
性能测试——Locust框架、Linux压力测试命令ab、nmon工具
1.Locust是一个开源的性能测试工具,主要思想就是模拟一群用户访问你的系统。1.1locust里发送请求是基于requests实现的,请求方法、参数、响应对象和requests使用方式一样。# 登录# 首页# 获取商品信息# 加入购物车2.2定义一个用户行为(任务集),包含多个具体的任务。如何定义?一个用户行为类,要继承TaskSet类,表示一个任务集on_start:前置方法(前置任务)
LoadRunner
是非常有名的商业性能测试工具,功能非常强大。使用也比较复杂,但收费贼贵
Jmeter
同样是非常有名的开源性能测试工具,功能也很完善。可以当做接口测试工具来测试接口,但同时它也是一个标准的性能测试工具
Locust
功能上虽然不如LoadRunner及Jmeter丰富,但其也有不少优点。Locust 完全基本 Python 编程语言并且 HTTP 请求完全基于 Requests 库。
LoadRunner 和 Jmeter 这类采用进程和线程的测试工具,都很难在单机上模拟出较高的并发压力。Locust 的并发机制摒弃了进程和线程,采用协程(gevent)的机制。协程避免了系统级资源调度,由此可以大幅提高单机的并发能力。
Locust介绍和安装
1. Locust简介
Locust是一个开源的性能测试工具,主要思想就是模拟一群用户访问你的系统。
1.1 特点
在代码中定义用户行为
不需要安装笨重的软件,只是简单的Python代码
分布式和可扩展
Locust支持在多台机器上的运行负载测试,因此可用于模拟数百万用户的请求
经过验证和战斗测试
Locust被用于许多真实的项目中
Locust有一个整洁的HTML+JS的用户界面,实时显示相关测试细节
由于用户界面是基于网络的,它是跨平台的和容易扩展
2. Locust安装
安装命令:pip install locustio==2.17.0
Locust使用
1. 案例演示环境说明
某系统包含以下接口:
1.登录
URL:http://182.92.81.159:1880/bms/login
请求方式:POST
请求参数:{"username": "admin", "password": "123456"}
2.首页
URL:http://182.92.81.159:1880/bms/index
请求方式:GET
3.获取用户信息
URL:http://182.92.81.159:1880/bms/profile
请求方式:GET
4.退出
URL:http://182.92.81.159:1880/bms/logout
请求方式:POST
2. 编写测试脚本
实现步骤:
定义任务(接口请求)
定义任务集(用户行为)
定义Locust类(用户)

2.1 定义任务
locust里发送请求是基于requests实现的,请求方法、参数、响应对象和requests使用方式一样。
def index(l):
l.client.get("/index")
def login(l):
l.client.post("/login", data={"username": "admin", "password": "123456"})
# 登录
def login(l):
l.client.post("/wx/auth/login",data={"username":"user123","password":"user123"})
# 首页
def index(l):
l.client.get("/wx/home/index")
# 获取商品信息
def goods_detail(l):
l.client.get("/wx/goods/detail?id=118100")
# 加入购物车
def cart_add(l):
l.client.post("/wx/cart/add",data={"goodsId":1181000,"number":1,"productId":2})
2.2 定义任务集
定义一个用户行为(任务集),包含多个具体的任务。
from locust import TaskSet
class UserBehavior(TaskSet):
tasks = {index: 3, profile: 1}
def on_start(self):
login(self)
def on_stop(self):
logout(self)如何定义? 一个用户行为类,要继承TaskSet类,表示一个任务集 on_start:前置方法(前置任务),在所有任务之前调用 on_stop:后置方法(后置任务),当任务集停止时调用 tasks:用来添加任务,它是一个dict类型,key表示任务的方法名,value表示挑选执行的权重,数值越大执行频率越高

from locust import TaskSet
# 定义任务集
class UserBehavior(TaskSet):
tasks = [4,1]
