

【LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference论文解读】
本文的创新点在于提出了transformer金字塔,attention计算中减小Q的大小,让特征图过了几层transformer金字塔后HW大大缩小,C有限增加,宏观上LeViT是CNN金字塔+transformer金字塔,最后实现小数据量的层次性transforrmer结构。另外本文还提出了attention bias用来取代position encoding.论文地址:论文PDF地址代码地
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference论文解读
前言
本文的创新点在于提出了transformer金字塔,attention计算中减小Q的大小,让特征图过了几层transformer金字塔后HW大大缩小,C有限增加,宏观上LeViT是CNN金字塔+transformer金字塔,最后实现小数据量的层次性transforrmer结构。另外本文还提出了attention bias用来取代position encoding.
论文地址:论文PDF地址
代码地址:github代码地址
0.摘要
作者说他们重新审视了CNN结构的优点,想着把CNN的结构引入transformer.特别是CNN金字塔,他们对CNN中分辨率不断降低的activation map(其实就是featrue map)很感兴趣,因为分辨率降低,通道数增加,但总的来说数据量还是降低的,这对能快速推理很重要。所以作者介绍的LeViT模型能在推理速度和准确率取得比较平衡的结果。

1.introduction
作者首先简要介绍了transformer模块。然后提出他们比较看重在性能和准确率之间的取得比较平衡的结果。所以最后使用了带池化的金字塔transformer块取代传统的transformer块。因为类似于LeNet,所以起名叫LeViT.
最后看看本文的contribution:
1.能在transformer块里实现下采样的金字塔型结构
2.可学习的attention bias能取代position encoding
2.related work
。。。
3.Motivation
本节作者简要的介绍了将transformer嫁接到resnet的实验。通过逐渐改变resnet阶数与Deit的层数来考察其在imagenet上的准确度与速度。

从实验结果来看两者混合后的实验结果要比单独一种结构更好,这个实验给作者带来了信心,CNN与transformer的混合结构能带来更好的结果。于是作者提出了CNN与transformer结合更加紧密的LeViT,而不是简单的嫁接。
4.Model

上图是LeViTd的整体结构图,也是我们要介绍的主要部分。可以看出LeViT结合了CNN金字塔与transformer金字塔。
Patch embedding
patch embedding部分就是上图的CNN金字塔部分。输入图像不考虑batchsize的话shape是(3x224x224)即(CxHxW)。通过四次3x3卷积,stride取2.每次输入都会H,W减半,C加倍。C从3->32->64->128->256。H和W是224->112->56->28->14经过卷积后,H,W缩小到1/16,相当于patch_size=16后取的token.注意Conv2d_BN包括一次卷积,一次BN。
#patch embedding
def b16(n, activation, resolution=224):#n是的embed_dimension[0],将作为transformer第一层输入的维度。
return torch.nn.Sequential(
Conv2d_BN(3, n // 8, 3, 2, 1, resolution=resolution),
activation(),
Conv2d_BN(n // 8, n // 4, 3, 2, 1, resolution=resolution // 2),
activation(),
Conv2d_BN(n // 4, n // 2, 3, 2, 1, resolution=resolution // 4),
activation(),
Conv2d_BN(n // 2, n, 3, 2, 1, resolution=resolution // 8))
No CLS token
为了更好的保护BCHW的数据格式,最终决定不加入class token,这样token的数量224/16=14.
Multi-resolution pyramid
上述MLPx2层包括Linear+BN重复两次。本文使用了两种attention块。一种是普通的attention一种是shrink attention。两者交替使用构成了transformer金字塔.

