
Spark Java版 windows本地开发环境
安装IntelliJ IDEA下载地址:https://www.jetbrains.com/idea/download/#section=windows选择Community版本安装安装好后启动,我这里选择UI主题默认Plugins.安装scala插件.配置hadoop环境变量下载winutils.exehttps://github.com/steveloughran/winutils我这里
·
安装IntelliJ IDEA
下载地址:https://www.jetbrains.com/idea/download/#section=windows
选择Community版本安装
安装好后启动,我这里选择UI主题
默认Plugins.
安装scala插件.
配置hadoop环境变量
下载winutils.exe
我这里面选择hadoop2.7.1版本
在D盘新建文件D:\hadoop-2.7.1\bin\winutils.exe配置windows环境变量
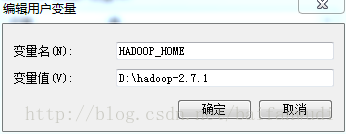
用户变量:
添加HADOOP_HOME=D:\hadoop-2.7.1
系统变量:
Path添加%HADOOP_HOME%\bin
新建maven项目
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.spark</groupId>
<artifactId>sparktest</artifactId>
<version>2.2.0</version>
<packaging>jar</packaging>
<name>sparktest</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.7.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
拷贝
https://github.com/apache/spark/blob/master/examples/src/main/resources/employees.json 文件到项目中
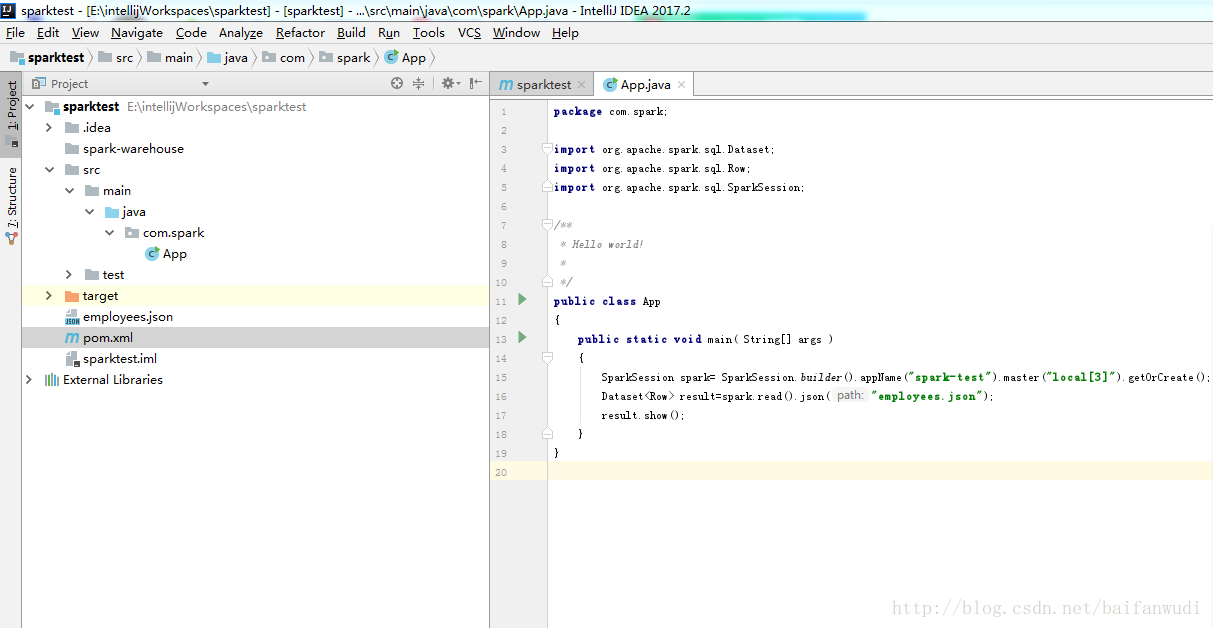
测试代码
package com.spark;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
SparkSession spark= SparkSession.builder().appName("spark-test").master("local[3]").getOrCreate();
Dataset<Row> result=spark.read().json("employees.json");
result.show();
result.printSchema();
spark.stop();
}
}
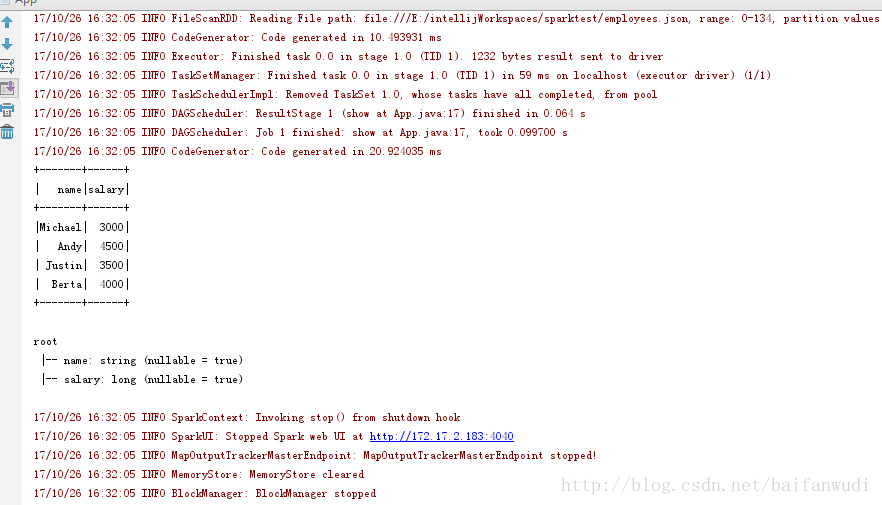
运行结果
完成!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)