
k8s(17)之亲和性调度
k8s之亲和性调度一般情况下我们部署的 Pod 是通过集群的自动调度策略来选择节点的,默认情况下调度器考虑的是资源足够,并且负载尽量平均,但是有的时候我们需要能够更加细粒度的去控制 Pod 的调度,比如我们内部的一些服务 gitlab 之类的也是跑在Kubernetes集群上的,我们就不希望对外的一些服务和内部的服务跑在同一个节点上了,担心内部服务对外部的服务产生影响;但是有的时候我们的服务之间交
k8s之亲和性调度
一般情况下我们部署的 Pod 是通过集群的自动调度策略来选择节点的,默认情况下调度器考虑的是资源足够,并且负载尽量平均,但是有的时候我们需要能够更加细粒度的去控制 Pod 的调度,比如我们内部的一些服务 gitlab 之类的也是跑在Kubernetes集群上的,我们就不希望对外的一些服务和内部的服务跑在同一个节点上了,担心内部服务对外部的服务产生影响;但是有的时候我们的服务之间交流比较频繁,又希望能够将这两个服务的 Pod 调度到同一个的节点上。这就需要用到 Kubernetes 里面的一个概念:亲和性和反亲和性。
默认情况下创建Pod是根据Kubernetes scheduler的默认调度规则来进行调度,但有些时候,有些应用有一些特殊的需求。比如指定部署到对应的节点,多个Pod之间需要部署在不同的一个节点,需要互斥、Pod和Pod间互相交流比较频繁需要跑在一个节点,这里就需要用到Kubernetes里面的一个概念: 亲和性和反亲和性
亲和性分为节点亲和性nodeAffinity和Pod 亲和性podAffinity

在介绍亲和性之前,这里先介绍一下常用的调度方式: NodeSelector
在Kubernetes中label是一个非常重要的概念,用户可以通过label来管理集群中的资源,比如常见的service就是通过label去匹配Pod资源,而Pod的调度也可以根据节点的label继续调度
这里先查看一下默认的node节点labels
[root@k8s-01 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-01 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-01,kubernetes.io/os=linux
k8s-02 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-02,kubernetes.io/os=linux
k8s-03 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-03,kubernetes.io/os=linux
k8s-04 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-04,kubernetes.io/os=linux
我们还可以手动添加node节点的标签
因为我之前并没有在标签上区分master和node,这里我使用标签来区分一下
[root@k8s-01 ~]# kubectl label nodes k8s-01 host=master-01
node/k8s-01 labeled
[root@k8s-01 ~]# kubectl label nodes k8s-02 host=master-02
node/k8s-02 labeled
[root@k8s-01 ~]# kubectl label nodes k8s-03 host=master-03
node/k8s-03 labeled
#这里为了演示设置了3组不同的标签
接下来可以查看一下,下面就可以看到在标签中添加了一个名称为host=master的标签,每个节点的标签名称不同(当然也可以设置相同,都设置为host=master也可以)
[root@k8s-01 ~]# kubectl get nodes --show-labels |grep master
k8s-01 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,host=master-01,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-01,kubernetes.io/os=linux