def on_start(self):
login(self)
def on_stop(self):
cart_add(self)2.3 定义Locust类
定义一个Locust类,这个类代表用户。
from locust import HttpLocust
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 2000
max_wait = 3000
host = "http://182.92.81.159:1880/bms"
weight = 10如何定义? 自定义的Locust类继承了 HttpLocust 类,这个类代表用户,生成一个实例,模拟用户发送http请求 task_set:该属性指向 TaskSet 类,定义用户的行为 min_wait:用户执行任务之间等待时间的下界,单位:毫秒,默认值:1000 max_wait:用户执行任务之间等待时间的上界,单位:毫秒,默认值:1000 host:被测应用的网址,例如:http://localhost:8080/bms weight:用户被选中的概率,权重越大,被选中的机会就越大。默认值:10

from locust import HttpLocust
# 定义用户类
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 2000
max_wait = 3000
host = "http://www.litemall360.com:8080"
weight = 102.4 示例代码
from locust import HttpLocust, TaskSet
# 定义任务
# 登录
def login(l):
l.client.post("/wx/auth/login",data={"username":"user123","password":"user123"})
# 首页
def index(l):
l.client.get("/wx/home/index")
# 获取商品信息
def goods_detail(l):
l.client.get("/wx/goods/detail?id=118100")
# 加入购物车
def cart_add(l):
l.client.post("/wx/cart/add",data={"goodsId":1181000,"number":1,"productId":2})
# 定义任务集
class UserBehavior(TaskSet):
tasks = [4,1]
def on_start(self):
login(self)
def on_stop(self):
cart_add(self)
# 定义用户类
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000
host = "http://www.litemall360.com:8080"
weight = 10
3. 运行Locust2
运行命令:locust -f test.py --host=http://www.litemall360.com:8080
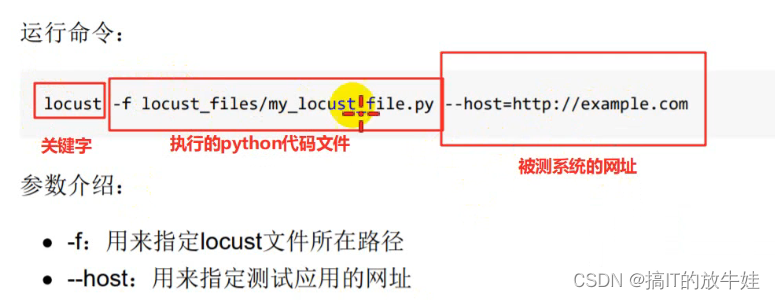
参数介绍: -f:用来指定locust文件所在路径 --host:用来指定测试应用的网址
Locust 2.17.0
# 单接口
from locust import HttpUser, task, between
import os
import webbrowser
class QuickstartUser(HttpUser):
# between模拟同一个用户前后操作的等待时间随机(1-5秒)
wait_time = between(1, 5)
# constant固定用户前后操作时间为5秒
# wait_time = constant(5)
"""压力脚本模板开始"""
@task(3) # 需要压测的接口都需要加task,后面的数据为权重,默认权重1
def login(self):
# 请求数据
data = {"username":"user123","password":"user123"}
# 请求地址
refresh_url = "/wx/auth/login"
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36",
"Content-Type": "application/json;charset=UTF-8"
}
# 开始模拟请求,“catch_response=True”为断言标记支持,如果不加,断言标记报错
with self.client.post(url=refresh_url, json = data,
headers = headers, catch_response=True) as refresh_res:
