
深入理解 Spark(一)spark 运行模式简介与启动流程源码分析
目前在大数据离线计算、批处理场景下,计算引擎基本上被 spark 一统天下。大数据技术日趋成熟的今天,从业者仍然会不时地对这些开源框架的原理进行剖析与温习,温故知新,推陈出新,革故鼎新。本章节介绍了 spark 的常见的几种运行模式,并以 standalone 为例剖析了启动流程源码。读者一方面可以了解到 spark 作业的运行过程,另一方面可以加深对 spark 框架的了解程度。
·
spark 的运行模式
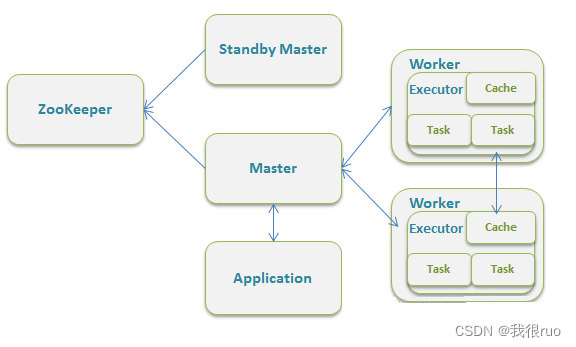
standalone 模式
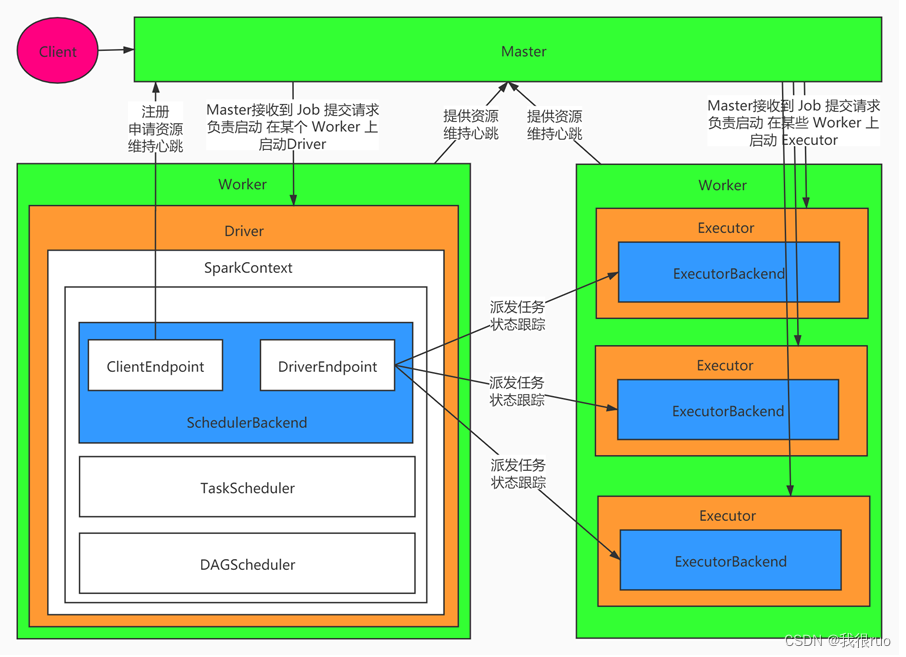
以 standalone-client 为例,运行过程如下:
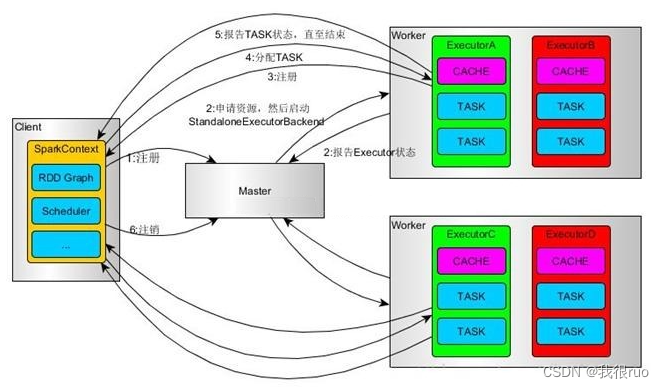
- SparkContext 连接到 Master,向 Master 注册并申请资源(CPU Core 和 Memory);
- Master 根据 SparkContext 的资源申请要求和 Worker 心跳周期内报告的信息决定在哪个 Worker 上分配资源,然后在该 Worker 上获取资源,然后启动 StandaloneExecutorBackend;
- StandaloneExecutorBackend 向 SparkContext 注册;
- SparkContext 解析 Applicaiton 代码,构建 DAG 图,并提交给 DAG Scheduler 分解成 Stage(当碰到 Action 操作时,就会催生 Job;每个 Job 中含有 1 个或多个 Stage,Stage 一般在获取外部数据和 shuffle 之前产生),然后以 Stage(或者称为 TaskSet)提交给 Task Scheduler,Task Scheduler 负责将 Task 分配到相应的 Worker,交给 StandaloneExecutorBackend 执行;
