

On the Detection of Digital Face Manipulation论文阅读笔记
处理数字伪造的人脸图像检测和定位任务。利用注意力机制来处理检测模型的特征图,学习的注意力图突出了用于提高检测能力的信息区域,并且还突出了伪造的面部区域。面部伪造攻击主要有三种类型:1、物理欺骗攻击(打印和重放攻击)2、对抗性攻击:生成高质量且感知不到的对抗性图像,可以避开自动面部匹配器3、数字伪造攻击:通过V变量自动编码器(VAE)和生成对抗网络(GAN)可以生成完全或部分修改的真实感人脸图像。
介绍
处理数字伪造的人脸图像检测和定位任务。利用注意力机制来处理检测模型的特征图,学习的注意力图突出了用于提高检测能力的信息区域,并且还突出了伪造的面部区域。
面部伪造攻击主要有三种类型:
1、物理欺骗攻击(打印和重放攻击)
2、对抗性攻击:生成高质量且感知不到的对抗性图像,可以避开自动面部匹配器
3、数字伪造攻击:通过V变量自动编码器(VAE)和生成对抗网络(GAN)可以生成完全或部分修改的真实感人脸图像
任务仅针对数字伪造攻击,目标是自动检测被伪造的面部以及定位修改的面部区域,提出了以监督和弱监督方式估计注意力图的方法, 为了量化注意力图估计,我们提出了一种新的注意力图准确性评估度量。提出一种注意力机制来自动检测面部图像的伪造区域,需要很少的额外可训练参数
注意力模块被广泛用于图像分类、图像修复和对象检测,不仅选择集中的位置,还可以增强该位置的对象表示。Choe等人提出了一种基于注意力的丢弃层来处理模型的特征图,第一次开发面部操纵检测和定位的注意力机制。
数字面部伪造方法分为四类:表情交换通过3D人脸重建和动画方法,如Face2face,仅使用RGB相机就可以实时将表情从一个人传递到另一个人。“合成奥巴马”根据输入的音频使面部动画化
身份交换将一个人脸替换为另一个,同时保留表情,如FaceSwap将著名演员插入到从未出现过的电影片段DeepFakes深度学习算法执行人脸交换
属性交换编辑面部的单个或多个属性,例如性别、年龄、肤色、头发和眼镜。GAN的对抗性框架用于图像翻译或给定上下文的伪造,FaceApp可以选择性地修改面部属性
整个面部合成基于GAN的方法可以生成整个合成人脸,包括非人脸背景
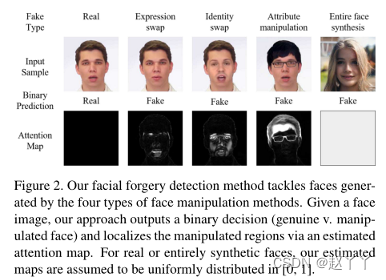
给定一张人脸图像,输出一个二元决策,并通过估计的注意力图来定位被操纵的区域,对于完全真实或完全合成的人脸,估计映射被假设为均匀分布在[0,1]中
贡献:1、制作了一个综合的fakeface数据集,包括0.8M真实人脸和1.8M由不同方法生成的伪人脸。
2、提出一种新颖的基于注意力的层,用于提高分类性能并产生指示被操纵的面部区域的注意力图。
3、提出一种新的度量,称为IINC(Inverse Intersection Non-containment ),用于评估注意力图,产生比现有度量更一致的评估。
方法
使用基于CNN的网络将操纵的人脸检测作为二进制分类问题。进一步提出利用注意力机制来处理分类器模型的特征图。学习到的注意力图可以突出图像中影响CNN决策的区域,并进一步用于指导CNN发现更具歧视性的特征。
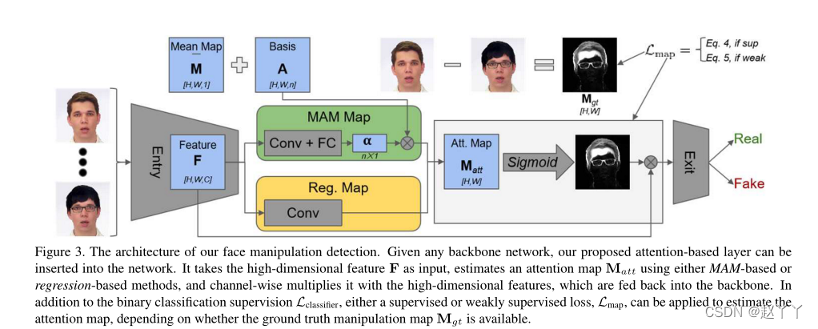
给定任何主干网络,基于注意力的层都可以插入到网络中,将高维特征F作为输入(卷积特征图F∈RH×W×C,其中H、W、C分别是高度、宽度和通道数),使用基于MAM或基于回归的方法来估计注意力图Matt(生成关注映射Matt=Φ(F)∈RH×W,其中Φ(·)表示处理算子),并将其与高维特征按通道相乘,这些特征被反馈到主干网络中
注意力图的动机
注意力图中的每个像素将计算其感受野对应于输入图像中的伪造区域的概率。将注意力图插入主干网络,其中感受野对应于适当大小的局部补丁。然后,注意力图之前的特征对相应补丁的高频指纹进行编码,这可以在局部级别区分真实区域和操纵区域。
考虑因素:1、可解释性,产生一个注意力图,预测修改后的像素在哪里,则会产生一个辅助输出,解释网络基于哪些空间区域进行决策,使用注意图图作为掩膜,从网络中高维特征中移除任何的无关信息
2、有用性,将注意力图反馈回网络以忽略未激活的区域,去除部分伪造图像的真实区域,以便用于最终二值分类的特征完全来自修改区域。
3、模块性,通过包含单个卷积层及相关损失函数,并屏蔽后续高维特征,注意力图很容易实现并插入现有骨干网络,甚至可以通过仅初始化用于生成注意力图的权重来利用预先训练的网络来实现。
注意力模块
注意力模块的输出是细化的特征图F’,其中其中⊙表示元素乘法。关注图中每个像素的强度对于真实区域接近于0,对于伪区域接近于1。换句话说,关注图的像素指示原始图像补丁是伪区域的概率。这有助于后续骨干网络将其处理集中到关注图的非零区域,即伪区域。
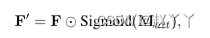
两种实现Φ(·)的方法:操纵外观模型(MAM)和直接回归。
MAM:假设任何伪造的图都可以表示为一组图原型的线性组合
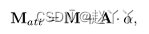
其中, ¯M ∈ R(H·W )×1 , A ∈ R(H·W )×n是预定义的平均映射和映射的基函数,利用一个额外的卷积和一个全连接层来回归F的权重权重参数α∈Rn×1
统计基数A,将主成分分析(PCA)应用于FaceAPP100个伪造掩膜,前10个主要成分用作基础,即n=10。
好处:首先,这限制了图估计的解空间。第二,降低了注意力估计的复杂性,这有助于泛化。

