
【深度学习技术系列】Bert生成向量实践
对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(Transformer|peft|accelerate)、教程等。社区HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。刚开始
·
1. 环境准备
- 安装transformers库
pip3 install transformers
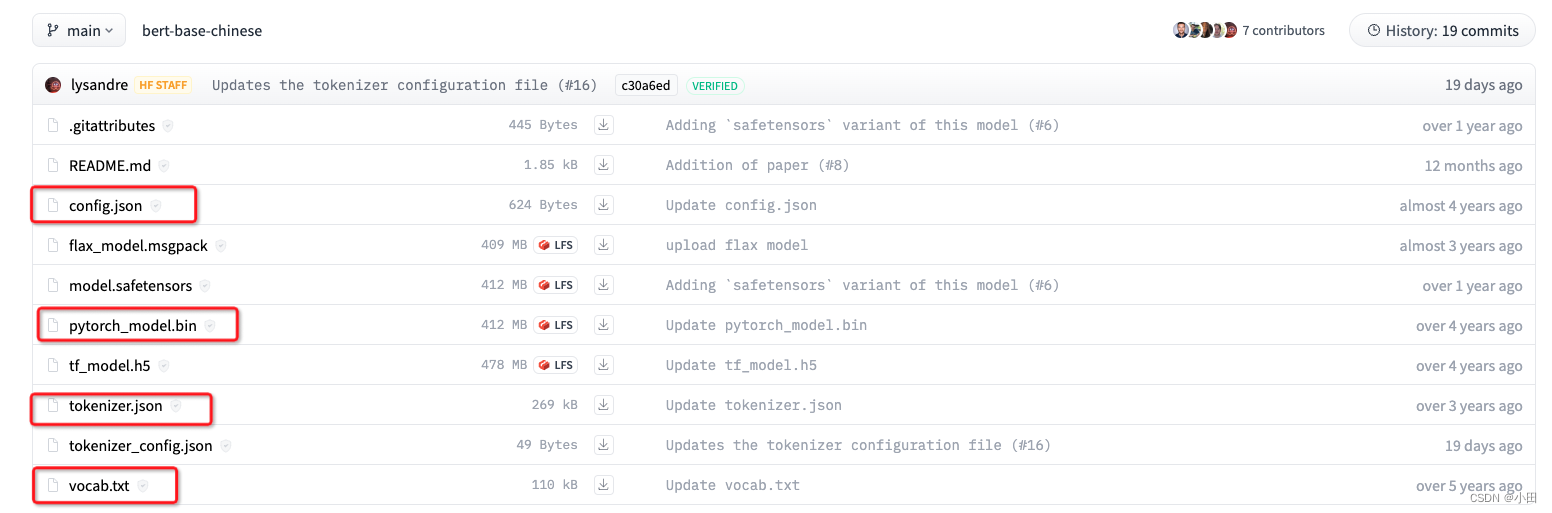
- 下载预训练模型 bert-base-chinese 通过 Models - Hugging Face下载
下载完成之后是这样

- 安装anacoda download中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
- 安装pytorch
接着进入pytorch官网,链接: 官网. 到开之后选取下图所示的osx即可,(windows)不带gpu的也就是没有cuda可以选择cpu only 那一行。

验证是否OK
import torch
print(torch.__version__)
print('gpu:', torch.cuda.is_available())
- 安装pytorch-transformers
pip3 install pytorch-transformers
简而言之就是一个目前用于自然语言处理(NLP)的最先进的预训练模型库。该库目前包含了如下列所示模型的PyTorch实现、预训练模型权重、使用脚本和下列模型的转换工具:Bert、GPT、GPT-2、Transformer-XL、XLNet、XLM
2. HuggingFace简介
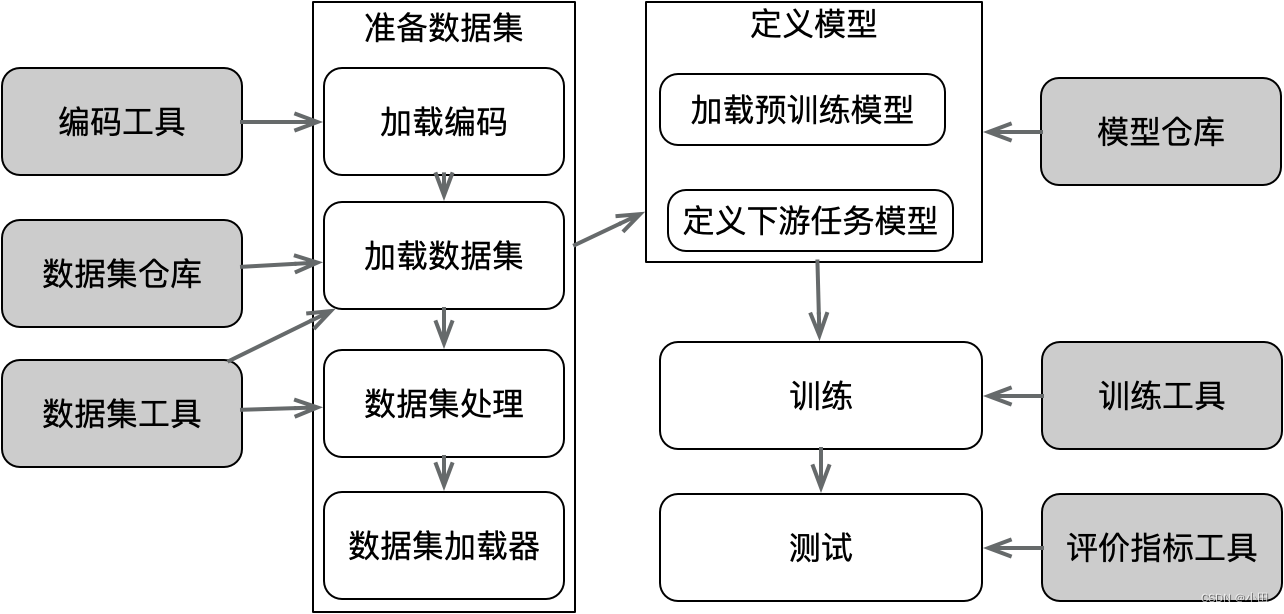
对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(Transformer|peft|accelerate)、教程等。HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试,如下图所示:
- 社区
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。刚开始大多数的模型和数据集是NLP方向的,但图像和语音的功能模型正在快速更新中。 - GitHub
可以看到包括常用的transformers、datasets、diffusers、accelerate、pef和optimum类库:
[1] Hugging Face博客:https://huggingface.co/blog/zh
[2] Hugging Face GitHub:https://github.com/huggingface/
3. 模型运用
以下示例:利用Bert序列预训练好的模型 bert-base-chinese ,将两个句子的特征提取出来,得到一个二维向量,每一维度32dim。
import torch
import pytorch_transformers
from pytorch_transformers import BertModel, BertConfig, BertTokenizer
from torch import nn
# 自己下载模型相关的文件,并指定路径
config_path = 'bert-base-chinese/config.json'
model_path = 'bert-base-chinese/pytorch_model.bin'
vocab_path = 'bert-base-chinese/vocab.txt'
# ——————构造模型——————
# 在BertModel后面加上一个全连接层,能够调整输出feature的维度。
class BertTextNet(nn.Module):
def __init__(self, code_length): # code_length为fc映射到的维度大小
super(BertTextNet, self).__init__()
# 使用pytorch_transformers本身提供的预训练BertConfig,以及加载预训练模型
modelConfig = BertConfig.from_pretrained(config_path)