- StandaloneExecutorBackend 会建立 Executor 线程池,开始执行 Task,并向 SparkContext 报告,直至 Task 完成;
- 所有 Task 完成后,SparkContext 向 Master 注销,释放资源。
yarn 模式
yarn-client 模式
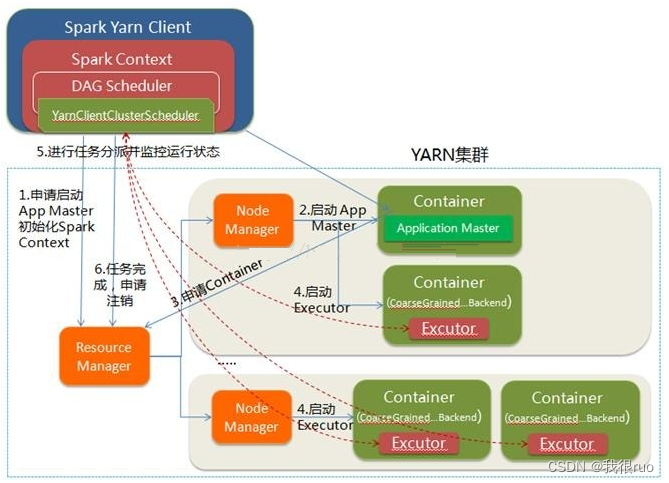
- Spark Yarn Client 向 YARN 的 ResourceManager 申请启动 ApplicationMaster。同时在 SparkContent 初始化中将创建 DAGScheduler 和 TaskScheduler 等。由于我们选择的是 Yarn-Client 模式,程序会选择 YarnClientClusterScheduler 和 YarnClientSchedulerBackend。
- ResourceManager 收到请求后,在集群中选择一个 NodeManager,为该应用程序分配第一个 Container,要求它在这个 Container 中启动应用程序的 ApplicationMaster。与 YARN-Cluster 的区别在在于该 ApplicationMaster 不运行 SparkContext,只与 SparkContext 进行联系进行资源的分派。
- Client 中的 SparkContext 初始化完毕后,与 ApplicationMaster 建立通讯,向 ResourceManager 注册,根据任务信息通过 ApplicationMaster 向 ResourceManager 申请资源(Container)。
- 一旦 ApplicationMaster 申请到资源(也就是 Container)后,便与对应的 NodeManager 通信,要求它在获得的 Container 中启动 CoarseGrainedExecutorBackend。CoarseGrainedExecutorBackend 启动后会向Client 中的 SparkContext 反向注册并申请 Task。
