
mlp搭建神经网络项目:对声音特征的提取
mlp神经网络项目:对声音特征的提取(含徒手搭建mlp源代码,以及神经网络正向传播+反向传播原理推导)
mlp神经网络项目1:BP神经网络对声音特征的提取
文章目录
- mlp神经网络项目1:BP神经网络对声音特征的提取
- 代码原理分析:
代码原理分析:
(mlp项目代码分析)
0.背景知识
0.1函数解析sort()
% 1.sort()函数的用法:
[X,Y] = sort(M); %返回的X矩阵为排序后的矩阵,Y为排序后每个元素的索引好
% 2.sort()函数默认对列进行升序排列:
sort(M,2) % 对行进行升序排序
sort(M,2,"descend") % 对行进行降序排序
sort(M,1,"ascend") % 对列进行升序排序,1和ascend都是默认参数,可以省略
%测试代码
clear,clc;
M = magic(3); % 生成一个由1~9构成的任意顺序的3*3矩阵
[New_M,Index] = sort(M);
Row_ascend = sort(M,2)
Row_decend = sort(M,2,"descend")
Col_ascend = sort(M,1,"ascend")
产生的index矩阵可以用于随机分割训练集以及测试集:
- rand(1,n)可以产生n个[0,1]的随机数,利用sort排序将其序列号进行打乱存到index矩阵中
- 对index进行切片,如index(1,1:1500)即可随机获取1500条数据作为训练集
0.2运行结果:
New_M = Index = Row_ascend =
3 1 2 2 1 3 1 6 8
4 5 6 3 2 1 3 5 7
8 9 7 1 3 2 2 4 9
Row_decend = Col_ascend =
8 6 1 3 1 2
7 5 3 4 5 6
9 4 2 8 9 7
0.3函数解析mapminmax():
mapminmax()作用:
- 将矩阵进行归一化操作
- 将矩阵所有数据映射到区间[-1,1]上,最小值为-1,最大值为1
% mapminmax()用法:
[target_Matrix,ps] = mapminmax(M) % 生成的目标矩阵为target_Mastrix,映射方式为ps,可以下次使用
% 利用已有的映射方式进行初始化:
target_Matrix = mapminmax("apply",M,ps) % 此处的ps为之前使用过的映射方法
% 测试代码:
clear,clc;
% 创建两个矩阵Matrix_ori和Matrix_ano
Matrix_ori = [1,2,3,2,1];
Matrix_ano = [2,3,4,3,2];
%% 利用mapminmax()函数对其进行归一化
% 方式1:创建目标矩阵tar_M1和方法ps
[tar_M1,ps] = mapminmax( Matrix_ori )
% 方式2:;利用原有的方法ps创建目标矩阵tar_M2
tar_M2 = mapminmax( "apply" , Matrix_ano , ps)
0.4 运行结果:
tar_M1 = tar_M2 =
