
OWL:云智慧智能研究院联合北航提出智能运维(AIOps)大语言模型
本篇文章为大家介绍由云智慧智能研究院和北航合作的智能运维(AIOps)大语言模型 ,Owl: A Large Language Model for IT Operations(猫头鹰:用于 IT 运维的大型语言模型)。论文链接:https://arxiv.org/abs/2309.09298Repo链接:https://github.com/HC-Guo/OwlIntroduction随着 IT

本篇文章为大家介绍由云智慧智能研究院和北航合作的智能运维(AIOps)大语言模型 ,Owl: A Large Language Model for IT Operations(猫头鹰:用于 IT 运维的大型语言模型)。

论文链接:
https://arxiv.org/abs/2309.09298
Repo链接:
https://github.com/HC-Guo/Owl

Introduction
随着 IT 业务的快速发展, 在实际应用中有效管理和分析大量数据变得越来越重要。自然语言处理(NLP)技术已在各种任务中显示出非凡的能力,包括命名实体识别、机器翻译等。最近,大型语言模型(LLM)在各种 NLP 下游任务中取得了显著的改进。然而,目前还缺乏用于智能运维(AIOps)的专门 LLM。
在本文中,我们将介绍一种大型语言模型 Owl,它是在收集的 Owl-Instruct 数据基础上训练而成的大型语言模型。本文提出了 Mixture-of-Adapter strategy 策略,以提高不同子领域或任务的微调效果。此外,由于缺乏智能运维领域的大语言模型的 Benchmark,本文建立了 Owl-Bench 测评基准,Owl 和其他量级的模型在 Owl-bench 和其他 IT 相关的基准上进行了评估。
实验表明,Owl 的性能超过了现有开源模型。此外,我们还希望我们的研究结果能提供更多的启示,专业化的大型语言模型将大大提高细分领域中与 IT 相关的任务的效率、准确性和理解能力,最终推动 IT 智能运维领域的发展。从而利用专门的 LLM 彻底改变 IT 运维领域(AIOps)。

Owl-Instruct Construction
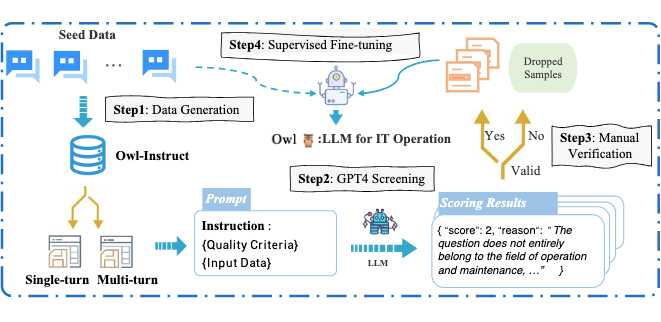
▲ 图1: 建立Owl-Instruct和训练Owl的流程
第一步:种子数据搜集
作者聘请 IT 运营和维护领域的专家,精心设计输入和输出序列以及综合说明。这些内容涵盖了广泛的来自运维(O&M)领域九个常见领域的数据:信息安全、应用程序、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库。在每个领域中,都包含了不同的任务,例如运维知识问答、部署、监控、故障诊断、性能优化、日志分析、脚本编写、备份和恢复等。最终作者得到了一个由 2,000 个单轮和 1,000 个多轮对话的种子数据实例组成的语料库。
第二步:数据扩充
对于单轮数据,我们借鉴 Self-Instruct 的方法,最终产生了 9118 条数据。对于多轮对话数据,我们借鉴 Baize 中阐明的方法,最终得到 8,740 条多轮对话数据。
第三步:数据质量
为了保持严格的数据质量标准,作者将 GPT-4 评分与细致的人工验证相结合。这种双重验证流程可确保生成数据的完整性和可靠性,同时提高数据的整体质量。在利用 GPT-4 进行评分时,作者针对数据集精心设计了特定的提示。这些提示使 GPT-4 能够根据预定义的质量标准对生成的数据进行评估和评分,能够迅速识别并过滤低质量的数据实例。
与此同时,数据还经过严格的人工验证。由专家组成的审核团队会对每个数据条目进行深入评估。这一人工检查过程需要对内容、连贯性以及与特定领域知识的一致性进行彻底检查。