- client 中的 SparkContext 分配 Task 给 CoarseGrainedExecutorBackend 执行,CoarseGrainedExecutorBackend 运行 Task 并向 Driver 汇报运行的状态和进度,以让 Client 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,Client 的 SparkContext 向 ResourceManager 申请注销并关闭自己。
yarn-cluster 模式
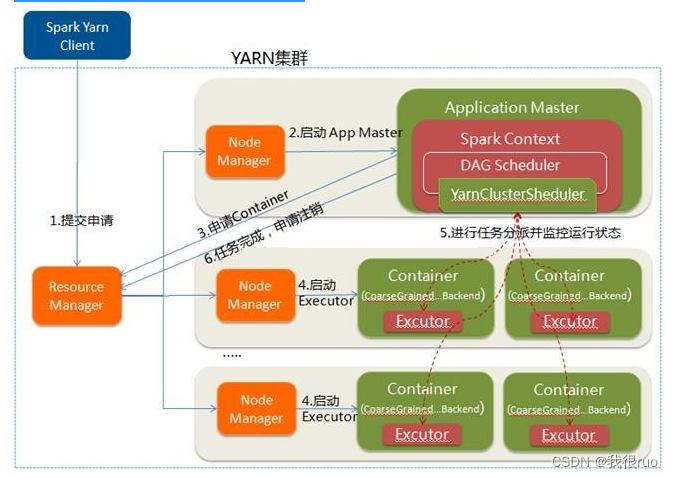
- Spark Yarn Client 向 YARN RM 提交应用程序,包括 ApplicationMaster 程序、启动 ApplicationMaster 的命令、需要在 Executor 中运行的程序等。
- ResourceManager 收到请求后,在集群中选择一个 NodeManager,为该应用程序分配第一个 Container,要求它在这个 Container 中启动应用程序的 ApplicationMaster,其中 ApplicationMaster 进行 SparkContext 等的初始化。
- ApplicationMaster 向 ResourceManager 注册,这样用户可以直接通过 ResourceManage 查看应用程序的运行状态,然后它将采用轮询的方式通过 RPC 协议为各个任务申请资源,并监控它们的运行状态直到运行结束。
- 一旦 ApplicationMaster 申请到资源(也就是 Container)后,便与对应的 NodeManager 通信,要求它在获得的 Container 中启动 CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend 启动后会向 ApplicationMaster 中的 SparkContext 注册并申请 Task。