
论文笔记(Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding)
论文笔记(Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding)论文地址和代码可自行GithubBERT是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们实际要处理的下游NLP任务(如分类、阅读理解、情感识别等)。BERT
论文笔记(Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding)
论文地址和代码可自行Github
BERT是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们实际要处理的下游NLP任务(如分类、阅读理解、情感识别等)。BERT优于以前的方法,因为它是用于预训练NLP的第一个无监督地、双向的、深度的系统。
BERT的模型架构是一个多层双向Transformer编码器。Bert本身不是一个新的模型,而是基于Transformer,通过大量的数据,在transformer的基础上,对其encoder进行mask操作训练而得的。Bert是预训练好的NLP模型,我们处理特定问题时,只需要把bert模型下载下来,在最后设计一层额外的输出层(根据我们自己的实际任务而定),并加载对应的预训练完成的模型参数,在此基础上用自己的数据集进行fine-tuning就可以达到较好的效果。
Google给出了两种大小的bert模型(根据任务需求使用):
BERT-BASE: L=12, H=768, A=12, Total Parameters=110M
BERT-LARGE: L=24, H=1024, A=16, Total Parameters=340M
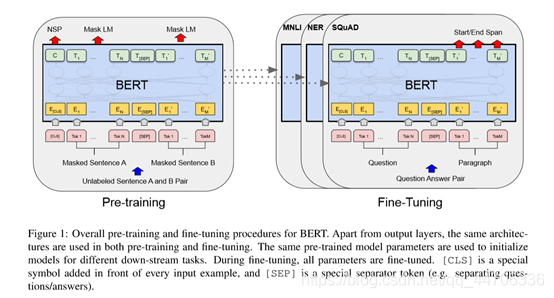
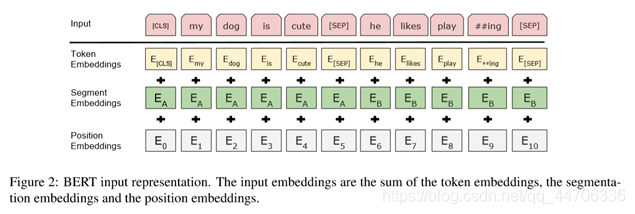
Bert在预训练时的两个任务:
-
Masked LM(language model):对transformer的encoder,input句子中的词。有15%的被随机mask掉,在输出通过端预测被mask掉的词,使用交叉熵损失函数。其中的80%被[MASK]标记替代,10%保持原样不变,10%用一个随机的词进行替代。这样,既完成了无监督的训练,又提高了鲁棒性。
-
Next Sentence Prediction (NSP):用于学习两个句子之间的关系,这种关系并不能够通过语言模型(ML)学到。【常用于如QA、NLI(natural language inference)等任务】为了使训练的模型可以学到两个句子之间的关系,文章选取句子A和句子B拼凑起来作为每一个输入样本,并在添加[CLS]、[ESP]标记。(如,A= I am xxx, B=let’s go shopping,则input=[CLS]I am xxx [ESP] let’s go shopping[ESP])其中,50%的句子B是句子A的下一句(其label为“IsNext“),50%的句子B是从语料库中随机选取的(其label为“NotNext“)。模型通过判断其输出结果是否正确来学习权重参数。
通过这两个训练策略,就可使得训练出的模型不仅学到词在句子中的关系,而且还学到了句子与句子之间的关系。Bert使用GLUE(General Language Understanding Evaluation)数据集作为benchmark进行模型预训练。训练时,其Batch size设为32,fine-tune的epoch为3。并通过实验选取了最高得分的学习率。
Ablation Studies(消融实验):例如,我们想知道使用self-attention机制、Mask机制等对结果的影响,就把这些机制、变量、layers等从模型中删除,然后再做对比试验,观察其对结果的影响程度。
(初识机器学习,学识短浅,如有不妥,欢迎批评指正)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)