上图是shrink attention模块,下图是普通的attention模块。

下方是两种attention模块的结构图。

可以看出普通的transformer模块基本上遵循传统的attention计算方式,不同的地方是给QKT加上了attention_bias,以替代postion encoding。另外还增加了Hardswish激活函数。
比较值得关注的是shrink attention,在进行attention计算前,其中一个输入经过sub-sample后shape从CxHxW->Cx(H/2)x(W/2)
这样取Q的shape就变成(DxHW/4).QKT的shape变为(HW/4)xHW.把QKT看成相似性sim。则softmax(sim)V的shape变为((HW/4)x4D)->(4DxH/2xW/2)->(C’xH/2xW/2)这样就完成了数据量的减少。C’是embed_dimension,由作者所固定设置。
接下来说说attention bias.attention abis被设置成可学习变量来表示位置,初始化是torch.zeros来完成的。
attention bias一共的数量是HW个,如果是CHW(256,14,14)进来的,那么attention bias取1414=196个。
原因在于其编码的方式

我们可以把QKT看成矩阵里面不同的pixel相乘,就是上面公式Q(x,y) * K(x’,y’)
就是Q里面的(x,y)点与K里面的(x’,y’)点相乘,那么作者认为positon应该是两点之间的差的绝对值|x-x’| , |y-y’|,注意这里是相对position,还没有进行编码。也就是说实际上有效的position位置仅仅只有HW个,例如H,W取14,则相对position只有[(0,0),(0,1),(0,2),…(0,13),(1,0),(1,1),…(1,13),…(13,13)]共14*14个坐标。
points = list(itertools.product(range(resolution), range(resolution)))###resolution代表k的H,W,例如为14
points_ = list(itertools.product(
range(resolution_), range(resolution_)))###resolution_代表q的H,W,例如为7
##points=[(0,0),(0,1),(0,2),...(0,13),(1,0),(1,1),...(1,13),...(13,13)]共14^2个坐标,囊括了K的所有点,points_也是如此
N = len(points)#N=196
N_ = len(points_)#N_=49
attention_offsets = {}
idxs = []
for p1 in points_:#Q坐标合集
for p2 in points:#K坐标合集
size = 1
offset = (
abs(p1[0] * stride - p2[0] + (size - 1) / 2),#这里是x-x0
abs(p1[1] * stride - p2[1] + (size - 1) / 2))#这里是y-y0
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)#attention_offsets是关于(x,y)与bias的字典。例如(1, 3): 17代表|x-x0|=1,|y-y0|=3时,相对position取17
idxs.append(attention_offsets[offset])#idxs是HW*HW,包含了Q*KT的所有Pixel的position,不是bias,是positon.
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))#attention_offsets的长度代表了所有有效的position数量。例如H,W都是14,那么(0,0)(0,1)(0,2)...(0,13)(1,0)(1,1)...(1,13)...(13,13)共196个
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N_, N))
#####################计算attention并加bias
attn = (q @ k.transpose(-2, -1)) * self.scale + (self.attention_biases[:, self.attention_bias_idxs#(num_head,Hq*Wq,Hk*Wk)
4.experiment
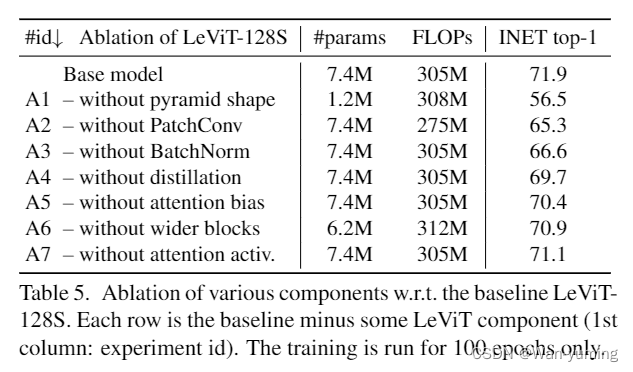
实验中我们比较关心的是消融研究。从实验结果可以看到金字塔transformer和attention bias都是有增益的。启示是金字塔型transformer是可行的。我们可以尝试用金字塔型transformer来代替传统的CNN transformer来做文章。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)