
5redis------------redis基础----Redis介绍、 五大数据类型、redis与python-全栈式开发42
分布式爬虫普通爬虫改成分布式爬虫I/O压力:读写操作 读写压力造成性能上的瓶颈一、Redis介绍背景随着互联网+大数据时代的来临,传统的关系型数据库已经不能满足中大型网站日益增长的访问量和数据量。这个时候就需要一种能够快速存取数据的组件来缓解数据库服务I/O的压力,来解决系统性能上的瓶颈。定义Redis是一个高性能的,开源的,C语言开发的,键值对存储数据的nosql数据库。NoSQL:not on
·
Redis引入
一、Redis介绍
背景
- 随着互联网+大数据时代的来临,传统的关系型数据库已经不能满足中大型网站日益增长的访问量和数据量。这个时候就需要一种能够快速存取数据的组件来缓解数据库服务I/O的压力,来解决系统性能上的瓶颈。
- I/O压力:读写操作 读写压力造成性能上的瓶颈
定义
- Redis是一个高性能的,开源的,C语言开发的,键值对存储数据的nosql数据库。
- NoSQL:not only sql,泛指非关系型数据库 Redis/MongoDB/Hbase Hadoop
- 关系型数据库:MySQL、oracle、SqlServer
数据库的发展历史
- 1.在互联网+大数据时代来临之前,企业的一些内部信息管理系统,一个单个数据库实例就能满足系统的需求。
- 单数据库实例
- 2.随着系统访问用户的增多,数据量的增大,单个数据库实例已经满足不了系统的读取需求
- 缓存(memcache)+单数据库实例
- 3.缓存可以缓解系统的读取压力,但是数据量的写入压力持续增大
- 缓存+主从数据库+读写分离
- 4.数据量再次增大,读写分离以后,主数据库的写库压力出现瓶颈
- 缓存+主从数据库集群+读写分离+分库分表
- 5.互联网+大数据时代来临,关系型数据库不能很好的存取一些并发性高,实时性高的,并且数据格式不固定的数据。
- nosql+主从数据库集群+读写分离+分库分表
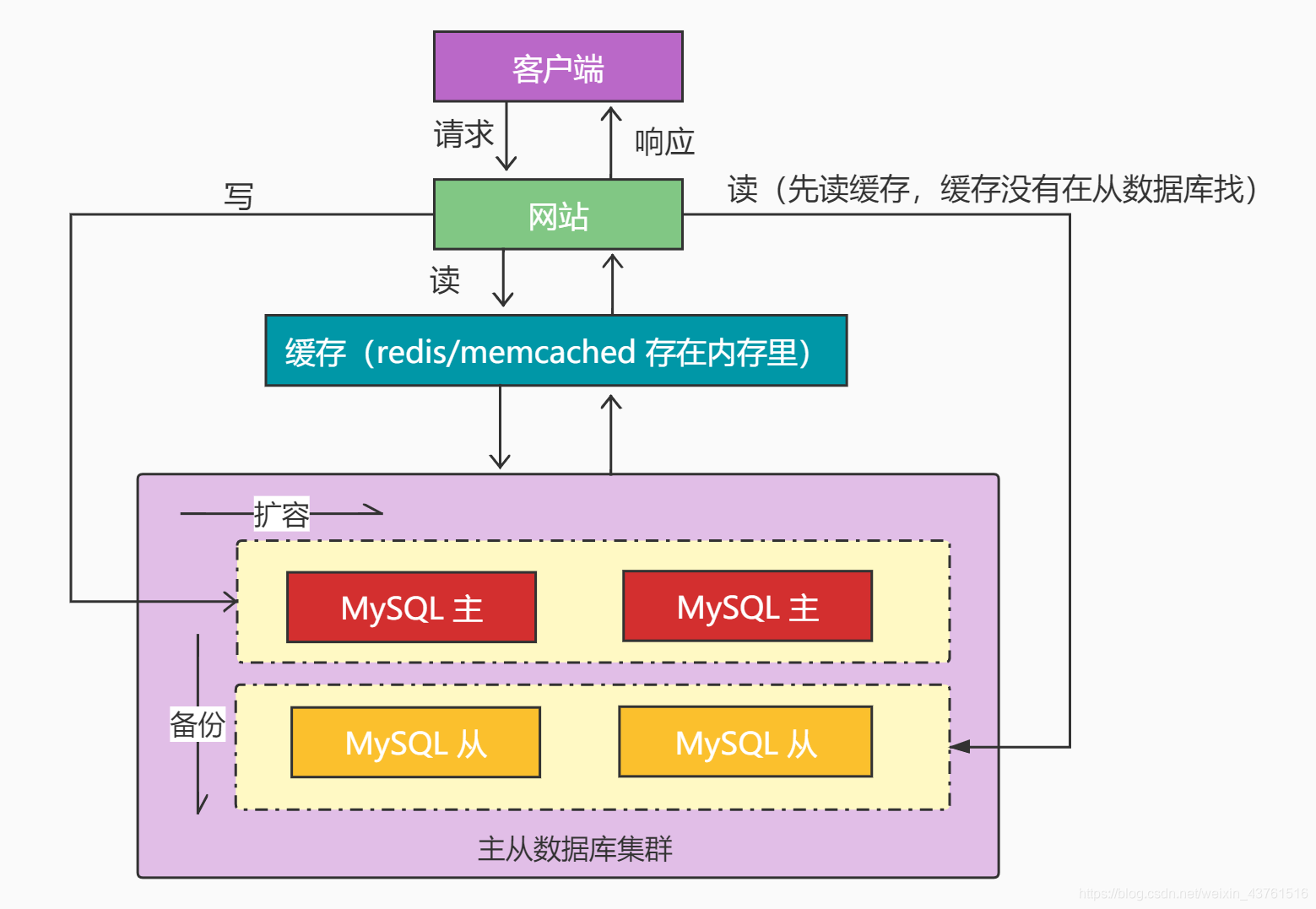
- nosql+主从数据库集群+读写分离+分库分表
NoSQL和SQL数据库的比较
- 适用场景不同:SQL数据库适合用于关系特别复杂的数据查询场景,nosql反之
- 事务:SQL对事务的支持非常完善,而nosql基本不支持事务
- 两者在不断的取长补短
- SQL数据库关系型数据库,存放持久化数据库,每次请求数据库的时候都存在大量的I/O操作,压力会非常大
- NoSQL是非关系型数据库 缓存型
- 数据库,读取速度比较快
Redis特性
- 读写快,快速存取
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
- 支持数据类型比较多(五大数据类型)
- Redis支持数据的备份
Redis应用场景
- 点赞/秒杀/直播平台的在线好友列表/商品排行榜
- 这些数据没必要放到硬盘里,而是放到缓存中
- 数据变化比较快的,不太重要的数据
- 重要的数(银行卡密码、手机号、订单号)
Redis的启动与关闭
```
windows下需要特殊的安装包,因为官方不支持windows