k8s-02 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,host=master-02,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-02,kubernetes.io/os=linux
k8s-03 Ready 23d v1.14.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,host=master-03,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-03,kubernetes.io/os=linux
这里使用一个busybox镜像,将pod绑定到k8s-01节点上
apiVersion: v1
kind: Pod
metadata:
labels:
app: web
name: test
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
name: busybox
nodeSelector: #添加nodeselector,让Pod只匹配的node节点
host: master-01 #匹配node label标签为host=master-01的节点
这里我们就可以看到一个名称为test的pod调度到k8s-01节点,因为我k8s-01节点设置的就是master-01的名称
[root@k8s-01 test]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 35s 172.30.40.3 k8s-01
如果我们在设置的nodeSelector中写错了node节点的标签名,那么pod会一直处于pending状态,因为没有合适的node节点,所以会一直处于等待状态
亲和性和反亲和性调度
亲和性调度可以分为软策略和硬策略两种方式
- 软策略 如果当前node节点中没有满足要求的节点,Pod就会忽略,继续完成调度
- 硬策略 如果当前node节点中没有满足条件的节点,就不断重试,直到满足条件位置
同时亲和性又分为nodeAffinity和podAffinity 节点亲和性和Pod亲和性
nodeAffinity
Node affinity 是 Kubernetes 1.2版本后引入的新特性,类似于nodeSelector,允许我们指定一些Pod在Node间调度的约束。支持两种形式:requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution,可以认为前一种是必须满足,如果不满足则不进行调度,后一种是倾向满足,不满足的情况下会调度的不符合条件的Node上
这里使用Nginx Deployment来进行调度管理
硬策略
简单的介绍一下就是不在标签hostname=k8s-04这台节点创建pod
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: affinity
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
affinity: #亲和性的调度设置
nodeAffinity: #策略为节点亲和性
requiredDuringSchedulingIgnoredDuringExecution: #亲和性的硬策略
nodeSelectorTerms: #这里不再使用nodeselector,使用这个参数可以进行相对简单的逻辑运算
- matchExpressions: #匹配表达式
- key: kubernetes.io/hostname #具体匹配规则(可以通过kubectl get node --show-labels找到相应规则)
operator: NotIn #不在,简单的来说就是不在k8s-04节点
values:
- k8s-04
构建完可以查看到,没有在k8s-04节点进行运行
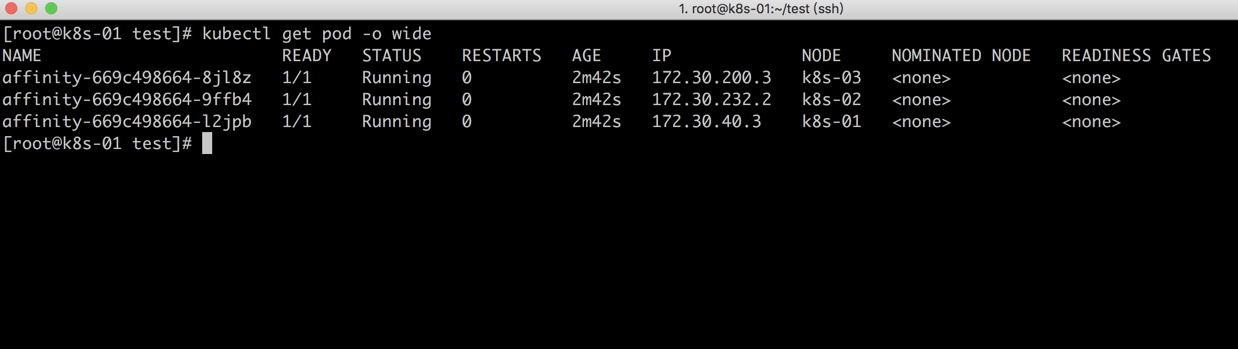