直接回归 通过卷积运算f:f可以由多个卷积层或单个层组成,好处:简单有效,适用于自适应特征细化。
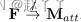
损失函数
总体训练损失函数
其中Lclassifier是Softmax的二值分类损失,Lmap是注意力图损失。λ是损失重量。
对于注意力图的学习考虑三种:
有监督:如果训练样本与地面真相注意掩膜配对,使用有监督方式训练网络。强大的监督可以帮助基于注意力的层学习最具有辨别力的区域和特征,从而进行假脸检测。

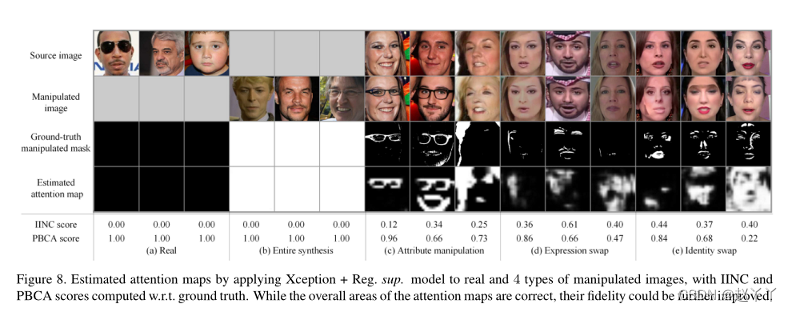
其中,Mgt是地面真相伪造掩膜,使用零个贴图作为真实人脸的Mgt,使用一个贴图作为完全合成的假人脸的Mgt。对于部分操纵的人脸,我们将假图像与其对应的源图像配对,计算RGB通道中的绝对像素差异,转换为灰度,除以255以产生[0,1]范围内的映射。根据经验确定阈值0.1以获得作为Mgt的二进制修改图。
弱监督:对于部分伪造的面部,有时源图像不可用,无法获得Mgt。
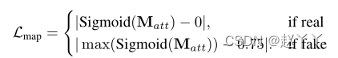
这种损失导致注意力图对于真实图像保持未激活状态,即全部为0。对于假图像,无论整个或部分操作如何,整个贴图的最大贴图值应该足够大,在我们的实验中为0.75。
无监督:当λm设置为0时,所提出的注意力模块还允许我们在没有任何图监督的情况下训练网络。仅在图像级分类监督下,注意力图自动学习信息区域。
实验
实验设置
损失权重λ设置为1,批量大小为16,其中每个小批量由8个真实图像和8个假图像组成。我们使用XceptionNet和VGG16作为骨干网络。这两个网络都在ImageNet上进行了预训练,并在DFFD上进行了微调。
在所有实验中,Adam优化器的学习率均为0.0002。根据主干架构,我们训练75k-150k次迭代,这在NVidia GTX 1080Ti上需要不到8小时。
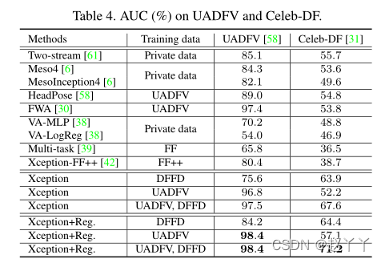
指标:对于检测,等误差率(EER)、ROC的曲线下面积(AUC)、假检测率(FDR)为0.01%时的真检测率(TDR)(表示为TDR0.01%)和FDR为0.1%时的TDR(表示为FDR0.1%)。
对于定位,使用已知的地面真值掩模,逐像素二进制分类精度(PBCA),以及两个矢量化地图之间的余弦相似性。提出了一种新的度量,称为反向相交非包容(IINC),用于评估面部操纵定位性能。
利用SOTA XceptionNet作为主干网络。它基于具有残余连接的深度可分离卷积层。我们通过在中间流的块4和块5之间插入基于注意力的层,将XceptionNet转换为我们的模型,然后对DFFD训练集进行微调。