-1 0 1 0 -1 0 1 2 1 0
ps =
包含以下字段的 struct:
name: 'mapminmax'
xrows: 1
xmax: 3
xmin: 1
xrange: 2
yrows: 1
ymax: 1
ymin: -1
yrange: 2
gain: 1
xoffset: 1
no_change: 0
0.5函数解析rands():在[-1,1]范围内生成制定大小的随机矩阵(代码略)
1.BP神经网络数学推导
1.1 常见数学量
1. 平方损失 L ( ω 1 , ω 2 , b 1 , b 2 ) = 1 2 ∗ ( y − y ^ ) 2 1.平方损失L(\omega_1,\omega_2,b_1,b_2) = \frac{1}{2}*(y-\hat{y})^2 1.平方损失L(ω1,ω2,b1,b2)=21∗(y−y^)2
2. y ^ 的计算公式: y ^ = ω ∗ x + b 2.\hat{y} 的计算公式:\hat{y} = \omega * x + b 2.y^的计算公式:y^=ω∗x+b
3. 误差 e r r o r 计算公式: E = y − y ^ 3.误差error计算公式:E = y - \hat{y} 3.误差error计算公式:E=y−y^
1.2正向传播推导(假设输入,隐藏和输出都只有1维,激活函数选择Sigmoid函数)
1. 隐藏层输入: I n p u t _ H i d d e n = ω 1 ∗ x + b 1 1.隐藏层输入:Input\_Hidden=\omega_1*x+b_1 1.隐藏层输入:Input_Hidden=ω1∗x+b1
2. 隐藏层输出: H i d d e n _ O u t = 1 1 + e − I n p u t _ H i d d e n 2.隐藏层输出:Hidden\_Out=\frac{1}{1+e^{-Input\_Hidden}} 2.隐藏层输出:Hidden_Out=1+e−Input_Hidden1
3. 最后输出: H i d d e n _ O u t p u t = ω 2 ∗ H i d d e n _ O u t + b 2 3.最后输出:Hidden\_Output = \omega_2 * Hidden\_Out+b_2 3.最后输出:Hidden_Output=ω2∗Hidden_Out+b2
4. 平方损失: L ( ω 1 , ω 2 , b 1 , b 2 , x ) = 1 2 ∗ ( y − H i d d e n _ O u t p u t ) 2 4.平方损失:L(\omega_1,\omega_2,b_1,b_2,x)=\frac{1}{2}*(y-Hidden\_Output)^2 4.平方损失:L(ω1,ω2,b1,b2,x)=21∗(y−Hidden_Output)2
5. 误差 E r r o r : E = y − H i d d e n _ O u t p u t 5.误差Error:E = y-Hidden\_Output 5.误差Error:E=y−Hidden_Output
1.3反向传播推导(学习率为η,S为Sigmoid函数)