Owl-Bench Construction
在运维(Operations and Maintenance,O/M)领域,由于缺乏专门用于评估大型语言模型性能的基准,在有效评估和比较该领域大语言模型的能力方面存在严重不足。
为了弥补这一不足,作者构建了一个双语基准——Owl-Bench,它由两个不同的部分组成:由 317 个条目组成的问答部分,和由 1000 个问题组成的多选部分。作者涵盖了该领域的众多现实工业场景,确保 Owl-Bench 能够展现出多样性。测评集的收集过程包括信息安全、应用、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库这九个不同的子领域。这些数据都是未经过类 GPT 模型生成的,并预处理成问答题和选择题的形式。

▲ 图2:根据数据集词频生成的词云

Experiment
4.1 Owl-Bench实验结果
作者首先展现了 Owl-bench 的实验结果,包括问答题和选择题的结果。实验结果都证明了 Owl 相关生态的有效性。
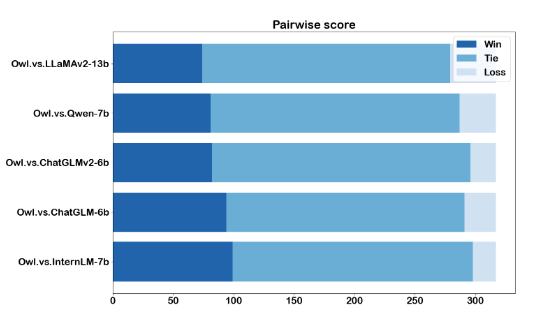
▲ 图3:问答题pairwise的结果, 以GPT4作为评测
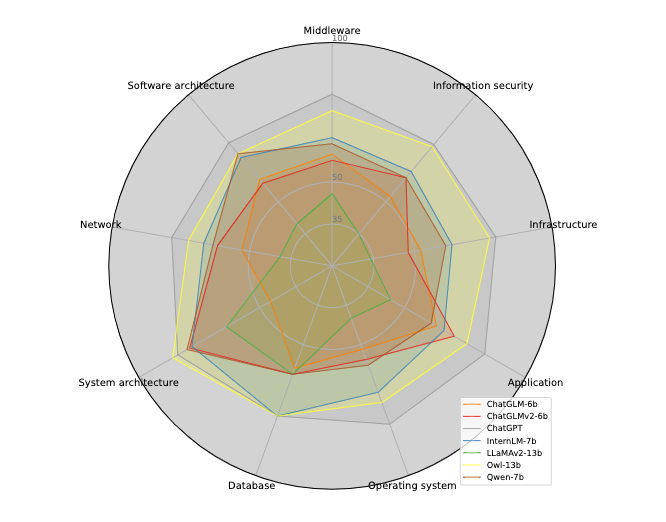
▲ 图4:选择题zero-shot得分雷达图
运维领域下游任务:
为了验证 Owl 的泛化性,作者在运维相关下游任务进行了测试,作者选取了两个典型任务(日志解析、日志异常检测)进行了测试。对于这两个典型任务,作者设计了特定的 prompt,相关实验证实了 Owl 的有效性。

▲ 图5:日志解析基准测试结果
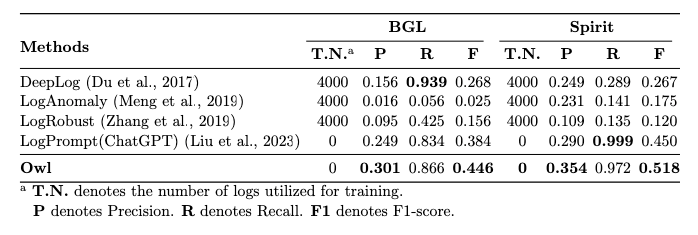
▲ 图6:日志异常检测基准测试结果

Conclusion
在本文中,作者介绍了一个智能运维(AIOps)大型语言模型 Owl。作者建立了 Owl-instruct 数据集来提高模型的领域理解能力,并在建立的 Owl-Bench 和 IT 相关 Benchmark 上进行测试。这是作者用 LLM 推动 IT 智能运维领域发展的一次有效尝试。为推动开源社区的发展,相关微调和 benchmark 数据也将一并开源,敬请期待。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)