
Python爬取豆瓣Top250的电影
流程图如下:爬取网页-解析网页-存储数据到Excel和数据库中源代码如下:如果被豆瓣封Ip(一般被封第二天就解封了),可以自己设置代理Ip,或者自己登录账号后将Cookie放到header中。# -*- codeing = utf-8 -*-# @Time :2021/3/24 9:01# @Author:KaiKai-G# @File : __init__.py.py# @Software: P
·
流程图如下:
爬取网页-解析网页-存储数据到Excel和数据库中
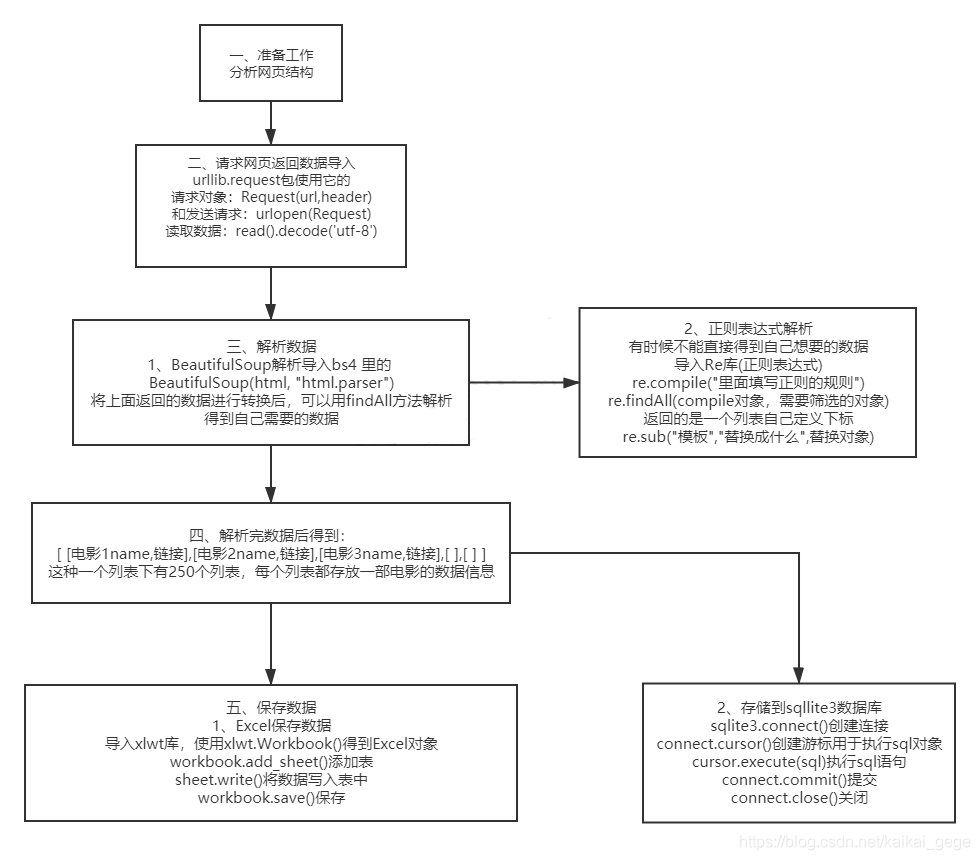
源代码如下:
如果被豆瓣封Ip(一般被封第二天就解封了),可以自己设置代理Ip,或者自己登录账号后将Cookie放到header中。
# -*- codeing = utf-8 -*-
# @Time :2021/3/24 9:01
# @Author:KaiKai-G
# @File : __init__.py.py
# @Software: PyCharm
from bs4 import BeautifulSoup #解析网页
import re #使用正则得出想要的
import urllib.error #url报错
from urllib.request import Request,urlopen #访问网页爬取数据
import xlwt #进行excel 操作的
import sqlite3 #进行数据库操作的
import time #设置一下阻塞时间
#访问网址爬取源码
def P_url(url):
#用户代理模拟浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"}
html = ""
try:
response = urlopen(Request(url=url, headers=headers)) #访问
html = response.read().decode('utf-8') #读取
#print(html)
except Exception as result:
print(result)
return html
#加上r为了防止转义字符错误,
compile_name = re.compile(r'<span class="title">(.*?)</span>') #电影名的正则规则,表示匹配多个字符
compile_href = re.compile(r'<a href="(.*?)">') #电影链接
compile_pic = re.compile(r'<img alt=".*" class="" src="(.*?)" width="100"/>') #电影图片链接
compile_assess = re.compile(r'<span>(\d+)人评价</span>') #评价人数
compile_person = re.compile(r'<p class="">(.*?)</p>',re.S) #导演、演员概述(re.S,针对被使用对象让.能匹配换行符)
compile_score = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') #评分
compile_inq = re.compile(r'<span class="inq">(.*?)</span>') #电影简述
#正则表达式的使用解析bs4的数据
def compile_Self(item):
data = [] #存储每一部电影的情况
# 根据正则的规则从item中找出电影名字(findall返回的是一个元组,需要从中取第一个元素即可)
movieName = re.findall(compile_name, item)[0] # findall返回的是元组,符合正则规格的有两个,第一个是中文,第二个英文
movieHref = re.findall(compile_href, item)[0]
moviePic = re.findall(compile_pic, item)[0]
movieAssess = re.findall(compile_assess, item)[0]
movie_Person = re.findall(compile_person, item)[0]
movieScore = re.findall(compile_score,item)[0]
movieinq = re.findall(compile_inq, item) #因为有电影存在空,防止列表越界,不直接获取
# \s:空格、换行符、制表符等等 ...<br/>:内容
moviePerson2 = re.sub(r'[\s...<br/>]*', '', movie_Person) #替换多个字符
moviePerson = moviePerson2.replace("'", "‘") #有的人名存在单引号,会对以后的sql语句有影响
#将每个数据传输到data中
data.append(movieName)
data.append(movieHref)
data.append(moviePic)
data.append(movieAssess)
data.append(moviePerson)
data.append(movieScore)
if len(movieinq) == 0: #根据报错分析出有的电影没有概述
data.append(" ") # 如果不存在就留一个空
else:
movie_inq = movieinq[0]
movieinq = re.sub(r"'", "‘", movie_inq) #有的人名存在单引号,会对以后的sql语句有影响
data.append(movieinq)
return data
#根据爬取的源码分析得到有用数据
def getData(baseurl):