```
-- 开启服务器
redis-server.exe
-- 链接客户端
redis-cli.exe
```
Linux
```
-- 启动服务
redis-server
-- 链接客户端
sudo service redis start
--- 关闭服务
sudo service redis stop
Redis的配置文件
- linux文件存储地方 :/etc/redis/redis.conf
当redis作为守护进程运行的时候,它会写一个 pid 到 /var/run/redis.pid 文件里面。
daemonize no -- 守护进程就是阻塞的方式,改为yes就不堵,服务器后台的方式运行
监听端口号,默认为 6379,如果你设为 0 ,redis 将不在 socket 上监听任何客户端连接。
port 6379
设置数据库的数目。不用改默认16个
databases 16
根据给定的时间间隔和写入次数将数据保存到磁盘
下面的例子的意思是:
900 秒内如果至少有 1 个 key 的值变化,则保存
300 秒内如果至少有 10 个 key 的值变化,则保存
60 秒内如果至少有 10000 个 key 的值变化,则保存
save 900 1
save 300 10
save 60 10000
监听端口号,默认为 6379,如果你设为 0 ,redis 将不在 socket 上监听任何客户端连接。
port 6379
Redis默认只允许本地连接,不允许其他机器连接,改为0.0.0.0就是允许全部都可以连接
bind 127.0.0.1
二、redis语法基础
- 命令参考手册:http://doc.redisfans.com/
- 空是nil
- redis是键值对存储信息的,key一定是字符串类型,key都是唯一的
基础命令
- dbsize 查询当前数据库的key数量
- flushdb 清空当前数据库
- keys * 查看所有key
- select 0 切换数据库,默认编号0-15
- type key 查看键值的数据类型
- redis的索引可以有负数,也是从0开始
三、redis常用五大数据类型
- 这里针对的五大数据类型是指key所对应的value类型,key一直都是字符串
(一)string
- string是redis最基本的类型,一个key对应一个value
- string可以包含任何数据,最大不能超过512M
- 键值是字符串类型

语法
| 基本命令 | 用途 | 用法 |
|---|---|---|
| set | 设置单值 | set key value |
| get | 获取单值 | get key |
| mset | 设置多值 | set key1 value key2 value2 … |
| mget | 获取多值 | get key1 key2 … |
| append | 添加字段在后面拼接 ,返回字符串长度 | append key value |
| del | 删除键值对,返回1表示删除成功 | del key |
| strlen | 返回字符串长度 | strlen key |
