

MapReduce英语单词频次统计
或直接将下文的xml的“dependency”中的“version”改为自己的hadoop版本。上传jar文件和input文件夹至liunx的/data/temp。2. 如有/output文件夹,删除。此处以hadoop3.3.4为例。上传input至hdfs。请勿使用idea社区版。
·
MapReduce英语单词频次统计
1.前提准备
1.1 启动hadoop(集群)
- 启动HDFS
start-dfs.sh
- 启动YARN
start-yarn.sh
- 历史服务器
mapred --daemon start historyserver
2.创建Maven工程
2.1 使用idea创建Maven工程
请勿使用idea社区版


2.2 导入Hadoop的maven依赖
自行官网搜索依赖:mvnrepository
或直接将下文的xml的“dependency”中的“version”改为自己的hadoop版本
此处以hadoop3.3.4为例
- 在pom.xml中新增hadoop的依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.4</version>
<scope>test</scope>
</dependency>
</dependencies>
- 加载maven变更,此操作会更新本地maven仓库,需自动下载,稍等片刻

3.MapReduce程序
3.1 此处直接将课堂给的参考链接代码复制
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
//1 get values string
String valueString = value.toString();
//2 split string
String wArr[] = valueString.split(" ");
//3 for iterator
for(int i = 0;i < wArr.length;i++){
//map out key/value
context.write(new Text(wArr[i]), new LongWritable(1));
}
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class MyReduce extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key,Iterable<LongWritable> valueIn,Context context) throws IOException, InterruptedException {
Iterator<LongWritable> it = valueIn.iterator();
long sum = 0;
//iterator count arr
while(it.hasNext()){
sum += it.next().get();
}
context.write(key,new LongWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//1 get a job
Job job = Job.getInstance(conf);
//2 set jar main class
job.setJarByClass(TestJob.class);
//3 set map class and reducer class
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
//4 set map reduce output type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5 set key/value output file format and input/output path