listData = []
y = 0
for i in range(0,10,1): #访问十次页面
# 根据豆瓣250条数据,每页25条数据,依次递增即可全部访问到
url = baseurl + str(i*25)
html = P_url(url)
bs = BeautifulSoup(html, "html.parser") #解析html格式得到bs对象
# 根据网页分析每一个电影的内容都放在<div class="item">下面
for i in bs.find_all("div", class_="item"): #这里要遍历输出(不然都在同一行输出了)
item = str(i) #i是字节,要转化为str才能用正则
#接受每一部电影的列表
self = compile_Self(item)
# 将每一部列表都拼接到list中
listData.append(self)
print(listData)
return listData
#存储数据到Excle
def saveData_Excel(dataList):
workbook = xlwt.Workbook(encoding="utf-8")
sheet = workbook.add_sheet("豆瓣电影Top250",cell_overwrite_ok=True)
#首先放进去一列
cul = ("电影名","电影链接","电影图片链接","评价人数","导演、演员概述","评分","电影简述")
for i in range(0,7):
sheet.write(0,i,cul[i])
#读取250条列表数据
for i in range(0,250):
data = dataList[i] #读取每一个电影列表
print(i+1,data)
for j in range(0,7): #从每一个电影列表中取出数据
sheet.write(i+1,j,data[j])
workbook.save("豆瓣250Top电影.xls")
print()
#初始化数据库,建表
def init_data(self):
#创建连接
connect = sqlite3.connect(self)
#获取游标(用于执行sql语句)
cursor = connect.cursor()
#这里注意要设置自增长,必须用integer primary key autoincrement
sql = '''
create table movie250(
id integer primary key autoincrement not null,
name varchar,
href text,
pic text,
assess numeric,
person varchar,
score numeric,
inq varchar)
'''
#执行语句
cursor.execute(sql)
#提交
connect.commit()
#关闭
connect.close()
#保存到数据库
def saveDatabase(dataList,databasePath):
#初始化数据库(建表)
init_data(databasePath)
connect = sqlite3.connect(databasePath) #创建连接
cursor = connect.cursor() # 获取游标(用于执行sql语句)
for data in dataList:
for index in range(0,7): #这里需要遍历加上单引号,用于sql语句中
if index == 3 or index == 5: #assess和socre都是num类型的,不能加单引号
continue
else:
data[index] = "'"+data[index]+"'" #给元素加单引号
#将元组转换为字符串,每个元素用逗号分开
join = ",".join(data)
#将每一条字符串拼接到sql语句中
sql = '''insert into movie250(name,href,pic,assess,person,score,inq)values(%s)'''%join
print(sql)
cursor.execute(sql) #执行
connect.commit() #提交
connect.close()
if __name__ == '__main__':
# #爬取的豆瓣网址
baseUrl = "https://movie.douban.com/top250?start="
#进行爬取并解析得出数据
dataList = getData(baseUrl)
#-----解析数据存储到Excel
# saveData_Excel(dataList)
#-----将数据存储到数据库
dataBase_Path = "movieTest.db"
saveDatabase(dataList,dataBase_Path)
bs4解析网页、正则表达式解析数据、列表(分割、添加、替换、转字符串)等操作比较复杂一些,总而言之,从网页中提取自己需要的数据这一步相对难一些,有许多要注意的点比如:
- 上面电影的名字有中英文两种,需要取其一
- 爬取的简介有的是空,为了在存储时候不出错要判断留空位
- 有的数据还带有换行符,需要单独替换
- sql操作需要手动添加单引号
- 还有本身带单引号的(如:I’am…)会导致insert数据出错
以上这些基本都需要用正则表达式或者列表添加替换一些地方。
注意:BeautifulSoup一般分析静态网页,但是目前很多网站都使用动态页面,动态页面的数据是后显示出来的,右键看源码是不会显示的,只有在网页上检查才能看到具体的代码,所以我们可以用selenium模拟浏览器进行一系列的操作。关于selenium的一些常用操作:点击跳转

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)