# 请求结束进入断言,断言方式与requests请求断言完全相同,根据需要编写。
if refresh_res.json()["errno"] == "0":
# 断言成功,标记成功
refresh_res.success()
else:
# 断言成功,标记失败
refresh_res.failure("失败")
"""压力脚本模板结束"""
def on_start(self):
# 点击开始压测时,所有用户都会去运行一次,如:用做模拟登录,采用self.client模拟登录接口
print("开始压测")
def on_stop(self):
# 点击stop时,所有用户都会去运行一次。
print("结束压测结束")
if __name__ == '__main__':
# 控制浏览器打开locust页面
webbrowser.open_new_tab('http://localhost:8089')
# 控制cmd执行locust,“test.py”为需要运行py脚本名字,“http://www.litemall360.com:8080”为压测服务器地址
os.system("locust -f test.py --host=http://www.litemall360.com:8080")
# 多接口
from locust import FastHttpUser, SequentialTaskSet, TaskSet, between, task
from geventhttpclient import HTTPClient #Nginx
from geventhttpclient.url import URL
import random, string, json, os, webbrowser
host = 'http://localhost:8000'
# 继承TaskSequence 控制方法按从上往下的顺序执行
class GetProductListSeqTaskSet(SequentialTaskSet):
header={}
del_params={}
def on_start(self):
# 点击开始压测时,所有用户都会去运行一次,如:用做模拟登录,采用self.client模拟登录接口
print("开始压测")
def on_stop(self):
# 点击stop时,所有用户都会去运行一次。
print("结束压测结束")
@task # 需要压测的接口都需要加task,后面的数据为权重,默认权重1
def Login(self):
self.header['content-type'] = "application/json;charset=UTF-8"
data = {"username": "user123", "password": "user123"}
login_url = "/wx/auth/login"
login_resp = self.client.post(url = login_url,json = data,
headers = self.header)
dict_login_complete = login_resp.json()
# print(dict_login_complete)
if dict_login_complete["errno"] == 0:
self.header['X-Litemall-Token'] = dict_login_complete.get("data").get("token")
# print(self.login_header)
print("登录成功")
else:
print("登录失败",dict_login_complete)
# 添加地址
@task
def Save_Address(self):
save_address_url = "/wx/address/save"
addre_data = {"name":"zhuwei","tel":"15678900987","country":"",
"province":"北京市","city":"市辖区","county":"东城区",
"areaCode":"110101","postalCode":"","addressDetail":"aaaaaaa",
"isDefault":"false"}
save_address_resp = self.client.post(url = save_address_url, json = addre_data, headers = self.header)
dict_addre_complete = save_address_resp.json()
if dict_addre_complete["errmsg"] == "成功":
print("添加地址成功")
else:
print("添加地址失败",dict_addre_complete)
# 加入购物车
@task
def Cart_Add(self):
add_cart_url = "/wx/cart/add"
