参数
productid = ['35216&productId=5089271','136061&productId=5089275','22778&productId=5475612','7021&productId=6784504']
list_comment = [[]]
sig_comment = []
for proc in productid:#遍历产品颜色
i = -1
while i < 7:#遍历排序方式
i += 1
if(i == 6):
continue
#先访问第0页获取最大页数,再进行循环遍历
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv%s&score=%s&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1'%(proc,i,0)
print(url)
try:
response = requests.get(url=url, headers=headers)
jsonData = response.text
startLoc = jsonData.find('{')
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
print("最大页数%s"%jsonData['maxPage'])
getCommentData(jsonData['maxPage'])#遍历每一页
except:
i -= 1
print("wating---")
time.sleep(5)
#commentSave(list_comment)
print("爬取结束,开始存储-------")
commentSave(list_comment)


























瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)