1. 损失函数对 ω 2 的偏导 : ∂ L ∂ ω 2 = − E ∗ H i d d e n _ O u t 1.损失函数对\omega_2的偏导:\frac{\partial{L}}{\partial{\omega_2}}=-E*Hidden\_Out 1.损失函数对ω2的偏导:∂ω2∂L=−E∗Hidden_Out
2. 损失函数对 b 2 的偏导 : ∂ L ∂ b 2 = − E 2.损失函数对b_2的偏导:\frac{\partial{L}}{\partial{b_2}} = -E 2.损失函数对b2的偏导:∂b2∂L=−E
3. 损失函数对 ω 1 的偏导: ∂ L ∂ ω 1 = − E ∗ H i d d e n _ O u t ∗ x ∗ S ′ 3.损失函数对\omega_1的偏导:\frac{\partial{L}}{\partial{\omega_1}}=-E*Hidden\_Out*x*S^\prime 3.损失函数对ω1的偏导:∂ω1∂L=−E∗Hidden_Out∗x∗S′
4. 损失函数对 b 1 的偏导: ∂ L ∂ b 1 = − E ∗ H i d d e n _ O u t ∗ S ′ 4.损失函数对b_1的偏导:\frac{\partial{L}}{\partial{b_1}} = -E*Hidden\_Out*S^\prime 4.损失函数对b1的偏导:∂b1∂L=−E∗Hidden_Out∗S′
5. G D 更新参数: ω 1 = ω 1 − η ∗ ∂ L ∂ ω 1 、 ω 2 = ω 2 − η ∗ ∂ L ∂ ω 2 、 b 1 = b 1 − η ∗ ∂ L ∂ b 1 、 b 2 = b 2 − η ∗ ∂ L ∂ b 2 5.GD更新参数:\omega_1=\omega_1-\eta*\frac{\partial{L}}{\partial{\omega_1}} 、\omega_2=\omega_2-\eta*\frac{\partial{L}}{\partial{\omega_2}}、b_1=b_1-\eta*\frac{\partial{L}}{\partial{b_1}}、b_2=b_2-\eta*\frac{\partial{L}}{\partial{b_2}} 5.GD更新参数:ω1=ω1−η∗∂ω1∂L、ω2=ω2−η∗∂ω2∂L、b1=b1−η∗∂b1∂L、b2=b2−η∗∂b2∂L
2.代码复现
clear,clc
%% 加载四个数据文件,名称分别为c1,c2,c3,c4
load data1.mat c1
load data2.mat c2
load data3.mat c3
load data4.mat c4
%将四个数据集合并成一个矩阵data,大小为2000*25
data(1:500,:) = c1;
data(501:1000,:) = c2;
data(1001:1500,:) = c3;
data(1501:2000,:) = c4;
%% 对数据进行预处理:划分出标签和特征+划分训练集以及测试集+参数的归一化处理
% 划分出标签,以及特征矩阵
label = data(:,1);
feature1 = data(:,2:25);