- 虽然是键值是字符串类型,但还是可以做加减运算
| 运算命令 | 用途 | 用法 |
|---|---|---|
| incr | 增加1 | incr key |
| decr | 减少1 | decr key |
| incrby | 增加n,n可以为负 | incrby key n |
| decrby | 减少n,n可以为负 | decrby key n |
- redis用到的索引都是包含端点数字的
| 切片命令 | 用途 | 用法 |
|---|---|---|
| getrange | 闭区间取value值 | getrange key start end |
| setrange | 从第几位开始替换value值 | setrange key start value |
| 过时失效 | 用途 | 用法 |
|---|---|---|
| expire | key过时删除,key得存在 | expire key 时间(秒) |
| setrange | key过时删除,key可以不存在 | setex key 时间(秒) |
应用场景
- 验证码、秒杀:字符串的过时失效
- 共享session信息,session就是用户登陆的信息
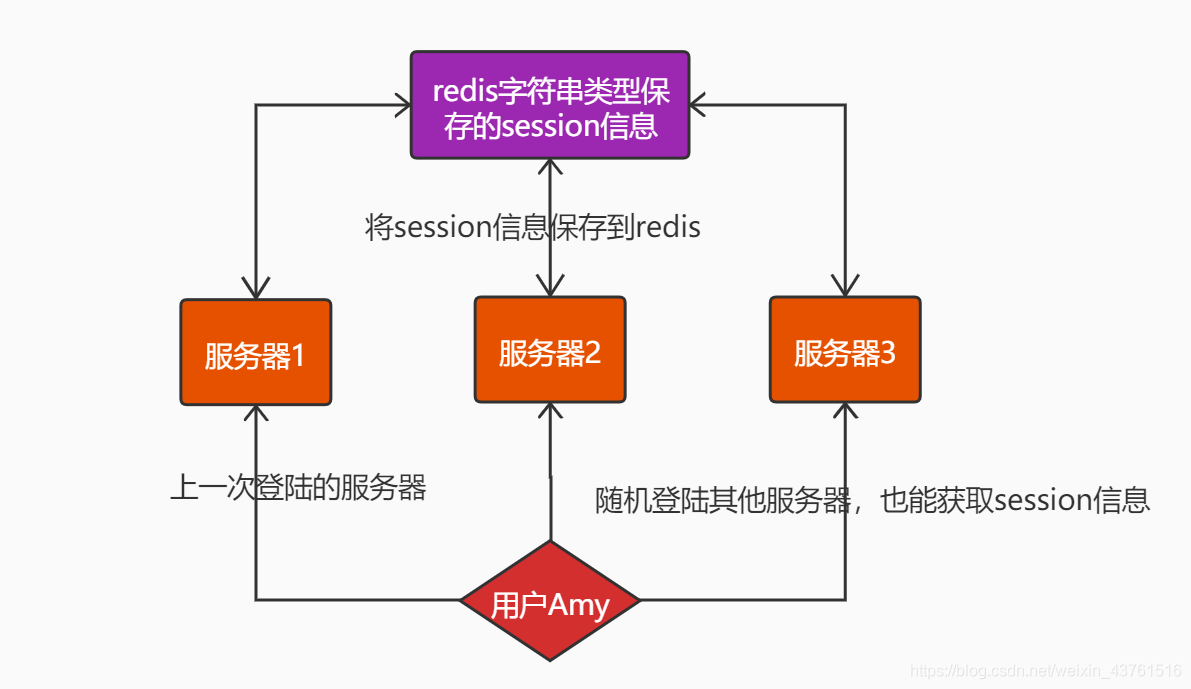
(二)Hash
- hash是一个键值对集合
- hash是一个string类型的field和value的映射表
- hash特别适合存储对象,可以把key想象成类名,value里面保存了各种各样的特征,特征全都是键值对类型的字符串
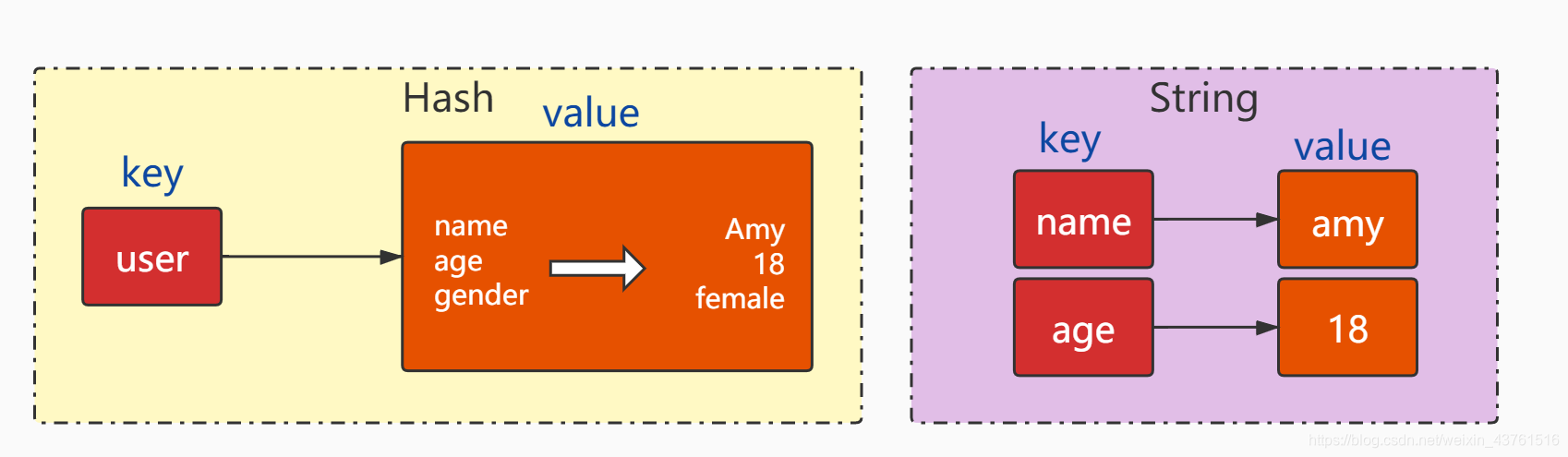
语法
| 基本命令 | 用途 | 用法 |
|---|---|---|
| hset | 设置单key单域 | hset key k v |
| hget | 获取单key单域 | hget key k |
| hmset | 设置单key多域 | hmset key k1 v1 k2 v2 |
| hmget | 获取单key多域 | hmget key k1 k2 |
| hgetall | 获取单key域 | hgetall key |
| hdel | 删除单key多域,返回1表示删除成功 | hdel key k k2… |
| hlen | 获取哈希长度,即有多少个k或域 | hlen key |
| hexists | 查询是否存在某个域k | hexists key k |
| hkeys | 获取key全部域的k | hkeys key |
| hvals | 获取key全部域的v | hvals key |
| 计算 | 用途 | 用法 |
|---|---|---|
| hincrby | 给key的某k值增加n,n可以为负 | hincrby key k n |
应用
- 保存商城购物车数据:多类目的
- 保存用户数据
(三)list
- 单值多value
- 列表是简单的字符串列表,相当于一个空心的竹子,按照插入顺序排序,可以添加一个元素列表的头部(左边)或者尾部(右边)
- 它的底层实际是个链表

语法
- 基本语法
| 基本命令 | 用途 | 用法 |
