6.3 选择两个 UCI 数据集,分别用线性核和高斯核训练一个 SVM,并与BP 神经网络和 C4.5 决策树进行实验比较。
题目要求:6.3 选择两个 UCI 数据集,分别用线性核和高斯核训练一个 SVM,并与BP 神经网络和 C4.5 决策树进行实验比较。将数据库导入site-package文件夹后,可直接进行使用。使用sklearn自带的uci数据集进行测试,并打印展示。而后直接按照包的方法进行操作即可得到C4.5算法操作。使用sklearn的SVM进行训练,并打印训练结果。从github上下载了C4.5算法的数据
·
题目要求:6.3 选择两个 UCI 数据集,分别用线性核和高斯核训练一个 SVM,并与BP 神经网络和 C4.5 决策树进行实验比较。
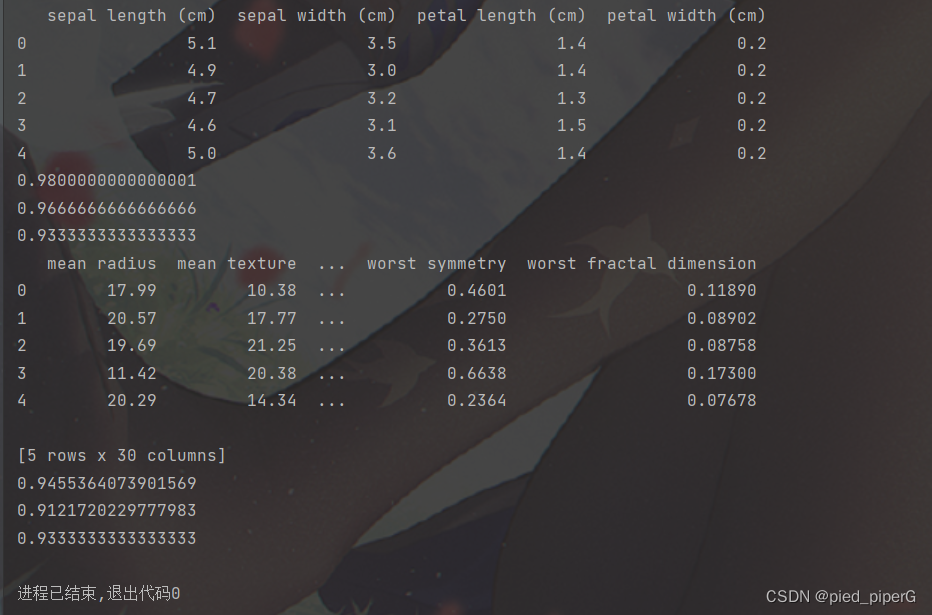
运行结果如下:

全部代码如下:
# 导入库
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import KFold, train_test_split, cross_val_score, cross_validate
from sklearn import svm, tree, model_selection, metrics, preprocessing
from c45 import C45
# 读入第一组数据
iris = datasets.load_iris()
X = pd.DataFrame(iris['data'], columns=iris['feature_names'])
y = pd.Series(iris['target_names'][iris['target']])
# 数据样例展示
print(X.head())
# 训练线性核SVM
linear_svm = svm.SVC(C=1, kernel='linear')
linear_scores = cross_validate(linear_svm, X, y, cv=5, scoring='accuracy')
print(linear_scores['test_score'].mean()) # 训练结果
# 训练高斯核SVM
rbf_svm = svm.SVC(C=1, kernel='rbf')
rbf_scores = cross_validate(rbf_svm, X, y, cv=5, scoring='accuracy')
print(rbf_scores['test_score'].mean()) # 训练结果
# C4.5算法
clf = C45(attrNames=iris.feature_names)
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.5)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 读入第二组数据
bre_c = datasets.load_breast_cancer()
X = pd.DataFrame(bre_c['data'], columns=bre_c['feature_names'])
y = pd.Series(bre_c['target_names'][bre_c['target']])
# 数据样例展示
print(X.head())
# 训练线性核SVM
linear_svm = svm.SVC(C=1, kernel='linear')
linear_scores = cross_validate(linear_svm, X, y, cv=5, scoring='accuracy')
print(linear_scores['test_score'].mean()) # 训练结果
# 训练高斯核SVM
rbf_svm = svm.SVC(C=1, kernel='rbf')
rbf_scores = cross_validate(rbf_svm, X, y, cv=5, scoring='accuracy')
print(rbf_scores['test_score'].mean()) # 训练结果
# C4.5算法
clf = C45(attrNames=bre_c.feature_names)
X_train, X_test, y_train, y_test = train_test_split(bre_c.data, bre_c.target, test_size=0.5)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
程序解释说明:
数据导入
使用sklearn自带的uci数据集进行测试,并打印展示
# 读入第一组数据
iris = datasets.load_iris()
X = pd.DataFrame(iris['data'], columns=iris['feature_names'])
y = pd.Series(iris['target_names'][iris['target']])
# 数据样例展示
print(X.head())线性核和高斯核
使用sklearn的SVM进行训练,并打印训练结果
# 训练线性核SVM
linear_svm = svm.SVC(C=1, kernel='linear')
linear_scores = cross_validate(linear_svm, X, y, cv=5, scoring='accuracy')
print(linear_scores['test_score'].mean()) # 训练结果
# 训练高斯核SVM
rbf_svm = svm.SVC(C=1, kernel='rbf')
rbf_scores = cross_validate(rbf_svm, X, y, cv=5, scoring='accuracy')
print(rbf_scores['test_score'].mean()) # 训练结果C4.5算法
从github上下载了C4.5算法的数据库
https://github.com/RaczeQ/scikit-learn-C4.5-tree-classifier

将数据库导入site-package文件夹后,可直接进行使用。