相关参数解释
- 同时指定nodeSelector and nodeAffinity,pod必须都满足
- nodeAffinity有多个nodeSelectorTerms ,pod只需满足一个
- nodeSelectorTerms多个matchExpressions ,pod必须都满足
标签判断的操作符除了使用In之外,还可以使用NotIn、Exists、DoesNotExist、Gt、Lt。如果指定多个nodeSelectorTerms,则只要满足其中一个条件,就会被调度到相应的节点上。如果指定多个matchExpressions,则所有的条件都必须满足才会调度到对应的节点。
软策略
目前我们有4个节点{1-4},但是我们希望pod不调度在k8s-01和k8s-02节点
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: affinity-preferred
labels:
app: affinity-preferred
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: affinity-preferred
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
affinity: #亲和性的调度设置
nodeAffinity: #策略为节点亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-01
- k8s-02
preferredDuringSchedulingIgnoredDuringExecution: #亲和性软策略
- weight: 10 #权重, weight范围1-100。这个涉及调度器的优选打分过程
preference: #调度策略,而不是硬性的要求 (属于软策略的参数)
matchExpressions: #匹配表达式
- key: kubernetes.io/hostname
operator: In
values:
- k8s-04
因为加了软策略,所以并不是强制调度在K8s-04节点上,所以在03节点上也有。

nodeAffinity使用场景:
- 将S1服务的所有Pod部署到指定的符合标签规则的主机上。
- 将S1服务的所有Pod部署到除部分主机外的其他主机上。
总的来说,node亲和性与nodeSelector类似,是它的扩展。当然软硬策略也可以分开写
podAffinity
podAffinity特性是Kubernetes 1.4后增加的,允许用户通过已经运行的Pod上的标签来决定调度策略,用文字描述就是“如果Node X上运行了一个或多个满足Y条件的Pod,那么这个Pod在Node应该运行在Pod X”,因为Node没有命名空间,Pod有命名空间,这样就允许管理员在配置的时候指定这个亲和性策略适用于哪个命名空间,可以通过topologyKey来指定。topology是一个范围的概念,可以是一个Node、一个机柜、一个机房或者是一个区域(如北美、亚洲)等,实际上对应的还是Node上的标签。
首先为了方便演示,我这里创建一个标签为app=web01的Deployment,将我们新建的Pod绑定到app=web01的节点上去
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: tomcat-test
labels:
app: web01
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: web01
spec:
containers:
- name: tomcat
image: tomcat
ports:
- name: http
containerPort: 8080
创建完成后,我们可以先查看一下新建的pod位于的节点和标签
已经看到有3个标签为app=web01的Pod分别运行在k8s0{1-3}的节点中,那么我们下面创建的Pod亲和力也应该分别处于和三个节点中

apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-test
labels:
app: nginx