|---|---|---|
| lpush /rpush | 设置值。入栈,倒序排列 /设置值。堆,正序排列 | lpush/rpush key value1 value2 value3… |
| lpop/rpop | 移除最左/移除最右 | lpop/rpop key |
| lrem | 删N个value,N>0从前面删,N<0从后面删,N=0删全部 | lrem key N |
| llen | 求列表长度 | llen key |
| 切片命令 | 用途 | 用法 |
|---|---|---|
| lrange | 闭区间取value值,查看整个lrange key 0 -1 | lrange key start end |
| ltrim | 闭区间切片,并赋值给value | ltrim key start end |
| lset | 索引替换,只能替换一位 | lset key index value |
| linsert | 在某值之前/之后加值,如果某值不存在,则返回-1,从上到下找,找到第一个就加 | linsert key before/after value value2 |
| lindex | 按照索引下标获得元素,只获取一位 | lindex key index |
应用
- 1.保存用户浏览商品记录
-- 用户浏览记录只保留5条 lrem history_user 0 32 #先判断最新浏览记录是否已经是同一个 lpush history_user 32 # 推值 ltrim history_user 0 4 #截取
(四)set
- set是不重复的、无序集合
- 自动去重
语法
| 基本命令 | 用途 | 用法 |
|---|---|---|
| sadd | 设置值 | sadd key value1 value2 value3… |
| smembers | 查看集合 | smembers key |
| scard | 获取集合里面的元素个数 | scard key |
| sismember | 查看是否存在 | sismember key value |
| srem | 指定删除集合中元素,可多值 | srem key value … |
| smove | 将key1的value 移动到key2里面,如果key1含有value删除并添加给key2 | smove key1 key2 value |
| 随机命令 | 用途 | 用法 |
|---|---|---|
| srandmember | 随机出n个数,默认一个 | srandmember key [n] |
| spop | 随机删几个数,默认一个 | spop key |
| 集合运算命令 | 用途 | 用法 |
|---|---|---|
| sdiff | 差集 | sdiff key1 key2 |
| sinter | 交集 | sinter key1 key2 |
| sunion | 并集 | sunion key1 key2 |
应用
- 随机筛选中奖人,保证已经中奖的人不会重复
- 关注的,不可以重复
(五)Zset(有序集合)
- 有序集合
- 通过手动添加分数给集合排序