self.textExtractor = BertModel.from_pretrained(model_path, config=modelConfig)
embedding_dim = self.textExtractor.config.hidden_size
self.fc = nn.Linear(embedding_dim, code_length)
self.tanh = torch.nn.Tanh()
def forward(self, tokens, segments, input_masks):
output = self.textExtractor(tokens, token_type_ids=segments, attention_mask=input_masks)
# outputs[0] 把输入到BertModel后得到的输出output,一般是使用它的第0维信息。
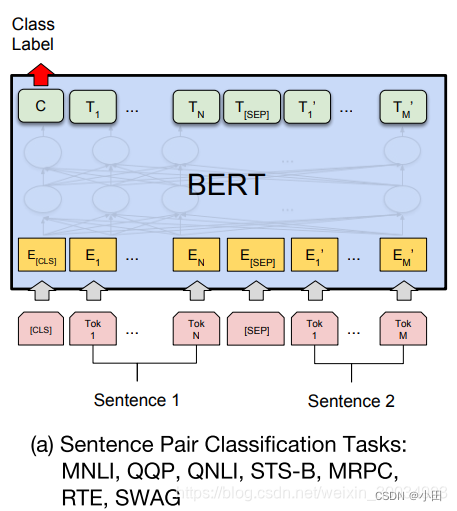
text_embeddings = output[0][:, 0, :] # 代表图中的C的输出向量
# output[0](batch size, sequence length, model hidden dimension)
features = self.fc(text_embeddings)
features = self.tanh(features)
return features
textNet = BertTextNet(code_length=32)
# ——————用BertTokenizer对输入文本进行处理,从预训练模型中加载tokenizer——————
tokenizer = BertTokenizer.from_pretrained(vocab_path)
texts = ["[CLS] 今天天气不错,适合出行。 [SEP]",
"[CLS] 今天是晴天,可以出去玩。 [SEP]"]
tokens, segments, input_masks = [], [], []
for text in texts:
tokenized_text = tokenizer.tokenize(text) # 用tokenizer对句子分词
print(tokenized_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text) # 索引列表,将词转换为整形
print(indexed_tokens)
tokens.append(indexed_tokens) # 将每一个token 加进去
segments.append([0] * len(indexed_tokens))
print(segments)
input_masks.append([1] * len(indexed_tokens))
print(input_masks)
max_len = max([len(single) for single in tokens]) # 最大的句子长度
print(max_len)
for j in range(len(tokens)):
padding = [0] * (max_len - len(tokens[j]))
tokens[j] += padding
segments[j] += padding
input_masks[j] += padding
# segments列表全0,因为只有一个句子1,没有句子2
# input_masks列表1的部分代表句子单词,而后面0的部分代表paddig,只是用于保持输入整齐,没有实际意义。
# 相当于告诉BertModel不要利用后面0的部分
# 转换成PyTorch tensors
tokens_tensor = torch.tensor(tokens)
segments_tensors = torch.tensor(segments)
input_masks_tensors = torch.tensor(input_masks)
# ——————提取文本特征——————
text_hashCodes = textNet(tokens_tensor, segments_tensors, input_masks_tensors) # text_hashCodes是一个32-dim文本特征
print(text_hashCodes)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)