这一点和 Standalone 模式一样,只不过 SparkContext 在 Spark Application 中初始化时,使用 CoarseGrainedSchedulerBackend 配合 YarnClusterScheduler 进行任务的调度,其中 YarnClusterScheduler 只是对 TaskSchedulerImpl 的一个简单包装,增加了对 Executor 的等待逻辑等。
- ApplicationMaster 中的 SparkContext 分配 Task 给 CoarseGrainedExecutorBackend 执行,CoarseGrainedExecutorBackend 运行 Task 并向 ApplicationMaster 汇报运行的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 申请注销并关闭自己。
Spark Client 和 Spark Cluster 的区别
- 理解 YARN-Client 和 YARN-Cluster 深层次的区别之前先清楚一个概念:ApplicationMaster。在 YARN 中,每个 Application 实例都有一个 ApplicationMaster 进程,它是 Application 启动的第一个容器。它负责和 ResourceManager 打交道并请求资源,获取资源之后告诉 NodeManager 为其启动 Container。从深层次的含义讲 YARN-Cluster 和 YARN-Client 模式的区别其实就是 ApplicationMaster 进程的区别。
- YARN-Cluster 模式下,Driver 运行在 AM(Application Master) 中,它负责向 YARN 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 YARN 上运行,因而 YARN-Cluster 模式不适合运行交互类型的作业。
