
简单了解Sqoop
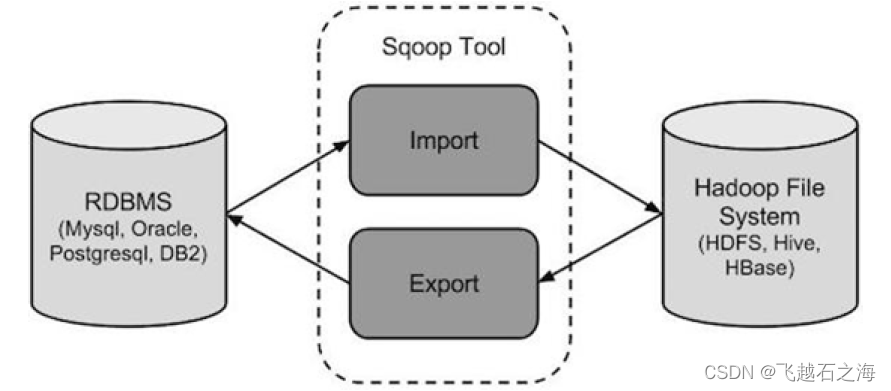
sqoop是一款开源工具,主要运用在Hadoop(Hive)与传统的数据库(mysql\postgresql等)间进行数据的传递;它最早是作为hadoop的一个第三方模块存在,后来为了让使用者能快速部署以及迭代开发,最后独立成为Apache项目;依赖于hadoop,数据并行写入;传递类型分为两种:1)import——MySQL导入到HDFS中;2)export——将HDFS的数据导出到关系型数据库
概述
sqoop是一款开源工具,主要运用在Hadoop(Hive)与传统的数据库(mysql\postgresql等)间进行数据的传递;
它最早是作为hadoop的一个第三方模块存在,后来为了让使用者能快速部署以及迭代开发,最后独立成为Apache项目;
依赖于hadoop,数据并行写入;
传递类型分为两种:
1)import——MySQL导入到HDFS中;
2)export——将HDFS的数据导出到关系型数据库中;
我们可以将导入或导命令翻译成MapReduce程序来实现,并且不需要reducetask,在其中主要针对inputformat和outformat进行定制。
数据导入
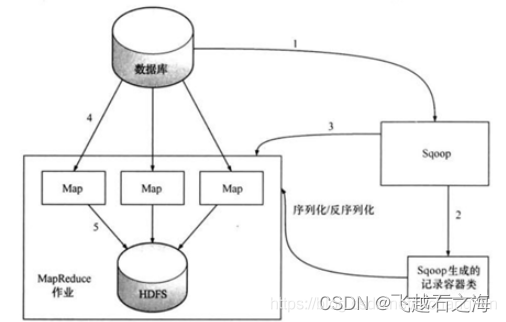
- sqoop会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。
- 这些数据库的数据类型会被映射成为java的数据类型,根据这些信息,sqoop会生成一个与表名相同的类用来完成序列化工作,保存表中的每一行记录。
- sqoop开启MapReduce作业 。
- 启动的作业在input的过程中,会通过jdbc读取数据表中的内容,这时,会使用sqoop生成的类进行序列化。
- 最后将这些记录写到hdfs上,在写入hdfs的过程中,同样会使用sqoop生成的类进行反序列化。
MySQL到HDFS
简单举例导入数据
基础思路:
- 需要指明是导入import;
- 之后必须指定所连接的数据库,其用户名和密码;
- 指定数据库表,最终目标路径,同时注意如果这个目录已经存在,先删除或者使用append参数,表示追加;
- 指定启动的maptask的个数;
- hdfs文件数据的分隔符。
在shell命令行实现
sqoop import \
--connect jdbc:mysql://hadoop102:3306/sqoop \
--username root \
--password 123456 \
--table goodtbl \
--target-dir /root/sqoop_hdfs \
--delete-target-dir \
-m 1 \
--fields-terminated-by "\t"
//如果需要导入查询数据
//两种方式
//1.使用query 不需要指定数据库表,sql语句中有
--query 'select col_name... from tbk_name where 筛选条件 and ¥CONDITIONS'
//查询语句中的where子句中必须包含'$CONDITIONS',也是为了数据分区使用,即使只有1个MapTask;
//若query后使用的是双引号,则$CONDITIONS前必须加转义符,也就是\$CONDITIONS,防止shell识别为自己的变量
//2.使用关键字where
--where "条件"
//需要导入指定列
--columns coln1,clon2...