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 8080
affinity:
podAffinity: #pod亲和力参数
requiredDuringSchedulingIgnoredDuringExecution: #硬策略 (在podAffinity中也可以添加软策略和硬策略)
- labelSelector: #匹配label标签 (Pod具有的label标签,而不是Node的标签)
matchExpressions: #匹配规则
- key: app #对应的标签
operator: In
values:
- web01 #对应的标签
topologyKey: kubernetes.io/hostname
接下来我们可以查看一下
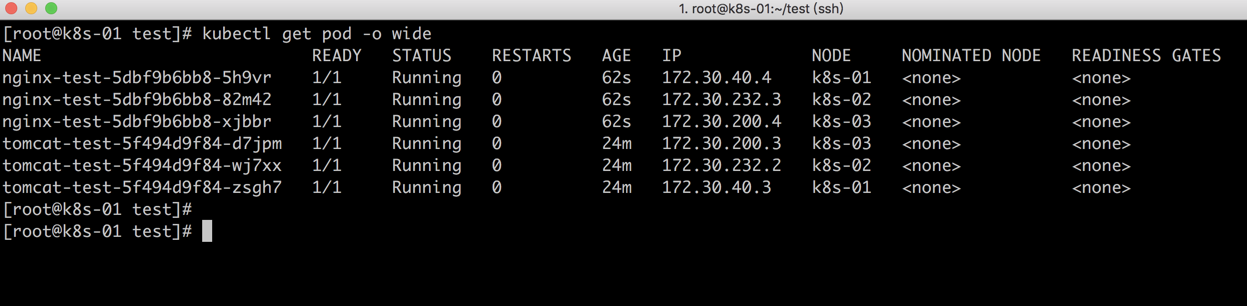
现在我们将Pod调度在app=web01所在的节点上,因为我们加了top域kubernetes.io/hostname,也就是当我们app=web01在哪个节点上,我们创建的pod就会追随到那个节点上。但是如果我们将topologyKey修改为kubernetes.io/os那么,所有的Pod都会在所有的节点上运行. 因为kubernetes.io/os是在所有节点都有的一个策略。

“如果Node X上运行了一个或多个满足Y条件的Pod,那么这个Pod在Node应该运行在Pod X”,因为Node没有命名空间,Pod有命名空间,这样就允许管理员在配置的时候指定这个亲和性策略适用于哪个命名空间,可以通过**topologyKey**来指定。topology是一个范围的概念,可以是一个Node、一个机柜、一个机房或者是一个区域(如北美、亚洲)等,实际上对应的还是Node上的标签。
podAffinity使用场景:
- 将某一特定服务的pod部署在同一拓扑域中,不用指定具体的拓扑域。
- 如果S1服务使用S2服务,为了减少它们之间的网络延迟(或其它原因),把S1服务的POD和S2服务的pod部署在同一拓扑域中。
这样就可以更好的解一下topologyKey参数
podAntiAffinity
Pod反亲和性大致意思是比如一个节点运行了某个Pod,那么我们希望我们的Pod调度到其他节点上去,保证不会有相同业务的Pod来分享节点资源
podAntiAffinity使用场景:
- 将一个服务的POD分散在不同的主机或者拓扑域中,提高服务本身的稳定性。
- 给POD对于一个节点的独占访问权限来保证资源隔离,保证不会有其它pod来分享节点资源。
- 把可能会相互影响的服务的POD分散在不同的主机上。
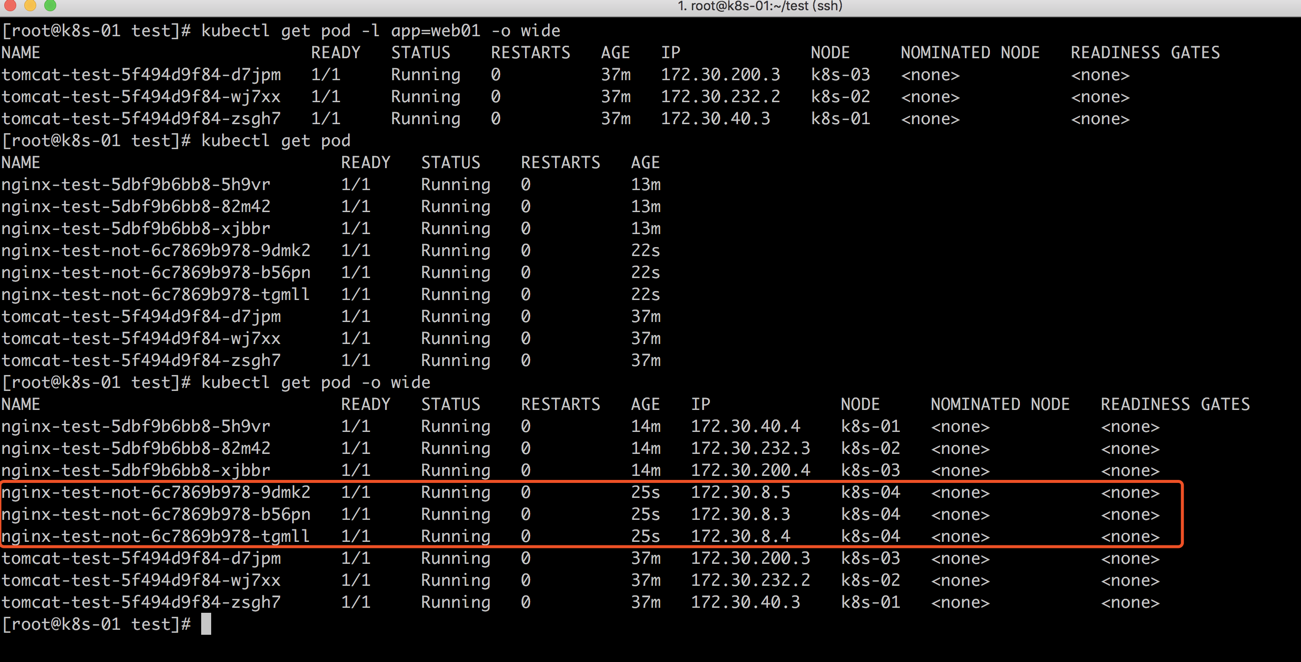
pod反亲和性实际上只需要上pod亲和性中的podAffinity修改为podAntiAffinity就可以。还是以上面nginx举例,上面的nginx 3个pod节点已经运行在k8s-0{1-3}中,那么我们创建的反亲和性应该就让让它运行在k8s-04节点 (因为添加了硬策略,所以它没有选择其他节点的权利)
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-test-not
labels:
app: nginx
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 8080
affinity:
podAntiAffinity: #修改为反亲和力,其他参数不变 (当然Deployment名称肯定需要修改)
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web01
topologyKey: kubernetes.io/hostname
创建后,因为标签为app=web01的节点上已经有k8s-01…k8s-03占用,只有k8s-04没有。所以这里会强制在k8s-04节点创建Pod
关于调度器如果不懂可以查看一下我之前写的文章 Kubernetes scheduler调度器介绍

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)