
Torch模型迁移到Pytorch
最近要做一份工作需要复现一篇论文的结果,但是论文的source code是lua语言,torch7框架的,所以自己在学习语言和搭建环境上花费了比较多的时间,最后网路也没调通,身边也没找到有接触过lua+torch使用的人,因此咨询了大神,可以将torch的模型迁移到pytorch上。因此打算将这一段时间的工作写在博客上记录起来,方便自己后面查阅。lua+torch安装lua和torch的安...
最近要做一份工作需要复现一篇论文的结果,但是论文的source code是lua语言,torch7框架的,所以自己在学习语言和搭建环境上花费了比较多的时间,最后网路也没调通,身边也没找到有接触过lua+torch使用的人,因此咨询了大神,可以将torch的模型迁移到pytorch上。
因此打算将这一段时间的工作写在博客上记录起来,方便自己后面查阅。
- lua+torch安装
lua和torch的安装方法,网上有很多,就不赘述了,都是相同的内容。
这里需要注意的是,因为版本的问题,我所用的服务器的cuda版本是10.0,这样使用官方给的安装教程安装失败了,通过在网上查找各大神的安装经验,找到了一条非常有帮助的:
cuda10以上版本,需要将cmake版本提升到3.13以上(这里我将cmake提升到了3.14.3)。
然后用
https://github.com/nagadomi/distro
这个替代官方代码,其余编译和安装依赖包等都是相同的。
- 安装loadcaffe模块
sudo luarocks --from=https://raw.githubusercontent.com/torch/rocks/master/ install loadcaffe - 安装hdf5
sudo ~/torch_new/install/bin/luarocks install hdf5
但是在执行这个之前,要安装一些依赖,记录找不到了,可以直接搜索这个。
这个路径是我自己安装的路径,可以根据自己的安装位置改写,至于为什么不直接用luarocks指令,我也不清楚,因为我直接用会报错,什么包都没搜索到。 - cudnn安装
我才发现我现在用的服务器没有安装cudnn,又忙着装了一下cudnn7.6.0。
————————————————————————————————————
开始正经工作了。
- torch模型参数的保存
因为论文的作者提供了pretrain的model。因此打算直接将原model每一层的weight和bias读取出来,保存起来,然后在pytorch中搭建相同的模型,将参数读进去,完成迁移。
torch中有一个指令可以直接获取model中所有有参数的层的weight和bias,还有梯度。
parameters, gradParameters = net:getParameters()
parameter是所有层的参数的堆叠,都放在这里面了。
我是将这个参数保存在txt里了:
local pm = io.open("parameters.txt","w")
pm:write(tostring(parameters))
io.close(pm)
还可以逐层保存。
有参数的层有三类,conv层,bn层,和linear层。都是weight+bias。
可以参照
https://blog.csdn.net/baidu_33693914/article/details/80259961
来保存每一层的参数:
net = nn.Sequential()
net:add(nn.SpatialConvolution(1, 6, 5, 5)) -- 1 input image channel, 6 output channels, 5x5 convolution kernel
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max.
net:add(nn.SpatialConvolution(6, 16, 5, 5))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2))
net:add(nn.View(16*5*5)) -- reshapes from a 3D tensor of 16x5x5 into 1D tensor of 16*5*5
net:add(nn.Linear(16*5*5, 120)) -- fully connected layer (matrix multiplication between input and weights)
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(120, 84))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(84, 10)) -- 10 is the number of outputs of the network (in this case, 10 digits)
net:add(nn.LogSoftMax())
--查看参数两种方式
net.modules[1]==net:get(1) --true --nn.SpatialConvolution(1 -> 6, 5x5)
net:get(1).bias --[0.0183,0.1677,0.0273,-0.0872,-0.1100,-0.0090] torch.DoubleTensor of size 6
我所使用的网络中还使用了别的模块,例如:
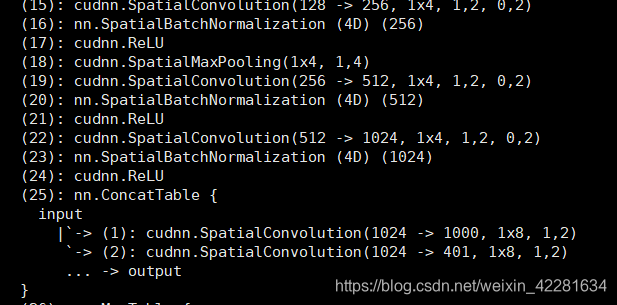
这里提一下table中的层怎么保存参数:
weight_level = net:get(25):get(1).weight
bias_level = net:get(25):get(1).weight
也就是用两个get()来索引。
---------------------------------更新2.7---------------------------------------
按照上面的过程,将所有的参数都单独保存成为一个文件(我保存的是txt)。
然后将文件中的内容读出来,保存到numpy数组中。
这里需要注意的是numpy数组的shape要和model中每一层的weight或者bias的shape要相同!
如:
self.conv1 = nn.Conv1d(1, 16, 64, 2, 32)
print(self.conv1.weight.shape, self.conv1.bias.shape)
得到的是:
torch.Size([16, 1, 64]) torch.Size([16])
因此numpy数组就需要reshape成对应的shape,这个还是挺方便的,在torch中保存参数时,每一个文件的最后都会附上对应的shape。
这里假设我得到的结果,处理好的numpy数组是c1_weight, c1_bias,则按下面的指令将数据读取进来:
self.conv1 = nn.Conv1d(1, 16, 64, 2, 32)
self.conv1.weight.data = torch.FloatTensor(c1_weight).cuda()
self.conv1.bias.data = torch.FloatTensor(c1_bias).cuda()
这两行我是写在初始化里面的,我是将所有的都写好,然后将模型保存下来,后面直接读取模型就可以了,就不用每次定义模型时都加载一次参数了。
这是卷积层,bn层和linear都是一样的,保证shape一致就可以了。
另外:torch7中可以通过
parameters, gradParameters = net:getParameters()
来获取所有的有参数层的参数,但是这个和我们逐层提取的参数是由排列上的区别的(只是层内的数据),因此建议谨慎使用这个整体读取出来的数据(虽然可以直接根据网络计算出哪一些行是对应哪一层的参数,但是排列上有一点区别,我个人没有尝试这种方法,并不知道能够对齐)。
谢谢。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)