% 利用mapminmax()函数对数据进行归一化处理
[feature,inputps] = mapminmax(feature1);
% 随机划分出75%的训练集以及25%的测试集
rand_M = rand(1,2000); %生成数据大小为1*2000的,每个元素介于[0,1]之间的随机数
%对随机数进行排序,于是每个元素的序号被打乱,index矩阵即可以被用于随机取样
[matrix_tar,index] = sort(rand_M);
% 利用index矩阵进行随机取样产生输入训练集以及测试集
input_training = feature(index(1,1:1500),:); % 输入的训练集大小为1500*24,用index随机抽样
input_test = feature(index(1,1501:2000),:); % 输入的训练集大小为500*24,用index随机抽样
% 将输出矩阵进行拓展:将一维的输出变成4维的输出,因为有四种类别(需要创建新的矩阵label_expand来承接拓展的矩阵,否则尺寸不一无法赋值)
for i = 1 : 1 : 2000
switch label(i,1)
case 1
label_expand(:,i) = [1;0;0;0];
case 2
label_expand(:,i) = [0;1;0;0];
case 3
label_expand(:,i) = [0;0;1;0];
case 4
label_expand(:,i) = [0;0;0;1];
end
end
label_expand = label_expand';
% 得到的label_expand矩阵的大小为2000*4
% 利用index矩阵产生输出训练集以及测试集
output_training = label_expand(index(1,1:1500),:); % 输出的训练集大小为1500*4,用index随机抽样
output_test = label_expand(index(1,1501:2000),:); % 输出的训练集大小为500*4,用index随机抽样
%% 对参数进行初始化
% 确定神经网络的大小
input_layer_24 = 24; % 由于数据具有24维的特征,因此输入数据的维度是24维
hidden_layer_25 = 25; % 由经验确定的,隐藏层具有25维
output_layer_4 = 4; %由于最终要分出4类,因此输出层为4维
% 利用随机函数rands()初始化权重w和偏置b,控制在范围[-1,1]中
w1 = rands(hidden_layer_25,input_layer_24); % 生成一个24*25的随机矩阵,因为输入向量为1*24,因此矩阵M1(1*24)*M2(24*25) = M(1*25)符合隐藏层的维度
b1 = rands(hidden_layer_25,1); % 生成25*1的随机矩阵作为第一级的偏置bias
w2 = rands(hidden_layer_25,output_layer_4); %生成25*4的随机矩阵,保证输出向量的维度是4维
