

一、spark简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
二、spark编译
为什么cdh提供了spark已经编译好的包,还要自己手工编译?因为从spark某个版本之后,就不再集成hadoop相关的jar包了,这些jar包需要自己来指定路径,并且除了hadoop的jar包外,还有FastJson,Hbase等许许多多jar包需要自己指定,很麻烦,所以再三考量,决定还是自己手工编译spark。
1.安装scala 2.10.4
这个从scala官网上下载压缩包到linux,解压缩,配置好环境变量,即可,非常easy
2.下载spark1.6.0-cdh5.11.1源码包
http://archive.cloudera.com/cdh5/cdh/5/
同样是从这个网站下载源码包
解压
配置make-distribute.sh文件,修改:
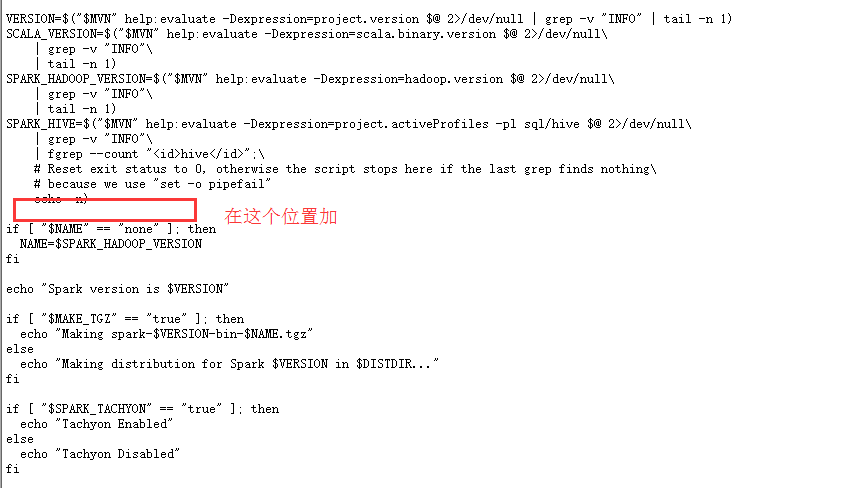
把脚本里的VERSION,SCALA_VERSION,SPARK_HADOOP_VERSION,SPARK_HIVE四个参数的定义注释掉,因为这会花费大量的时间来获取到,并且添加下面的内容:
3.修改pom.xml文件

修改一下最前面定义的scala.version的版本号,改成2.10.4
4.上传必要的编译的东西到build目录下
一是scala解压缩之后的包,zinc解压缩后的包
zinc可在这个地址下下载:
http://downloads.typesafe.com/zinc/0.3.5.3/zinc-0.3.5.3.tgz
结果如下:

5.修改maven配置文件的settings.xml,加入阿里云的镜像
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
6.开始编译
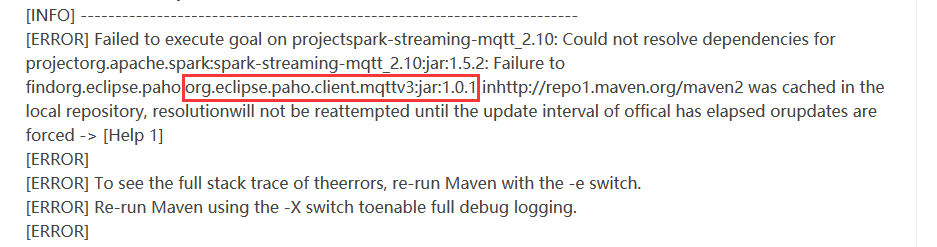
说是找不到这个包,于是去maven仓库中手动下载所有的文件,复制到本地的仓库,即可:
1.把这个文件夹下的内容都下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/
之后,在本地maven仓库中,建立org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/这个目录,把文件拷贝到这个目录下
2.把这个文件夹下的内容下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/java-parent/1.0.1/
同样在本地建立org/eclipse/paho/java-parent/1.0.1/文件夹,把下载的东西复制到这即可
重新编译
8.漫长的等待,因为需要下载许多的jar包,务必这次编译成功后,把maven库打包备份一份,下次使用
9.之后,在本地可以看到一个编译好的tar包,这个就是spark的安装包
三.spark集群环境搭建
解压缩spark包,配置conf
重命名spark-env.sh.template为spark-env.sh,加入以下配置
JAVA_HOME=/home/hadoop/app/jdk
SCALA_HOME=/home/hadoop/app/scala
HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop
HADOOP_HOME=/home/hadoop/app/hadoop
## 这里不同的机器不同的配置
SPARK_LOCAL_IP=hadoop001
SPARK_MASTER_IP=hadoop001
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g 注意,SPARK_LOCAL_IP是本地的地址,不同的机器,这个配置需要改正哦
修改slaves
这里放入所有的worker节点
hadoop002
hadoop003
即可
先启动本地
bin/spark-shell
如果没有问题,那么可以启动集群了
sbin/start-all.sh
进入hadoop001:7077访问,即可看到spark的监控界面







 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)