FileInputFormat.setInputPaths(job,new Path("/input/word.txt"));
FileOutputFormat.setOutputPath(job,new Path("/output"));
//6 commit job
job.waitForCompletion(true);
}
}
4.打包
4.1打包为jar包
- 依次点击clean和package
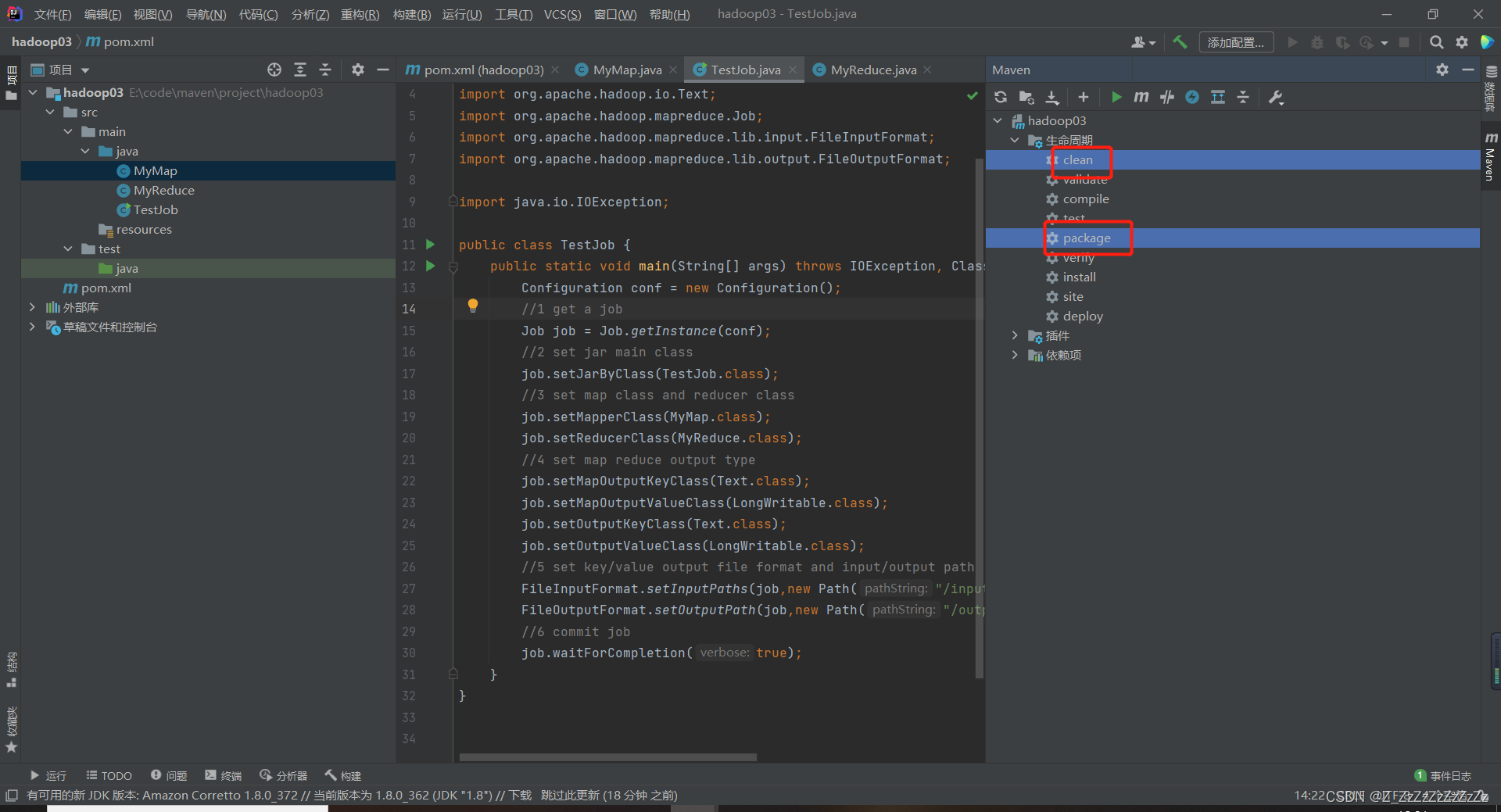
- target文件夹下会生成jar文件
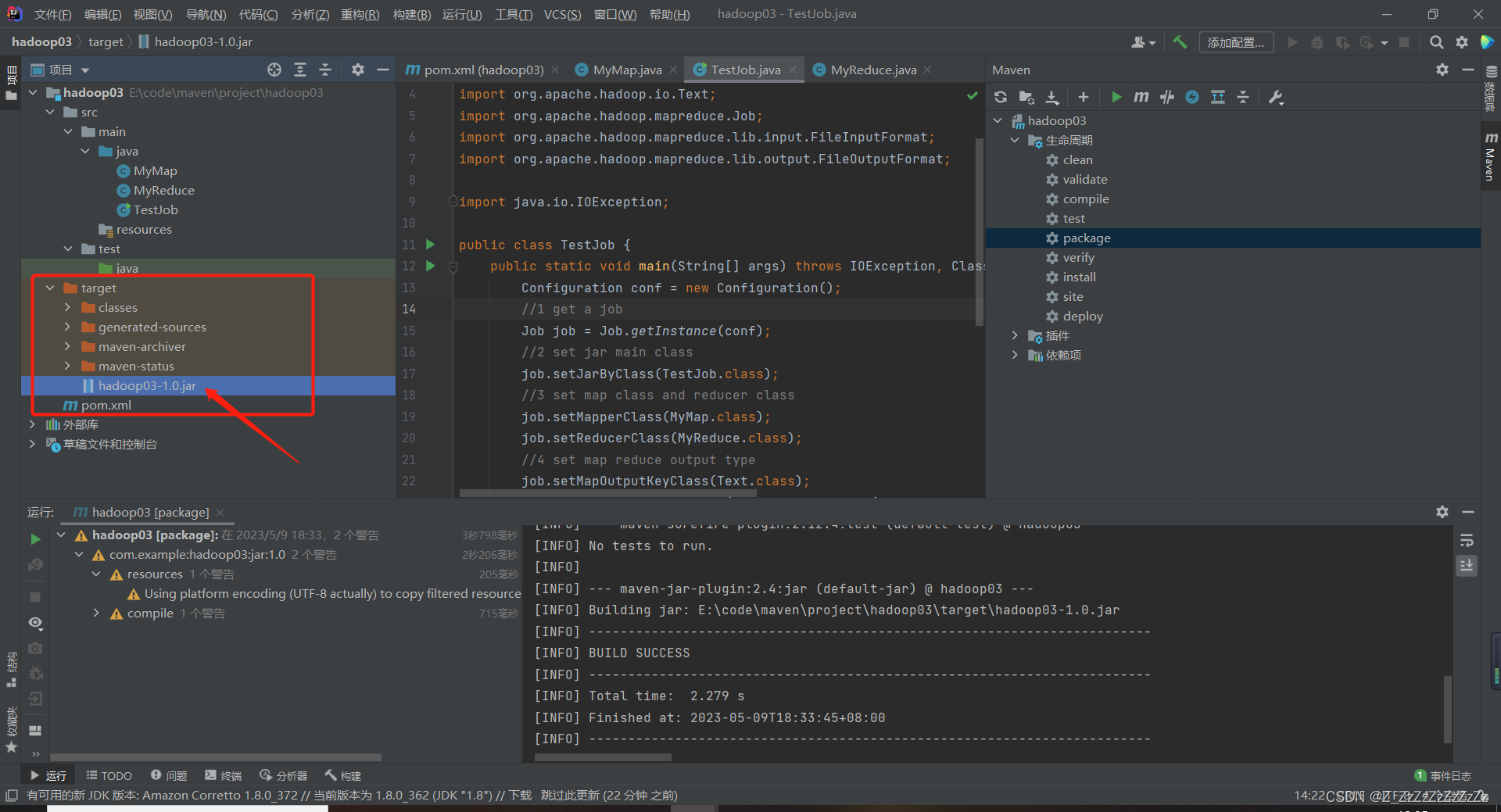
4.2(可选)jar包下载
- 提供本人生成的jar包,可下载
5.运行jar
5.1上传jar文件和input/word.txt至liunx
-
上传jar文件和input文件夹至liunx的/data/temp
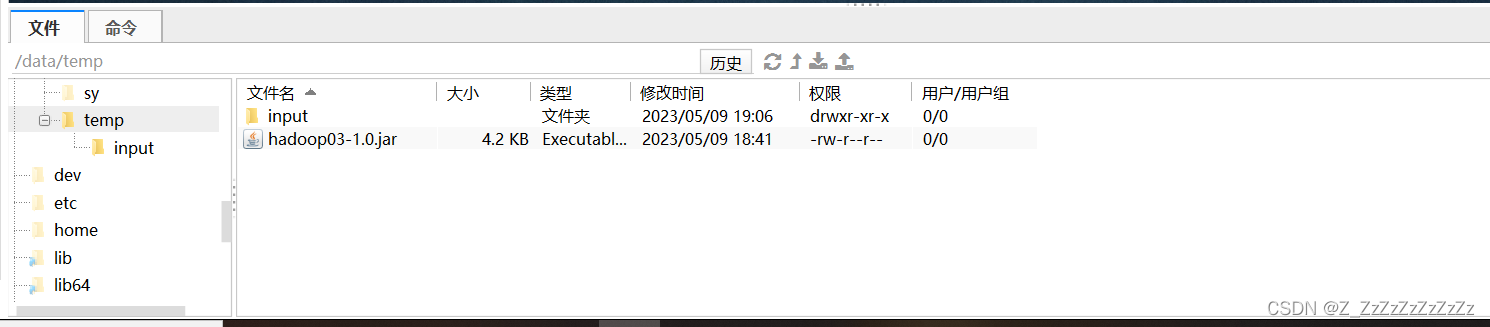
-
上传input至hdfs
hdfs dfs -put /data/temp/input /input
5.2运行jar
- 验证hdfs文件系统中没有output文件夹
hdfs dfs -ls /
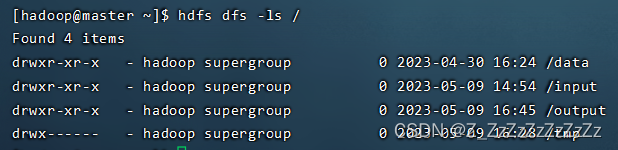
2. 如有/output文件夹,删除
hdfs dfs -rm -r /output
- 再次验证

4. 运行jar
hadoop jar /data/temp/hadoop03-1.0.jar TestJob
- 查看结果
hdfs dfs -cat /output/part-r-00000

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)