- [withscores] 带分数返回 ,是可选选项
- [limit s n]偏移量limit s n,从s开始取n个
| 基本命令 | 用途 | 用法 |
|---|---|---|
| zadd | 设置值 | zadd key num1 value1 num2 value2 … |
| zcard | 获取集合里面的元素个数 | zcard key |
| zrem | 指定删除集合中元素,可多值 | zrem key value… |
| zrank | 返回集合元素的索引值 | zrank key value |
| 切片命令 | 用途 | 用法 |
|---|---|---|
| zrange | 查看集合,根据索引,zrange key 0 -1 看全部 | zrange key start end [withscores] |
| zrangebyscore | 查看集合,根据分数 | zrangebyscore key num1 num2 [withscores] [limit s n] |
| zcount | 返回分数区间总个数 | zcount num1 num2 |
四、redis与python
(一)python链接redis
安装
- pip install redis
连接redis
- r = redis.StrictRedis(host=‘localhost’,port=6379,db=0) #或redis.redis()
- port填的是redis端口号
- db是要链接的数据库编码,默认16个,0-15
##-----------字符串string---------##
import redis
class TestString(object):
def __init__(self):
self.r = redis.StrictRedis(host='192.168.75.130',port=6379)
# 设置值
def test_set(self):
res = self.r.set('user1','juran-1')
print(res)
# 取值
def test_get(self):
res = self.r.get('user1')
print(res)
# 设置多个值
def test_mset(self):
d = {
'user2':'juran-2',
'user3':'juran-3'
}
res = self.r.mset(d)
# 取多个值
def test_mget(self):
l = ['user2','user3']
res = self.r.mget(l)
print(res)
# 删除
def test_del(self):
self.r.delete('user2')
(二)利用redis实现分布式爬虫
- 这部分属于爬虫知识,全栈开发可以不用了解
- 学习链接:https://blog.csdn.net/weixin_43761516/article/details/117373882

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)