add_cart_data = {"goodsId": 1181000, "number": 1, "productId": 2}
add_cart_resp = self.client.post(url = add_cart_url, json = add_cart_data, headers = self.header)
dict_cart_complete = add_cart_resp.json()
if dict_cart_complete["errmsg"] == "成功":
print("添加购物车成功")
else:
print("添加购物车失败",dict_cart_complete)
# 查看购物车
@task
def View_Cart(self):
view_cart_url = "/wx/cart/index"
view_cart_resp = self.client.get(url = view_cart_url, headers = self.header)
dict_view_cart_complet = view_cart_resp.json()
print(dict_view_cart_complet)
class TestPerformance(FastHttpUser):
tasks=[GetProductListSeqTaskSet,]
locust_task_weight = 10
# 定义虚拟用户执行每个task的间隔时间,1s到5s随机选一个值。
wait_time = between(1,10)
if __name__ == '__main__':
# 控制浏览器打开locust页面
webbrowser.open_new_tab('http://localhost:8089')
# 控制cmd执行locust,“test.py”为需要运行py脚本名字,“http://www.litemall360.com:8080”为压测服务器地址
os.system("locust -f test_01.py --host=http://www.litemall360.com:8080")3.1 打开Locust的web界面
使用上面的命令行启动Locust之后,打开浏览器并访问:http://localhost:8089 (如果你在本地运行Locust)。可以看到如下界
参数说明: Number of users to simulate:要模拟的用户数量 Hatch rate (users spawned/second):孵化率(用户生成/秒),即每秒启动虚拟用户数 点击Start swarming 开始运行性能测试

效果展示
设置虚拟用户数10,每秒启动2个用户,点击Start swarming 开始运行

界面说明: Type:请求类型 Name:请求路径 Requests:当前请求的数量 Fails:当前请求失败的数量 Median (ms):中间值,单位毫秒,一半服务器响应时间低于该值,而另一半高于该值 Average (ms):所有请求的平均响应时间,毫秒 Min (ms):请求的最小的服务器响应时间,毫秒 Max (ms):请求的最大服务器响应时间,毫秒 Average size (bytes):平均单个请求的大小,单位字节 Current RPS:每秒钟请求的个数 点击Edit可以编辑请求用户数 点击STOP按钮可以停止测试 点击New test可以重新开始测试
Charts图表展示
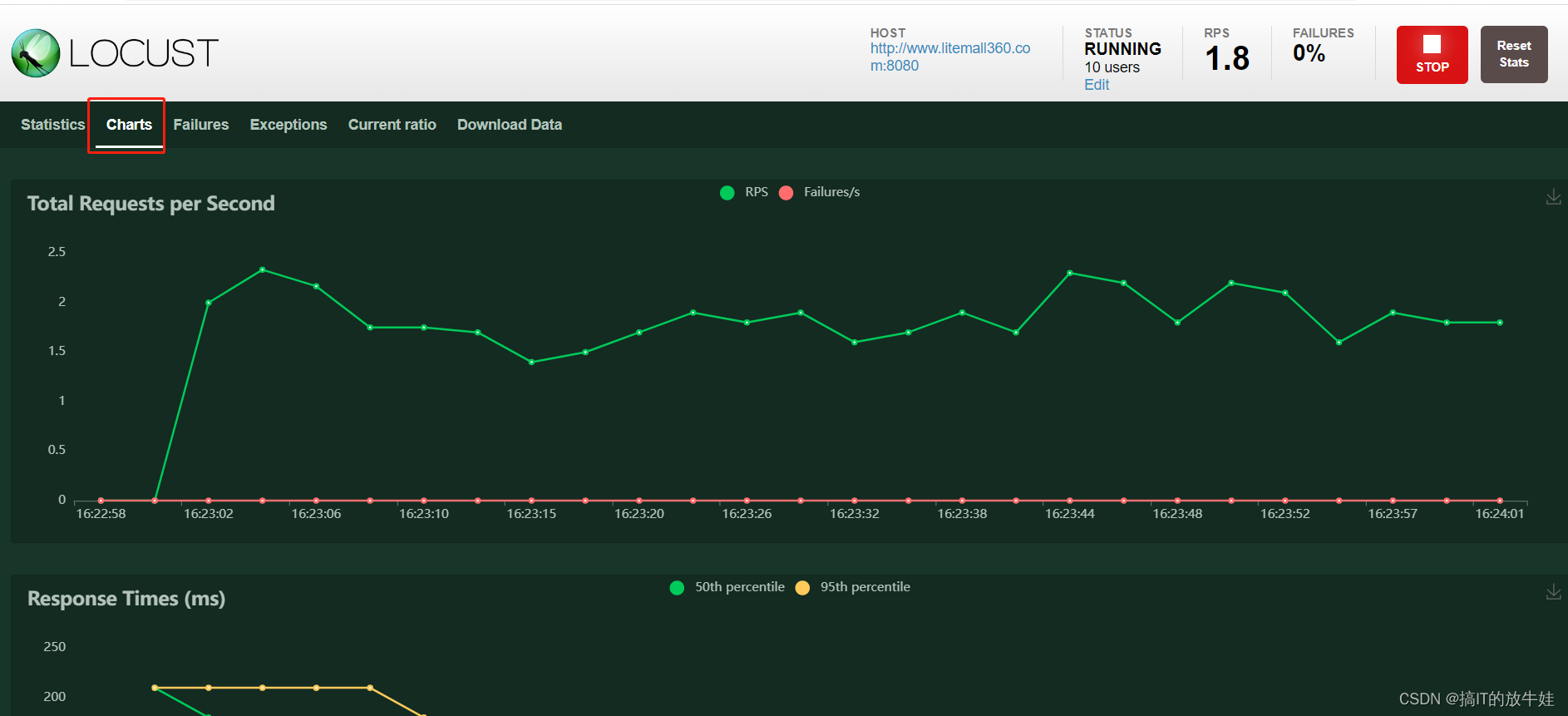
三个图标分别是: Total Requests per Second:每秒发送请求数 Response Times(ms):平均响应时间 Number of Users:虚拟用户数
Linux压力测试命令ab
参考文章
linux系统使用ab进行压力测试_linux ab压测-CSDN博客
ab命令全称为:Apache bench 。是Apache自带的压力测试工具。ab命令非常实用,它不仅可以对Apache服务器进行网站访问压力测试,也可以对或其它类型的服务器进行压力测试。可以测试安装Web服务器每秒种处理的HTTP请求。
ab命令缺点会给服务器造成非常高的负载,可能会造成目标服务器资源耗尽,严重时可能会导致死机,而且它没有图形化结果不能监控,所以只能用作临时紧急任务和简单的测试。
ab命令会创建多个并发线程,模拟多个访问者同时对某一个url地址进行访问,测试的目标基于url。安装httpd时,ab命令也会被同时安装,所以不需要再另行安装。
安装
yum -y install httpd-tools
在/apache-tomcat-7.0.56/bin使用ab命令
[root@localhost bin]# ab -n 100 -c 10 http://192.168.80.128:8080/(多有米前台为例)
-c10 表示并发用户数为10
-n100 表示请求总数为100