- YARN-Client 模式下,Application Master 仅仅向 YARN 请求 Executor,Client 会和请求的 Container 通信来调度他们工作,也就是说 Client 不能退出。
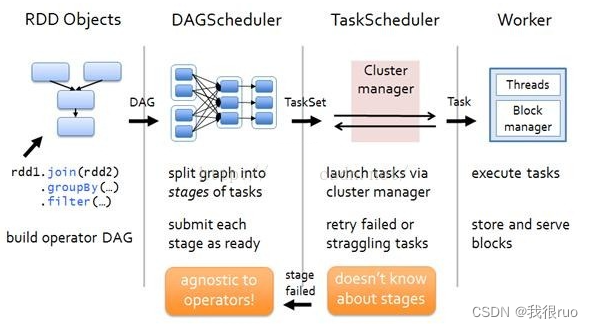
spark 当中 RDD 的运行流程
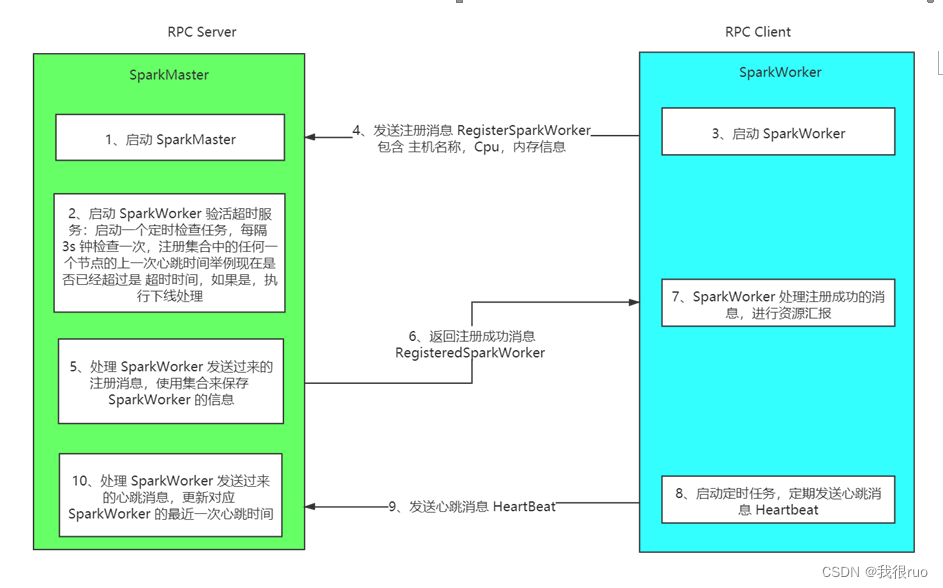
spark standalone 集群通信框架
体系架构
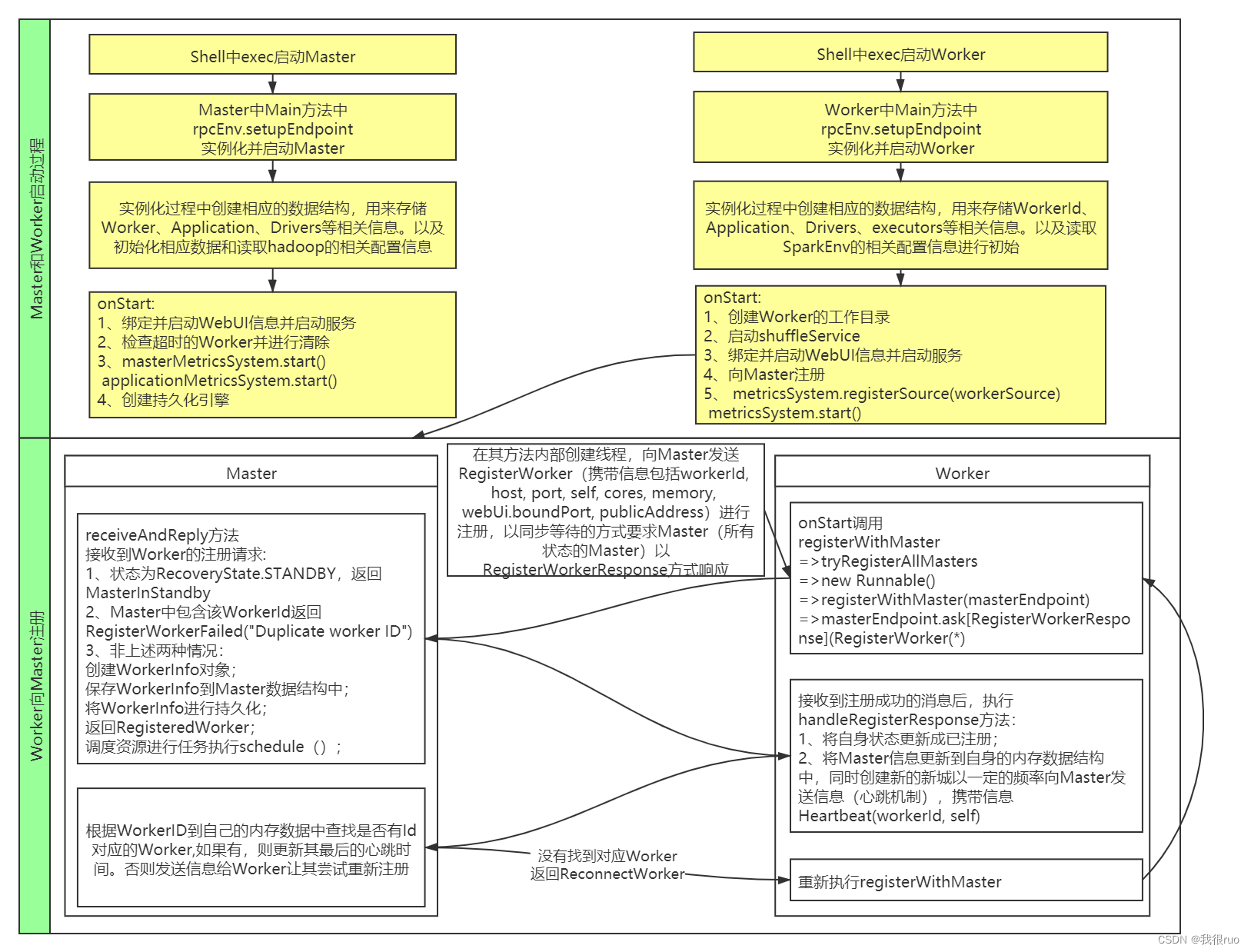
启动过程
基于 netty 的 spark RPC 类继承结构
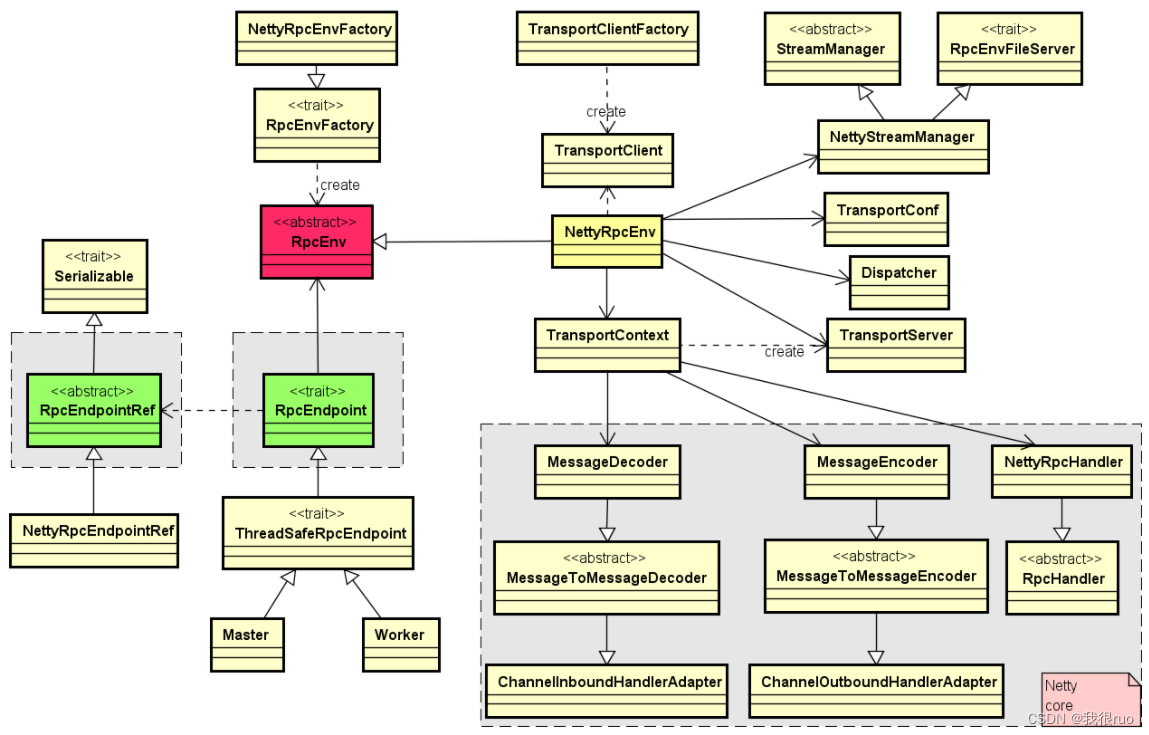
- 核心的 RpcEnv 是一个特质(trait),它主要提供了停止,注册,获取 endpoint 等方法的定义,而 NettyRpcEnv 提供了该特质的一个具体实现。
- 通过工厂 RpcEnvFactory 来产生一个 RpcEnv,而 NettyRpcEnvFactory 用来生成 NettyRpcEnv 的一个对象。
- 当我们调用 RpcEnv 中的 setupEndpoint 来注册一个 endpoint 到 rpcEnv 的时候,在 NettyRpcEnv 内部会将该 endpoint 的名称与其本身的映射关系,rpcEndpoint 与rpcEndpointRef 之间映射关系保存在 dispatcher 对应的成员变量中。
1. TransportContext 内部包含:TransportConf 和 RpcHandler
2. TransportConf 在创建 TransportClientFactory 和 TransportServer 都是必须的
3. RpcHandler 只用于创建 TransportServer