b2 = rands(1 , output_layer_4); % 生成1*4的随机矩阵,与输出向量维度匹配(4D)
% 确定模型的学习率
L_rate = 0.1;
%% 大循环开始训练数据
for time = 1:100 % time为训练的总次数,即本训练需要完成10轮
E(time) = 0; %记录每一轮的总误差,以便训练完成后进行误差可视化
for sample_num = 1:1500
X_sample = input_training(sample_num , :);
sample_feature = input_training(sample_num , :); % 取出训练集其中一个样本的特征向量作为输入1*24
% simple_in_hidden:1 * 25,simple_out_hidden:1 * 25
for knot = 1 : hidden_layer_25
sample_in_hidden(knot) = sample_feature * w1(knot, : )' + b1(knot); % 计算得到hidden_layer的输入向量,大小为1*25
sample_out_hidden(knot) = 1/(1+exp(-sample_in_hidden(knot))); % 计算得到输出隐藏层的向量(用Sigmoid函数对输入向量进行处理),大小为1*25
end
sample_in_output = sample_out_hidden * w2 + b2; % 计算得到output向量,大小为1 * 4
error = output_training(sample_num , :)'- sample_in_output'; %得到误差向量error,大小为4*1
E(time) = E(time) + sum(abs(error));
GD_dw2 = error * sample_out_hidden ; % 利用梯度下降法对平方损失函数对为w2求偏导,大小为:4*25
GD_db2 = error; % 利用梯度下降法将平方损失函数对b2求偏导:大小4*1
% 计算每个结点的Sigmoid函数输出+Sigmoid导数输出,得到导数输出向量Sigmoid_de,大小为1*25
for j_knot = 1 : hidden_layer_25
Sigmoid = 1/(1+exp(-sample_in_hidden(j_knot)));
Sigmoid_de(j_knot) = Sigmoid * (1 - Sigmoid);
end
for j_knot = 1 : hidden_layer_25
error_w2 = error(1)*w2(j_knot,1)+error(2)*w2(j_knot,2)+error(3)*w2(j_knot,3)+error(4)*w2(j_knot,4);
for x_input = 1 : input_layer_24
GD_dw1(x_input,j_knot) = error_w2 * X_sample(x_input) * Sigmoid_de(j_knot);
end
GD_db1(j_knot) = error_w2 * Sigmoid_de(j_knot); %GD_db1大小为1*25