| -A | 指定连接服务器的基本的认证凭据 |
| -c | 指定一次向服务器发出请求数 |
| -C | 添加cookie |
| -g | 将测试结果输出为“gnuolot”文件 |
| -h | 显示帮助信息 |
| -H | 为请求追加一个额外的头 |
| -i | 使用“head”请求方式 |
| -k | 激活HTTP中的“keepAlive”特性 |
| -n | 指定测试会话使用的请求数 |
| -p | 指定包含数据的文件 |
| -q | 不显示进度百分比 |
| -T | 使用POST数据时,设置内容类型头 |
| -v | 设置详细模式等级 |
| -w | 以HTML表格方式打印结果 |
| -x | 以表格方式输出时,设置表格的属性 |
| -X | 使用指定的代理服务器发送请求 |
| -y | 以表格方式输出时,设置表格属性 |
说明
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.80.128 (be patient).....done
Server Software: Apache //被测试的httpd服务器
Server Hostname: web.zabbix.com //请求的URL主机名
Server Port: 8080 //服务器端口
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Document Path: /index.html //测试的页面文档
Document Length: 208931 bytes //测试的文档大小
Concurrency Level: 10 //并发数
Time taken for tests: 5.213 seconds //所有这些请求被处理完成所花费的总时间 单位秒
Complete requests: 100 //总请求数量,这是我们设置的参数之一
Failed requests: 0 //表示失败的请求数量,这里的失败是指请求在连接服务器、发送数据等环节发生异常,以及无响应后超时的情况
Write errors: 0
Total transferred: 419326 bytes //所有请求的响应数据长度总和。包括每个HTTP响应数据的头信息和正文数据的长度
HTML transferred: 417862 bytes //所有请求的响应数据中正文数据的总和,也就是减去了Total transferred中HTTP响应数据中的头信息的长度
Requests per second: 0.38 [#/sec] (mean) //吞吐率,计算公式:Complete requests/Time taken for tests 总请求数/处理完成这些请求数所花费的时间
Time per request: 5212.847 [ms] (mean) //用户平均请求等待时间,计算公式:Time token for tests/(Complete requests/Concurrency Level)。处理完成所有请求数所花费的时间/(总请求数/并发用户数)
Time per request: 2606.423 [ms] (mean, across all concurrent requests) //服务器平均请求等待时间,计算公式:Time taken for tests/Complete requests,正好是吞吐率的倒数。也可以这么统计:Time per request/Concurrency Level
Transfer rate: 78.56 [Kbytes/sec] received //表示这些请求在单位时间内从服务器获取的数据长度,计算公式:Total trnasferred/ Time taken for tests,这个统计很好的说明服务器的处理能力达到极限时,其出口宽带的需求量。
Connection Times (ms)
min mean[+/-sd] median max
Connect: 983 1124 199.8 1265 1265
Processing: 2354 2460 149.3 2565 2565
Waiting: 534 572 53.7 610 610
Total: 3337 3584 349.1 3831 3831
Percentage of the requests served within a certain time (ms)
50% 3831
66% 3831
75% 3831
80% 3831
90% 3831
95% 3831
98% 3831
99% 3831
100% 3831 (longest request)
百度为例
ab -n 100 -c 10 url=http://www.baidu.com/s
Server Software: BWS/1.1 服务器软件和版本
Server Hostname: 请求的地址/域名