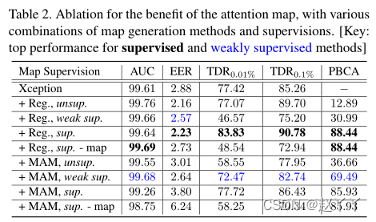
低FDR时的TDR(即TDR0.01%)应是比较各种方法的主要指标,监督学习在检测和定位精度方面都优于弱监督和无监督学习。基于MAM的方法在弱监督或无监督情况下更为优越,因为MAM为图估计提供了强大的约束。
最后,代替使用softmax输出,另一种方法是使用估计注意力图的平均值进行检测,因为损失函数鼓励真实人脸的低注意力值,而假人脸的高注意力值。-map行显示了该替代方案的性能,虽然这并不优于softmax输出,但它表明注意力图本身对于面部伪造检测任务是有用的。
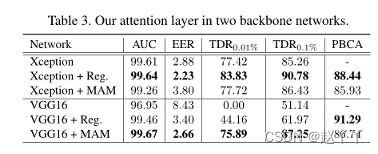
比较了XceptionNet和VGG16(有和没有关注层)。Reg.和MAM模型都在监督方式中进行了训练。我们观察到,使用注意机制确实提高了对两个主干的检测。具体而言,使用大型深度网络(XceptionNet),在给定大参数空间的情况下,网络可以直接生成注意力图。与从MAM基础估计的地图相比,该直接生成的注意力地图可以更好地预测被伪造的区域。当使用更小和更浅的网络(VGG16)时,我们发现注意力图的直接产生会导致参数空间中的竞争。因此,包括MAM基的先验减少了这种竞争,并允许提高检测性能,尽管其对伪造区域的估计受到图基的约束。
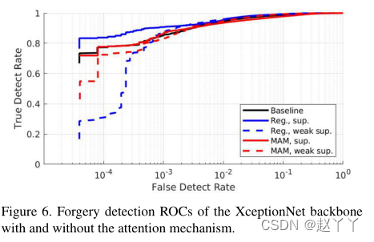
注意力图的直接回归方法在低FDR下产生了性能最佳的网络。
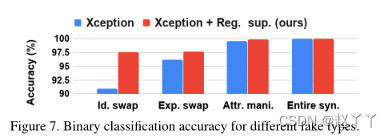
注意力层显著优于传统的XceptionNet,特别是在较低的FDR下。
使用三个度量来评估注意力图:联合上的交集(IoU)、余弦相似性和逐像素二进制分类精度(PBCA)。这三个指标不足以对这些不同的地图进行稳健评估。因此,我们提出了一个新的度量,IINC

其中I和U分别是地面真实图Mgt和预测图Matt之间的交集和并集。M和|M|分别是M的均值和L1范数。这两个分数项分别测量交集的面积与每个地图的面积之比,IINC通过测量两个映射的非重叠比率,而不是像IoU中的组合重叠。
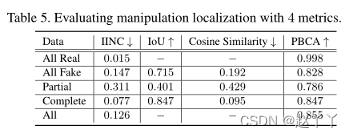
当任意一个贴图均为0时,IoU和余弦相似性未定义,这是真实人脸图像的情况。
未来
预测注意力图将揭示伪造的类型,幅度甚至意图

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)