end
% Gradient_Decent梯度下降更新参数值
% 参数w1(25*24),b1(1*25),w2(25*4),b2(4*1)
w1 = w1 + L_rate * GD_dw1';
b1 = b1 + L_rate * GD_db1';
w2 = w2 + L_rate * GD_dw2';
b2 = b2 + L_rate * GD_db2';
end
end
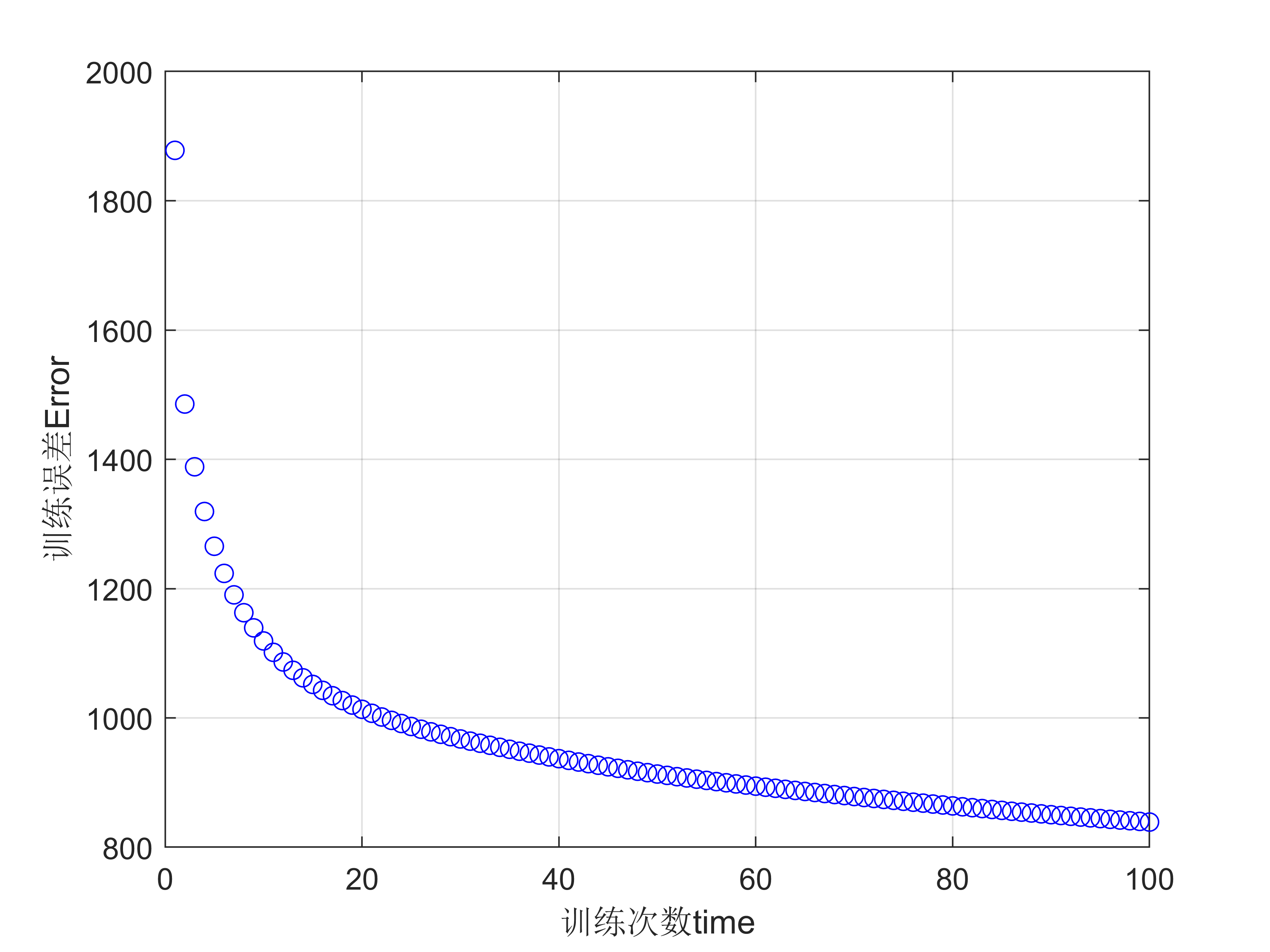
%% 进行误差可视化,作出E(time)和训练次数time之间的曲线图
figure(1);
time = 1 : 100;
plot(time , E , "bo");
xlabel("训练次数time");
ylabel("训练误差Error");
grid on;
%% 对测试集进行归一化处理:已在feature矩阵中统一操作,此步骤可以直接省略
%% 进行测试集测试
for ii = 1:1 %仅测试一轮
for test_num = 1 : 500 %对500个测试样本进行测试
for Knot_j = 1 : hidden_layer_25 % 计算隐藏层每个结点的输出和输出
test_hidden_input(Knot_j) = input_test(test_num,:) * w1(Knot_j,:)'+b1(Knot_j); % 得到test_hidden_input大小为1*25
test_hidden_output(Knot_j) = 1 / (1 + exp( -test_hidden_input(Knot_j))); % 得到test_hidden_output大小为1*25
end
forecast(:,test_num) = (test_hidden_output * w2 + b2)'; % 得到预测矩阵大小为4*500
end
end
%% 计算模型误差+作图
% 将预测矩阵转化成分类输出向量
for test_index = 1:500
for class = 1 : 4
output_forecast(test_index) = find(forecast(:,test_index) == max(forecast(:,test_index)));
end
end
output_test_goal = label(index(1501:2000),1)';
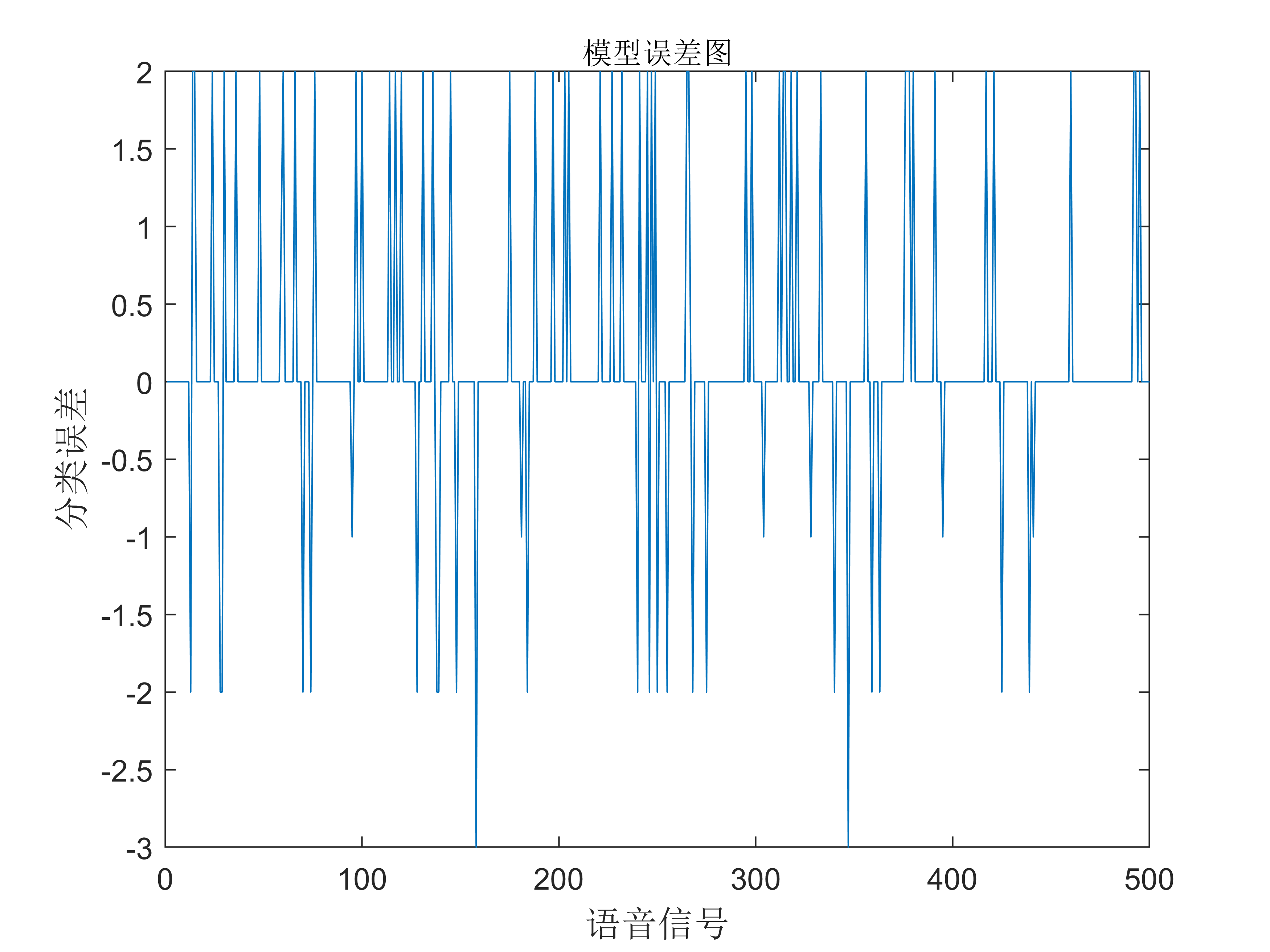
test_error = output_forecast - output_test_goal; % test_error向量大小为1*500
figure(2)
plot(test_error)
title("模型误差图",'fontsize',10)
xlabel('语音信号','fontsize',12)
ylabel('分类误差','fontsize',12)
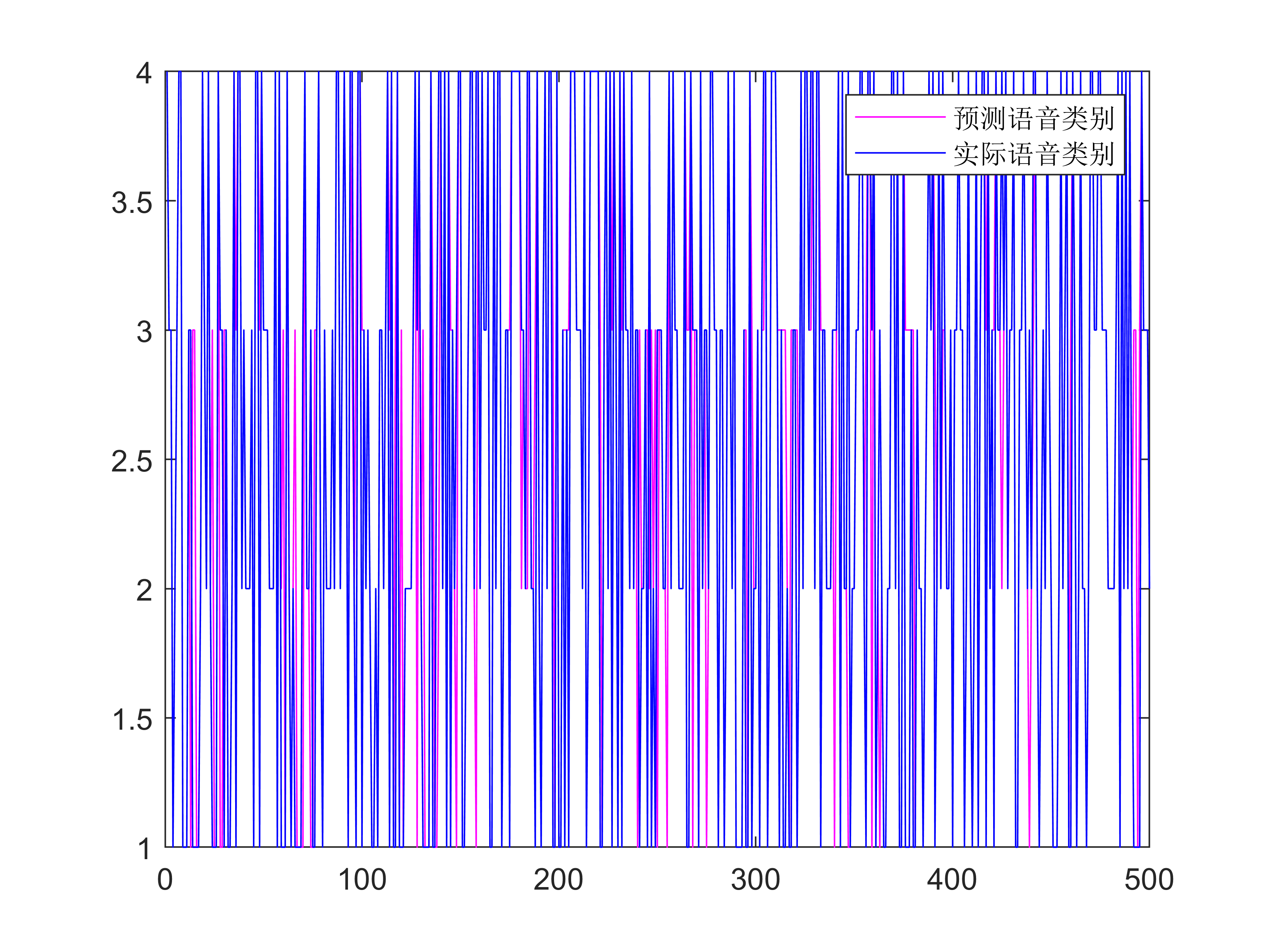
figure(3)
plot(output_forecast,"m")
hold on
