
杰克逊跳舞秒变3D机器人!阿里又出新活儿,视频任何人可替换
白交 发自 凹非寺量子位 | 公众号 QbitAI人形机器人跳舞复刻杰克逊,竟一点不逊色??这究竟是怎么回事?原来啊,阿里又整出新活儿——MotionShop,能将视频中的人物角色替换成3D形象,同时又不改变其他场景和人物。比如,打工仔小猪打太极。虚拟偶像跳Kpop女团舞。看到这有人已经迫不及待了。目前已在ModelScope社区开放试玩。还有人建议说在HuggingFace也安排一下,不然不懂中
白交 发自 凹非寺
量子位 | 公众号 QbitAI
人形机器人跳舞复刻杰克逊,竟一点不逊色??
这究竟是怎么回事?
原来啊,阿里又整出新活儿——
MotionShop,能将视频中的人物角色替换成3D形象,同时又不改变其他场景和人物。
比如,打工仔小猪打太极。
虚拟偶像跳Kpop女团舞。
看到这有人已经迫不及待了。目前已在ModelScope社区开放试玩。
还有人建议说在HuggingFace也安排一下,不然不懂中文的人怎么办啊~
不过确实承认,最近阿里的花活好多。
可免费试玩
目前MotionShop可以免费试玩,只需三步即可完成:
上传视频——确定目标对象——选择要替换的虚拟对象。
不过实测的时候发现,需要注意几点。
首先上传这个视频,不能超过15秒,最好保证人物完整,而且也不能是剪辑而成。
换句话说,需要一镜到底,切换镜头就不行。
随后选择替换人物时,它会自动选择一个对象,然后看是否符合你的目标对象。
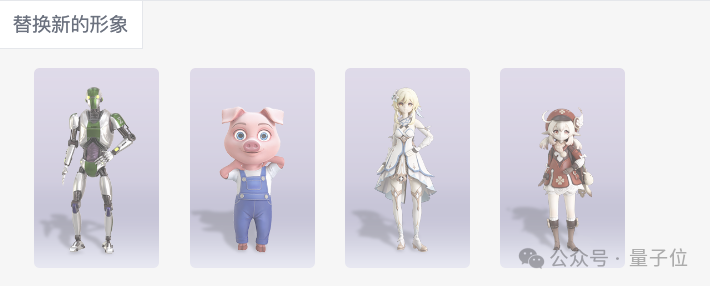
目前可替换的虚拟形象只有四个。
最后就是比较漫长的排队等待时间……试用的人太多了吧。
如何实现?
来自阿里的研究团队提出了用3D人物替换视频中角色的框架。
整个框架由两部分组成:
1、用于提取修复背景视频序列的视频处理管线;
2、用于生成3D人物视频的序列的姿态估计和渲染管线。
通过并行两条管线并使用高性能的光线追踪渲染器TIDE,整个过程能在
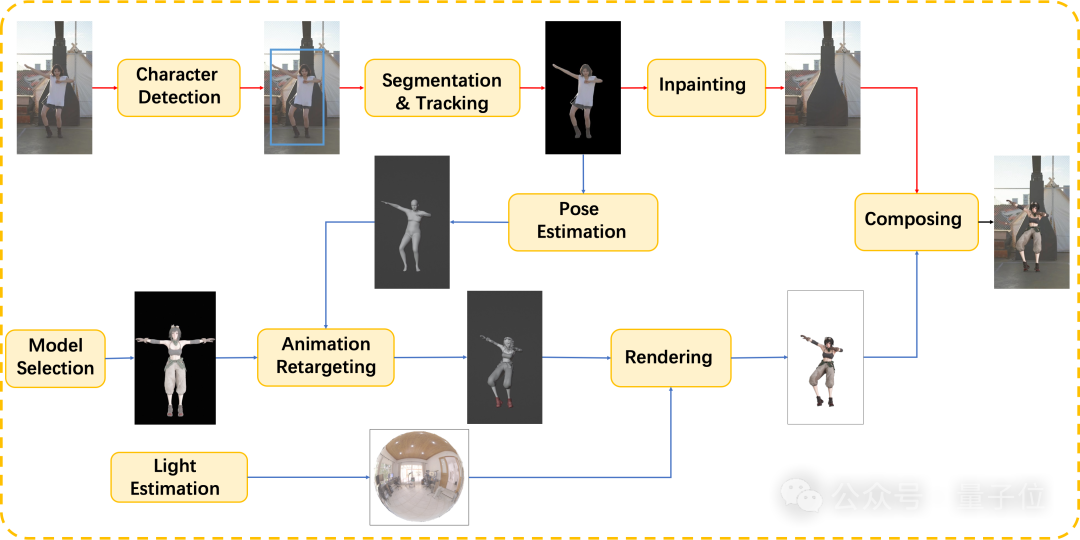
具体分为七个步骤。
第一步,角色检测。使用基于Transformer融合文本信息与现有封闭集检测器,实现零样本对象检测。通过优势选择方法确定最终目标区域。
第二步,分割与追踪。成功检测到目标后,通过视频对象分割跟踪方法来像素级跟踪目标区域,这一方法是基于SAM模型的细化升级。
第三步,修补。视频剩下区域进行修补绘制。包括采用了递归流完成法来恢复损坏的流场,在图像域和特征域都采用了双域传播法来增强全局和局部的时间一致性。
第四步,姿态估计。采用姿态估计方法 CVFFS 来估计稳定的人体姿态。使用 SMPL 人体模型来表示三维人体。
第五步,3D人物生成。将估算出的形状和姿势重新映射到选定的三维模型上。
第六步,为了更自然真实的视觉效果,做进一步光线处理和渲染,让3D模型与原视频更融入。比如使用TIDE引擎来渲染新的 3D 模型。它与精确的材质系统相结合,并辅以运动模糊、时间抗锯齿和时间去噪等算法。
最后,将渲染图像与原始视频合成,生成最终视频。
感兴趣的朋友可戳下方链接:
https://modelscope.cn/studios/Damo_XR_Lab/motionshop/summary
参考链接:
https://aigc3d.github.io/motionshop/ https://twitter.com/_akhaliq/status/1747301955867639919
— 完 —
点这里👇关注我,记得标星哦~

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)