Server Port: 80 端口
Document Path: /s 请求的路径
Document Length: 112435 bytes 页面数据/返回的数据量
Concurrency Level: 10 并发数
Time taken for tests: 4.764 seconds 共使用了多少时间
Complete requests: 100 请求数
Failed requests: 99 失败请求 百度为什么失败这么多,应该是百度做了防范
(Connect: 0, Receive: 0, Length: 99, Exceptions: 0)
Total transferred: 11342771 bytes 总共传输字节数,包含http的头信息等
HTML transferred: 11247622 bytes html字节数,实际的页面传递字节数
Requests per second: 20.99 [#/sec] (mean) 每秒多少请求,这个是非常重要的参数数值,服务器的吞吐量
Time per request: 476.427 [ms] (mean) 用户平均请求等待时间
Time per request: 47.643 [ms] (mean, across all concurrent requests) 服务器平均处理时间,也就是服务器吞吐量的倒数
Transfer rate: 2325.00 [Kbytes/sec] received 每秒获取的数据长度
Connection Times (ms)
min mean[+/-sd] median max
Connect: 22 41 12.4 39 82 连接的最小时间,平均值,中值,最大值
Processing: 113 386 211.1 330 1246 处理时间
Waiting: 25 80 43.9 73 266 等待时间
Total: 152 427 210.1 373 1283 合计时间
Percentage of the requests served within a certain time (ms)
50% 373 50%的请求在373ms内返回
66% 400 60%的请求在400ms内返回
75% 426
80% 465
90% 761
95% 930
98% 1192
99% 1283
100% 1283 (longest request)

nmon工具
一、环境:
1、操作系统:CentOS 6.5
2、nmon软件包:nmon16d_x86.tar.gz
二、下载nmon工具:
下载地址:
http://nmon.sourceforge.net/pmwiki.php?n=Site.Download
根据对应的系统版本下载,这里下载“nmon16d_x86.tar.gz”。
三、安装nmon:
1、上传工具到系统的/tmp目录下:
2、解压nmon16d_x86.tar.gz:
tar -zxvf nmon16d_x86.tar.gz
解压后找到相应的版本,例如我在用的linux版本是32位的CentOS 6.5,则是nmon_x86_centos6
3、赋予可执行权限:
chmod +x nmon_x86_centos6
4、放到/usr/local/bin/目录下并改名为"nmon":
cp nmon_x86_centos6 /usr/local/bin/nmon
5、使用alias命令对执行nmon的命令进行取别名,方便以后使用
alias nmo='sh /usr/local/bin/nmon'
6、运行查看结果:
nmon
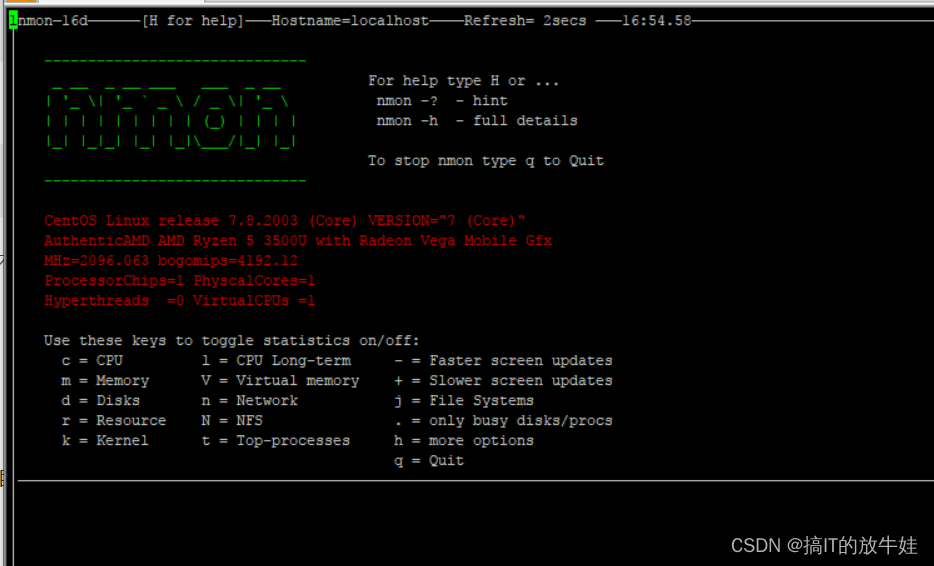
输入c 则展示cpu信息

注意:如果使用xshell可能会出现乱码,不过不影响使用,一般很少进去查看实时指标
四、 生成nmon报告:
nmon -s10 -c60 -f # 直接在执行该命令的当前目录生成文件
nmon -s10 -c60 -f -m /nmon_logs/
参数解释:
-s10 每 10 秒采集一次数据。
-c60 采集 60 次,即为采集十分钟的数据。
-f 生成的数据文件名中包含文件创建的时间。
-m 生成的数据文件的存放目录。
这样就会生成一个 nmon 文件,并每十秒更新一次,直到十分钟后。
生成的文件名如: host_210519_0601.nmon,“host”是这台主机的主机名。
五、转化成报表:
打开nmon analyser 软件:
点击“Analyze nmon data”按钮,选中nmon文件,进行转换:

生成文件的部分内容:
备注:在生成的文件中MEM表里面使用如下公式计算出每行的内存使用率并进行取平均:
(Memtotal - Memfree - cached - buffers)/Memtotal * 100即( =(B2-F2-K2-N2)/B2*100)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)