plot(output_test_goal,"b")
legend('预测语音类别','实际语音类别')
%% 统计错误数+计算准确率
% 每一类的统计数
class_fault = zeros(1,4);
for test_index = 1:500
if test_error(test_index) ~= 0
[max_ele,max_index] = max(output_test(test_index , :));
switch max_index
case 1
class_fault(1) = class_fault(1) + 1 ;
case 2
class_fault(2) = class_fault(2) + 1 ;
case 3
class_fault(3) = class_fault(3) + 1 ;
case 4
class_fault(4) = class_fault(4) + 1 ;
end
end
end
% 每一类的样本数统计
class_sum = zeros(1,4);
for output_index = 1:500
switch output_test_goal(output_index)
case 1
class_sum(1) = class_sum(1) + 1 ;
case 2
class_sum(2) = class_sum(2) + 1 ;
case 3
class_sum(3) = class_sum(3) + 1 ;
case 4
class_sum(4) = class_sum(4) + 1 ;
end
end
% 准确率矩阵
rightrate = (class_sum - class_fault)./ class_sum
rightrate_total = 1 - sum(class_fault)/sum(class_sum)
3.结果分析
3.1 训练100次
| 次数 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 正确率 | 0.8300 | 0.8460 | 0.8580 | 0.8600 | 0.8480 |
| 次数 | 6 | 7 | 8 | 9 | 10 |
| 正确率 | 0.8400 | 0.8700 | 0.8800 | 0.8480 | 0.8460 |
平均正确率:0.8526
3.2 运行结果图片
3.3 其他——数据归一化的作用
- 归一化代码:
[target_Matrix,ps] = mapminmax(M)
3.3.1 归一化&不归一化的训练结果差异
1.删掉归一化代码运行结果:
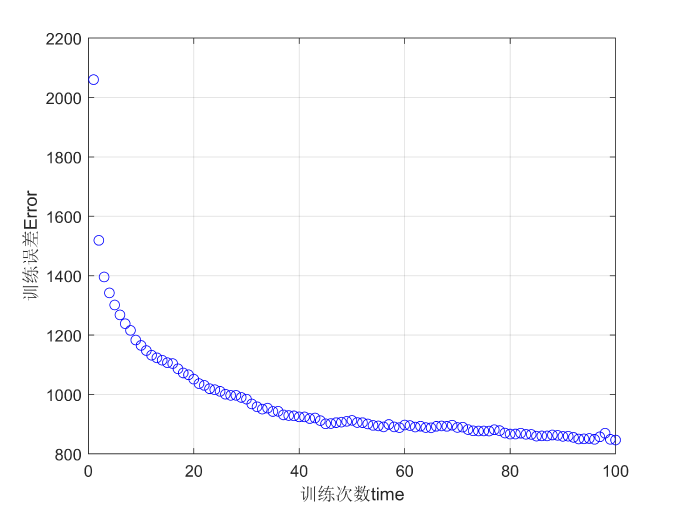
2.保留归一化代码运行结果
- 归一化代码:
[target_Matrix,ps] = mapminmax(M)
3.3.1 归一化&不归一化的训练结果差异
1.删掉归一化代码运行结果:
[外链图片转存中…(img-NZRs6HiY-1658219893677)]
2.保留归一化代码运行结果

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)