4. TransportClientFactory 是 Spark RPC 的客户端工厂类实现
5. TransportServer 是 Spark RPC 的服务端实现。创建的时候,需要 TransportContext 中的 TransportConf 和 RpcHandler。在 init 初始化的时候,由 TransportServerBootStrap 引导启动。
6. TransportClient 是 Spark RPC 的客户端实现。由 TransportClientFactory 创建,TransportClientFactory 在实例化的时候需要 TransportConf。TransportClient 创建好了之后,需要通过 TransportClientBootstrap 引导启动,创建好的 TransportClient 都会被维护在 TransportClientFactory 的 ClientPool 中。
7. ClientPool 是 TransportClientFactory 的内部组件,维护 TransportClient clientPool 池。TransportClientFactory 最重要的两个东西:
1、提供了一个创建 RPC Client 的方法
2、提供了一个管理 RPC Client 的组件
8. TransportServerBootStrap 是 Spark RPC 服务端 引导程序
9. TransportClientBootstrap 是 Spark RPC 客户端 引导程序
10. MessageEncoder 和 MessageDecoder 编解码器,存在于 TransportContext 的内部。可以集成多种不同的序列化机制。

spark standalone 集群启动脚本分析
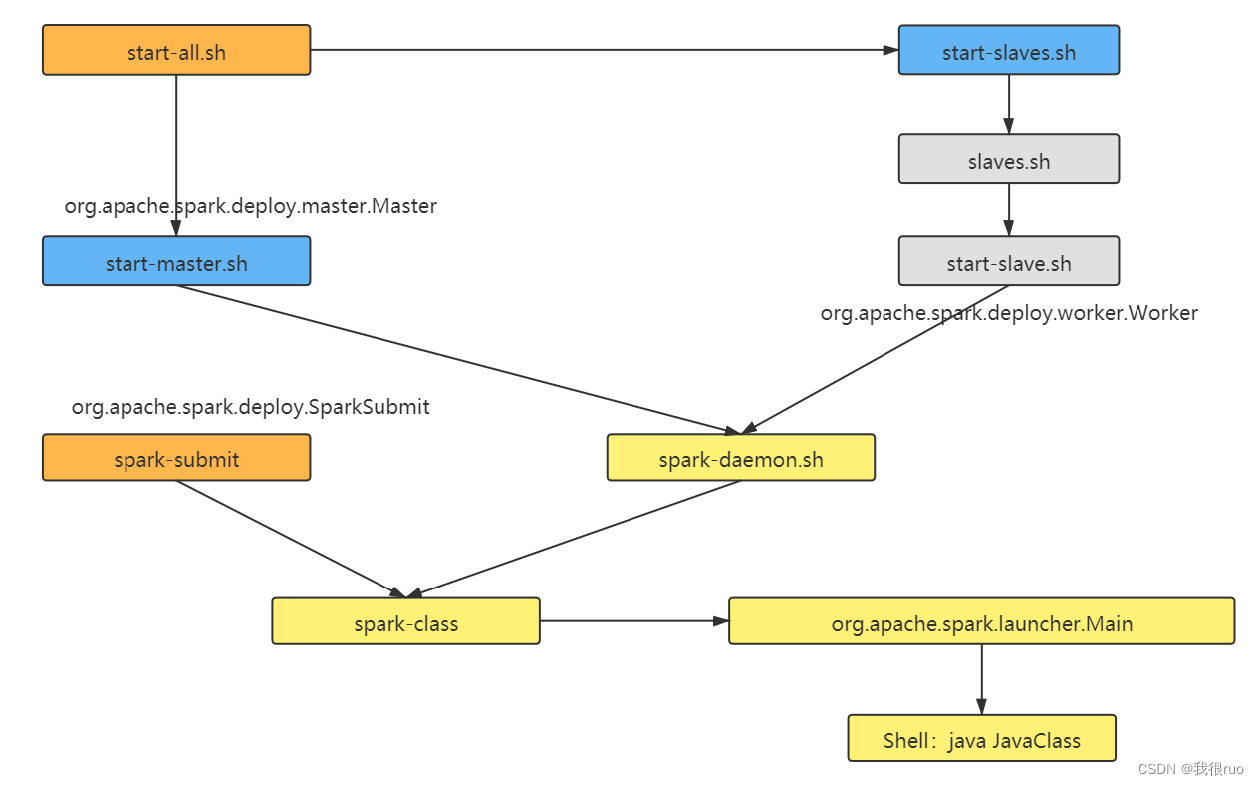
spark standalone 集群启动过程分析

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)