
python爬虫的基本概念
网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者)。如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物数据。

一、为什么要学习爬虫
学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的工作原理进行更深层次地理解。
当下是大数据时代,在这个信息爆炸的时代,我们可以利用爬虫获取大量有价值的数据,通过数据分析获得更多隐性的有价值的规律。
方便就业。从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高所以,深层次地掌握这门技术,对于就业来说,是非常有利的。(而且辅助工作也是非常不错的,各种接单平台,爬虫的单子多且简单,收入也很可观哦!)
用途广泛。针对电商来说,抓取各种商品信息就可以做到精细化运营,精准营销。对新闻资讯平台和搜索引擎来说,抓取其他平台原创新闻稿,进行热点分析,就可以合理筛选优质内容,打造更有价值的新闻平台。(还可以抓取车票、爬取论文素材等等。已经与我们的生活结合在一起了。)
在通往全栈程序员的道路上,爬虫是必不可少的一项技术。
二、爬虫介绍
网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者)。如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物数据。

三、爬虫分类 (通用爬虫和聚焦爬虫)
通用爬虫。通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo 等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫。聚焦爬虫,是 “面向特定主题需求” 的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。如果你依然在编程的世界里迷茫,不知道自己的未来规划可以加入我们的 Python 月球号去762 掉459 文 510 字看看前辈们如何学习的!交流经验!自己是一名高级 python 开发工程师,从基础的 python 脚本到 web 开发、爬虫、django、数据挖掘等,零基础到项
四、爬虫的结构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL 管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的 CPU,主要负责调度 URL 管理器、下载器、解析器之间的协调工作。
URL 管理器:包括待爬取的 URL 地址和已爬取的 URL 地址,防止重复抓取 URL 和循环抓取 URL,实现 URL 管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个 URL 地址来下载网页,将网页转换成一个字符串,网页下载器有 urllib2(Python 官方基础模块)包括需要登录、代理、和 cookie,requests (第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据 DOM 树的解析方式来解析。
应用程序:就是从网页中提取的有用数据组成的一个应用。
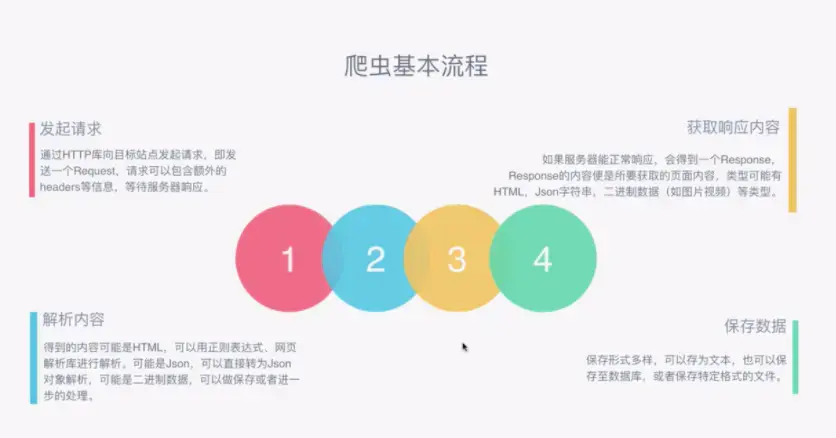
五、爬虫的工作原理及基本流程
打开一个浏览器 — 输入网址 — 回车 ---- 看到呈现的有关关键字网站的列表(每一个网站里有标题,描述信息,站点,百度快照连接等等之类的)
我们要用爬虫抓取有关新闻的网页面的话怎么做呢? 点击右键 – 审查元素 — 控制台(Elements 是网页源代码(我们看到的网页就是源代码解析出来的),把代码获取下来用一些解析库把代码解析出来然后存成一些结构化的数据。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)