//如果涉及多列,用逗号分隔,不能添加空格
//数据量很多的情况下,启动多个MapTask导入数据
//这时sqoop要对每个Task的数据进行分区
//1.MySQL中的表有主键 指定maptask的个数
//2.mysql中的表没有主键,使用split-by指定分区字段
--split-by col_name
//如果分区字段是字符类型,使用 sqoop 命令的时候要添加
//-Dorg.apache.sqoop.splitter.allow_text_splitter=true
sqoop import -
Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop102:3306/sqoop \
MySQL到Hive
举例理解
同样是指定和数据库连接的相关信息
sqoop import \
--connect jdbc:mysql://hadoop102:3306/sqoop \
--username root \
--password 123456 \
--table goodtbl \
-m 1 \
--fields-terminated-by "\t" //Hive字段分隔符
//在此基础上,添加hive相关参数
--hive-import //必须参数,指定导入hive
--hive-database //Hive库名 默认值default
--hive-table //hive表名
--hive-overwrite //覆盖已经存在的数据
--create-hive-table
//创建好hive表,但表可能存在错误,不建议使用该参数,可提前建好表
增量数据导入
前面都是执行的全量数据导入。如果数据量很小,则采取完全源数据抽取;如果源数据量很大,则需要抽取发生变化的数据,这种数据抽取模式叫做变化数据捕获,简称CDC(Change Data Capture)。
CDC分为两种方式
1.侵入式
指CDC操作会给源系统带来性能影响,只要CDC操作以任何一种方式对源数据库执行了SQL操作,就认为是侵入式的,反之就是非侵入式;
基于时间戳的CDC
抽取过程根据某些属性列来判断哪些数据是增量的
常见属性列2种
-
时间戳
一个插入时间戳,表示何时创建的;
一个更新时间戳,表示最后一次更新的时间; -
序列
大多数数据库都提供自增功能,表中的列定义成自增的,易根据该列识别新插入的数据;
简单常用,但是有缺点
不能记录删除记录的操作
无法识别多次更新
不具有实时能力
-
基于触发器的CDC
当执行INSERT、UPDATE、DELETE这些SQL语句时,激活数据库里的触发器,使用触发器捕获变更数据,并把数据保存在中间临时表里。然后这些变更数据再从临时表取出;
大多数场合下,不允许向操作型数据库里添加触发器,且这种方法会降低系统性能,基本不会被采用。 -
基于快照的CDC
可以通过比较源表和快照(数据存储的某一时刻的状态记录)表来获得数据变化
优点:基于快照的CDC可以检测到插入、更新和删除的数据,相对于基于时间戳的CDC的优点;
缺点:需要大量存储空间来保存快照;
2.非侵入式
基于日志的CDC
最复杂的和没有侵入性的CDC方法是基于日志的方式;
数据库会把每个插入、更新、删除操作记录到日志里。解析日志文件,就可以获取相关信息;
每个关系型数据库日志格式不一致,没有通用的产品。
阿里巴巴的canal可以完成MySQL日志文件解析。
sqoop实现时间戳CDC的方式有两种
1)Append (基于递增列的增量数据导入)
2)LastModified方式(基于时间列的数据增量导入)
这里简单介绍append方式
准备好初始数据开始导入到hive
//参考上述导入到hive的基本格式
//因为需要指定列区判断数据是否作为增量数据进行导入
--incremental append \ //增量导入
--check-column serialNumber \
//被指定的列的类型不能使任意字符类型,如char、varchar等类型都不可以
--last-value 0 \
//给定上次导入索引的最后值,在导入新数据的时候从最后值的下一个记录开始导入
这里每次都需要手动配置last-value,为了方便我们可以给定job,定时任务每天定时调度;
步骤如下
//创建口令文件
echo -n "12345678" > sqoopPWD.pwd
hdfs dfs -mkdir -p /sqoop/pwd
hdfs dfs -put sqoopPWD.pwd /sqoop/pwd
hdfs dfs -chmod 400 /sqoop/pwd/sqoopPWD.pwd
# 可以在 sqoop 的 job 中增加:
--password-file /sqoop/pwd/sqoopPWD.pwd
//创建 sqoop job
sqoop job --create myjob1 -- import \
--connect jdbc:mysql://linux123:3306/sqoop?useSSL=false \
--username hive \
--password-file /sqoop/pwd/sqoopPWD.pwd \
--table goodtbl \
--incremental append \
--hive-import \
--hive-table mydb.goodtbl \
--check-column serialNucmber \
--last-value 0 \
-m 1
//查看已创建的job
sqoop job --list
//查看job详细运行是参数
sqoop job --show myjob1
//执行job
sqoop job --exec myjob1
//删除job
sqoop job --delete myjob1
//最后查看数据对比
其实现原理是因为job执行完成后,会把当前check-column的最大值记录到meta中,下次再调起时把此值赋给last-value;
//缺省情况下元数据保存在 ~/.sqoop/
//其中,metastore.db.script 文件记录了对last-value的更新操作
cat metastore.db.script |grep incremental.last.value
数据导出
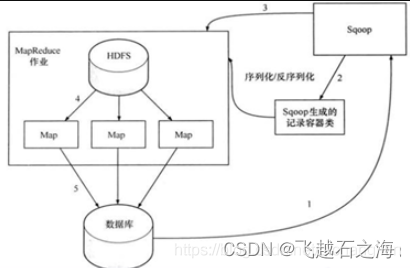
- 首先sqoop通过jdbc访问关系型数据库,得到需要导出的数据的元数据信息。
- 根据获取的元数据信息,sqoop生成一个java类,用来进行数据的传输载体,该类必须实现序列化。
- 启动MapReduce程序。
- sqoop利用生成的这个java类,并行的从hdfs中读取数据。
- 每一个map作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批的insert语句然后多个 map 作业会并行的向数据库 mysql 中插入数据。
- Hive/HDFS到RDBMS
注意:MySQL表需要提前创建
执行导出
sqoop export \
--connect jdbc:mysql://hadoop102:3306/sqoop \
--username root \
--password 123456 \
--table goodtbl2 \
--num-mappers 1 \
//到数据库的默认路径
--export-dir
/user/hive/warehouse/mydb.db/goodtbl \
//和import不同,export字段之间的分隔符命令如下
--input-fields-terminated-by "\t"
参考:
1.Sqoop的介绍(导入导出原理)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)