这里给出其中实现算法的代码
import math
from xml.dom import minidom
from xml.etree import ElementTree as ET
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_array, check_is_fitted, check_X_y
from .c45_utils import decision, grow_tree
class C45(BaseEstimator, ClassifierMixin):
"""A C4.5 tree classifier.
Parameters
----------
attrNames : list, optional (default=None)
The list of feature names used in printing tree during. If left default,
attributes will be named attr0, attr1... etc
See also
--------
DecisionTreeClassifier
References
----------
.. [1] https://en.wikipedia.org/wiki/Decision_tree_learning
.. [2] https://en.wikipedia.org/wiki/C4.5_algorithm
.. [3] L. Breiman, J. Friedman, R. Olshen, and C. Stone, "Classification
and Regression Trees", Wadsworth, Belmont, CA, 1984.
.. [4] J. R. Quinlain, "C4.5: Programs for Machine Learning",
Morgan Kaufmann Publishers, 1993
Examples
--------
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import cross_val_score
>>> from c45 import C45
>>> iris = load_iris()
>>> clf = C45(attrNames=iris.feature_names)
>>> cross_val_score(clf, iris.data, iris.target, cv=10)
... # doctest: +SKIP
...
array([ 1. , 0.93..., 0.86..., 0.93..., 0.93...,
0.93..., 0.93..., 1. , 0.93..., 1. ])
"""
def __init__(self, attrNames=None):
if attrNames is not None:
attrNames = [''.join(i for i in x if i.isalnum()).replace(' ', '_') for x in attrNames]
self.attrNames = attrNames
def fit(self, X, y):
X, y = check_X_y(X, y)
self.X_ = X
self.y_ = y
self.resultType = type(y[0])
if self.attrNames is None:
self.attrNames = [f'attr{x}' for x in range(len(self.X_[0]))]
assert(len(self.attrNames) == len(self.X_[0]))
data = [[] for i in range(len(self.attrNames))]
categories = []
for i in range(len(self.X_)):
categories.append(str(self.y_[i]))
for j in range(len(self.attrNames)):
data[j].append(self.X_[i][j])
root = ET.Element('DecisionTree')
grow_tree(data,categories,root,self.attrNames)
self.tree_ = ET.tostring(root, encoding="unicode")
return self
def predict(self, X):
check_is_fitted(self, ['tree_', 'resultType', 'attrNames'])
X = check_array(X)
dom = minidom.parseString(self.tree_)
root = dom.childNodes[0]
prediction = []
for i in range(len(X)):
answerlist = decision(root,X[i],self.attrNames,1)
answerlist = sorted(answerlist.items(), key=lambda x:x[1], reverse = True )
answer = answerlist[0][0]
prediction.append((self.resultType)(answer))
return prediction
def printTree(self):
check_is_fitted(self, ['tree_'])
dom = minidom.parseString(self.tree_)
print(dom.toprettyxml(newl="\r\n"))
而后直接按照包的方法进行操作即可得到C4.5算法操作。
# C4.5算法
clf = C45(attrNames=iris.feature_names)
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.5)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)